 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Large Language Models for Time-Series Forecasting via Vector-Injected In-Context Learning
Jan 12, 2026The World Wide Web needs reliable predictive capabilities to respond to changes in user behavior and usage patterns. Time series forecasting (TSF) is a key means to achieve this goal. In recent years, the large language models (LLMs) for TSF (LLM4TSF) have achieved good performance. However, there is a significant difference between pretraining corpora and time series data, making it hard to guarantee forecasting quality when directly applying LLMs to TSF; fine-tuning LLMs can mitigate this issue, but often incurs substantial computational overhead. Thus, LLM4TSF faces a dual challenge of prediction performance and compute overhead. To address this, we aim to explore a method for improving the forecasting performance of LLM4TSF while freezing all LLM parameters to reduce computational overhead. Inspired by in-context learning (ICL), we propose LVICL. LVICL uses our vector-injected ICL to inject example information into a frozen LLM, eliciting its in-context learning ability and thereby enhancing its performance on the example-related task (i.e., TSF). Specifically, we first use the LLM together with a learnable context vector adapter to extract a context vector from multiple examples adaptively. This vector contains compressed, example-related information. Subsequently, during the forward pass, we inject this vector into every layer of the LLM to improve forecasting performance. Compared with conventional ICL that adds examples into the prompt, our vector-injected ICL does not increase prompt length; moreover, adaptively deriving a context vector from examples suppresses components harmful to forecasting, thereby improving model performance. Extensive experiments demonstrate the effectiveness of our approach.
Exploring Transferability of Self-Supervised Learning by Task Conflict Calibration
Nov 16, 2025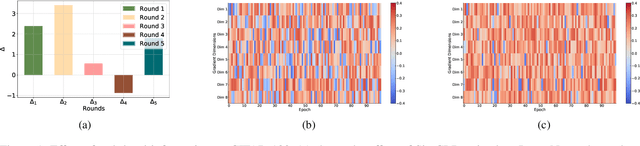
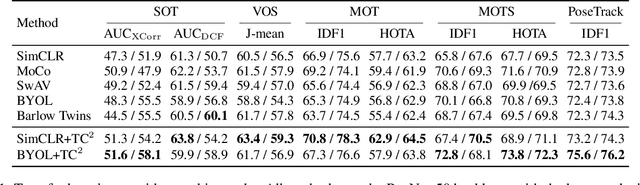
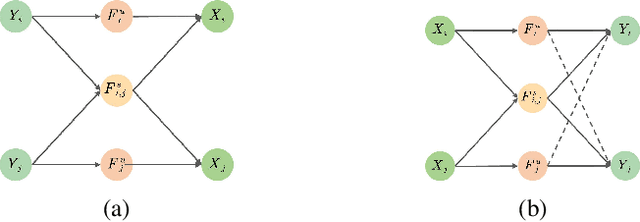
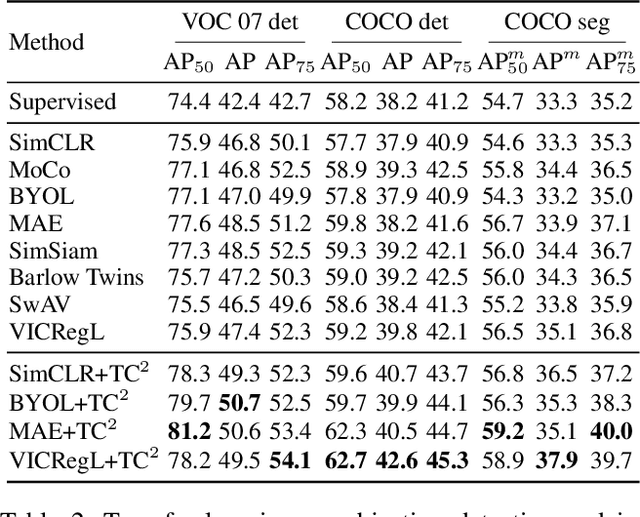
In this paper, we explore the transferability of SSL by addressing two central questions: (i) what is the representation transferability of SSL, and (ii) how can we effectively model this transferability? Transferability is defined as the ability of a representation learned from one task to support the objective of another. Inspired by the meta-learning paradigm, we construct multiple SSL tasks within each training batch to support explicitly modeling transferability. Based on empirical evidence and causal analysis, we find that although introducing task-level information improves transferability, it is still hindered by task conflict. To address this issue, we propose a Task Conflict Calibration (TC$^2$) method to alleviate the impact of task conflict. Specifically, it first splits batches to create multiple SSL tasks, infusing task-level information. Next, it uses a factor extraction network to produce causal generative factors for all tasks and a weight extraction network to assign dedicated weights to each sample, employing data reconstruction, orthogonality, and sparsity to ensure effectiveness. Finally, TC$^2$ calibrates sample representations during SSL training and integrates into the pipeline via a two-stage bi-level optimization framework to boost the transferability of learned representations. Experimental results on multiple downstream tasks demonstrate that our method consistently improves the transferability of SSL models.
Group Causal Policy Optimization for Post-Training Large Language Models
Aug 07, 2025Recent advances in large language models (LLMs) have broadened their applicability across diverse tasks, yet specialized domains still require targeted post training. Among existing methods, Group Relative Policy Optimization (GRPO) stands out for its efficiency, leveraging groupwise relative rewards while avoiding costly value function learning. However, GRPO treats candidate responses as independent, overlooking semantic interactions such as complementarity and contradiction. To address this challenge, we first introduce a Structural Causal Model (SCM) that reveals hidden dependencies among candidate responses induced by conditioning on a final integrated output forming a collider structure. Then, our causal analysis leads to two insights: (1) projecting responses onto a causally informed subspace improves prediction quality, and (2) this projection yields a better baseline than query only conditioning. Building on these insights, we propose Group Causal Policy Optimization (GCPO), which integrates causal structure into optimization through two key components: a causally informed reward adjustment and a novel KL regularization term that aligns the policy with a causally projected reference distribution. Comprehensive experimental evaluations demonstrate that GCPO consistently surpasses existing methods, including GRPO across multiple reasoning benchmarks.
Hacking Hallucinations of MLLMs with Causal Sufficiency and Necessity
Aug 06, 2025



Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities across vision-language tasks. However, they may suffer from hallucinations--generating outputs that are semantically inconsistent with the input image or text. Through causal analyses, we find that: (i) hallucinations with omission may arise from the failure to adequately capture essential causal factors, and (ii) hallucinations with fabrication are likely caused by the model being misled by non-causal cues. To address these challenges, we propose a novel reinforcement learning framework guided by causal completeness, which jointly considers both causal sufficiency and causal necessity of tokens. Specifically, we evaluate each token's standalone contribution and counterfactual indispensability to define a token-level causal completeness reward. This reward is used to construct a causally informed advantage function within the GRPO optimization framework, encouraging the model to focus on tokens that are both causally sufficient and necessary for accurate generation. Experimental results across various benchmark datasets and tasks demonstrate the effectiveness of our approach, which effectively mitigates hallucinations in MLLMs.
Advancing Complex Wide-Area Scene Understanding with Hierarchical Coresets Selection
Jul 17, 2025Scene understanding is one of the core tasks in computer vision, aiming to extract semantic information from images to identify objects, scene categories, and their interrelationships. Although advancements in Vision-Language Models (VLMs) have driven progress in this field, existing VLMs still face challenges in adaptation to unseen complex wide-area scenes. To address the challenges, this paper proposes a Hierarchical Coresets Selection (HCS) mechanism to advance the adaptation of VLMs in complex wide-area scene understanding. It progressively refines the selected regions based on the proposed theoretically guaranteed importance function, which considers utility, representativeness, robustness, and synergy. Without requiring additional fine-tuning, HCS enables VLMs to achieve rapid understandings of unseen scenes at any scale using minimal interpretable regions while mitigating insufficient feature density. HCS is a plug-and-play method that is compatible with any VLM. Experiments demonstrate that HCS achieves superior performance and universality in various tasks.
Multi-Modal Learning with Bayesian-Oriented Gradient Calibration
May 29, 2025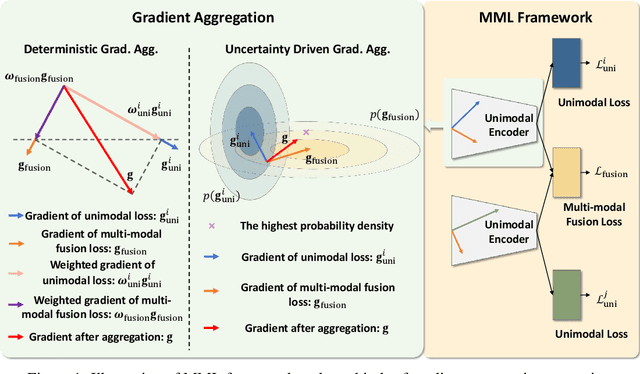
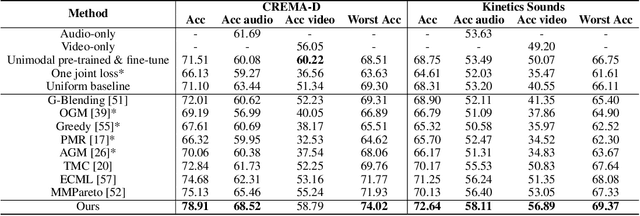
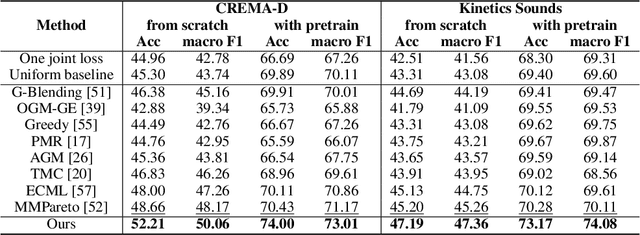
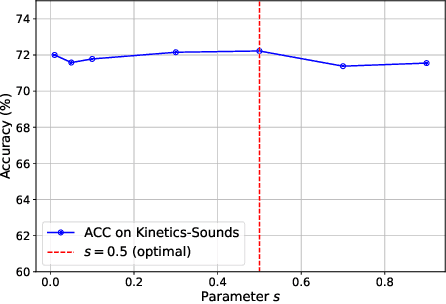
Multi-Modal Learning (MML) integrates information from diverse modalities to improve predictive accuracy. However, existing methods mainly aggregate gradients with fixed weights and treat all dimensions equally, overlooking the intrinsic gradient uncertainty of each modality. This may lead to (i) excessive updates in sensitive dimensions, degrading performance, and (ii) insufficient updates in less sensitive dimensions, hindering learning. To address this issue, we propose BOGC-MML, a Bayesian-Oriented Gradient Calibration method for MML to explicitly model the gradient uncertainty and guide the model optimization towards the optimal direction. Specifically, we first model each modality's gradient as a random variable and derive its probability distribution, capturing the full uncertainty in the gradient space. Then, we propose an effective method that converts the precision (inverse variance) of each gradient distribution into a scalar evidence. This evidence quantifies the confidence of each modality in every gradient dimension. Using these evidences, we explicitly quantify per-dimension uncertainties and fuse them via a reduced Dempster-Shafer rule. The resulting uncertainty-weighted aggregation produces a calibrated update direction that balances sensitivity and conservatism across dimensions. Extensive experiments on multiple benchmark datasets demonstrate the effectiveness and advantages of the proposed method.
Learning to Think: Information-Theoretic Reinforcement Fine-Tuning for LLMs
May 15, 2025Large language models (LLMs) excel at complex tasks thanks to advances in reasoning abilities. However, existing methods overlook the trade-off between reasoning effectiveness and computational efficiency, often encouraging unnecessarily long reasoning chains and wasting tokens. To address this, we propose Learning to Think (L2T), an information-theoretic reinforcement fine-tuning framework for LLMs to make the models achieve optimal reasoning with fewer tokens. Specifically, L2T treats each query-response interaction as a hierarchical session of multiple episodes and proposes a universal dense process reward, i.e., quantifies the episode-wise information gain in parameters, requiring no extra annotations or task-specific evaluators. We propose a method to quickly estimate this reward based on PAC-Bayes bounds and the Fisher information matrix. Theoretical analyses show that it significantly reduces computational complexity with high estimation accuracy. By immediately rewarding each episode's contribution and penalizing excessive updates, L2T optimizes the model via reinforcement learning to maximize the use of each episode and achieve effective updates. Empirical results on various reasoning benchmarks and base models demonstrate the advantage of L2T across different tasks, boosting both reasoning effectiveness and efficiency.
Causal Prompt Calibration Guided Segment Anything Model for Open-Vocabulary Multi-Entity Segmentation
May 10, 2025Despite the strength of the Segment Anything Model (SAM), it struggles with generalization issues in open-vocabulary multi-entity segmentation (OVMS). Through empirical and causal analyses, we find that (i) the prompt bias is the primary cause of the generalization issues; (ii) this bias is closely tied to the task-irrelevant generating factors within the prompts, which act as confounders and affect generalization. To address the generalization issues, we aim to propose a method that can calibrate prompts to eliminate confounders for accurate OVMS. Building upon the causal analysis, we propose that the optimal prompt for OVMS should contain only task-relevant causal factors. We define it as the causal prompt, serving as the goal of calibration. Next, our theoretical analysis, grounded by causal multi-distribution consistency theory, proves that this prompt can be obtained by enforcing segmentation consistency and optimality. Inspired by this, we propose CPC-SAM, a Causal Prompt Calibration method for SAM to achieve accurate OVMS. It integrates a lightweight causal prompt learner (CaPL) into SAM to obtain causal prompts. Specifically, we first generate multiple prompts using random annotations to simulate diverse distributions and then reweight them via CaPL by enforcing causal multi-distribution consistency in both task and entity levels. To ensure obtaining causal prompts, CaPL is optimized by minimizing the cumulative segmentation loss across the reweighted prompts to achieve consistency and optimality. A bi-level optimization strategy alternates between optimizing CaPL and SAM, ensuring accurate OVMS. Extensive experiments validate its superiority.
Enhancing Time Series Forecasting via Logic-Inspired Regularization
Mar 10, 2025Time series forecasting (TSF) plays a crucial role in many applications. Transformer-based methods are one of the mainstream techniques for TSF. Existing methods treat all token dependencies equally. However, we find that the effectiveness of token dependencies varies across different forecasting scenarios, and existing methods ignore these differences, which affects their performance. This raises two issues: (1) What are effective token dependencies? (2) How can we learn effective dependencies? From a logical perspective, we align Transformer-based TSF methods with the logical framework and define effective token dependencies as those that ensure the tokens as atomic formulas (Issue 1). We then align the learning process of Transformer methods with the process of obtaining atomic formulas in logic, which inspires us to design a method for learning these effective dependencies (Issue 2). Specifically, we propose Attention Logic Regularization (Attn-L-Reg), a plug-and-play method that guides the model to use fewer but more effective dependencies by making the attention map sparse, thereby ensuring the tokens as atomic formulas and improving prediction performance. Extensive experiments and theoretical analysis confirm the effectiveness of Attn-L-Reg.
Spatio-Temporal Fuzzy-oriented Multi-Modal Meta-Learning for Fine-grained Emotion Recognition
Dec 18, 2024Fine-grained emotion recognition (FER) plays a vital role in various fields, such as disease diagnosis, personalized recommendations, and multimedia mining. However, existing FER methods face three key challenges in real-world applications: (i) they rely on large amounts of continuously annotated data to ensure accuracy since emotions are complex and ambiguous in reality, which is costly and time-consuming; (ii) they cannot capture the temporal heterogeneity caused by changing emotion patterns, because they usually assume that the temporal correlation within sampling periods is the same; (iii) they do not consider the spatial heterogeneity of different FER scenarios, that is, the distribution of emotion information in different data may have bias or interference. To address these challenges, we propose a Spatio-Temporal Fuzzy-oriented Multi-modal Meta-learning framework (ST-F2M). Specifically, ST-F2M first divides the multi-modal videos into multiple views, and each view corresponds to one modality of one emotion. Multiple randomly selected views for the same emotion form a meta-training task. Next, ST-F2M uses an integrated module with spatial and temporal convolutions to encode the data of each task, reflecting the spatial and temporal heterogeneity. Then it adds fuzzy semantic information to each task based on generalized fuzzy rules, which helps handle the complexity and ambiguity of emotions. Finally, ST-F2M learns emotion-related general meta-knowledge through meta-recurrent neural networks to achieve fast and robust fine-grained emotion recognition. Extensive experiments show that ST-F2M outperforms various state-of-the-art methods in terms of accuracy and model efficiency. In addition, we construct ablation studies and further analysis to explore why ST-F2M performs well.