 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Large Language Models for Time-Series Forecasting via Vector-Injected In-Context Learning
Jan 12, 2026The World Wide Web needs reliable predictive capabilities to respond to changes in user behavior and usage patterns. Time series forecasting (TSF) is a key means to achieve this goal. In recent years, the large language models (LLMs) for TSF (LLM4TSF) have achieved good performance. However, there is a significant difference between pretraining corpora and time series data, making it hard to guarantee forecasting quality when directly applying LLMs to TSF; fine-tuning LLMs can mitigate this issue, but often incurs substantial computational overhead. Thus, LLM4TSF faces a dual challenge of prediction performance and compute overhead. To address this, we aim to explore a method for improving the forecasting performance of LLM4TSF while freezing all LLM parameters to reduce computational overhead. Inspired by in-context learning (ICL), we propose LVICL. LVICL uses our vector-injected ICL to inject example information into a frozen LLM, eliciting its in-context learning ability and thereby enhancing its performance on the example-related task (i.e., TSF). Specifically, we first use the LLM together with a learnable context vector adapter to extract a context vector from multiple examples adaptively. This vector contains compressed, example-related information. Subsequently, during the forward pass, we inject this vector into every layer of the LLM to improve forecasting performance. Compared with conventional ICL that adds examples into the prompt, our vector-injected ICL does not increase prompt length; moreover, adaptively deriving a context vector from examples suppresses components harmful to forecasting, thereby improving model performance. Extensive experiments demonstrate the effectiveness of our approach.
Causal Prompt Calibration Guided Segment Anything Model for Open-Vocabulary Multi-Entity Segmentation
May 10, 2025Despite the strength of the Segment Anything Model (SAM), it struggles with generalization issues in open-vocabulary multi-entity segmentation (OVMS). Through empirical and causal analyses, we find that (i) the prompt bias is the primary cause of the generalization issues; (ii) this bias is closely tied to the task-irrelevant generating factors within the prompts, which act as confounders and affect generalization. To address the generalization issues, we aim to propose a method that can calibrate prompts to eliminate confounders for accurate OVMS. Building upon the causal analysis, we propose that the optimal prompt for OVMS should contain only task-relevant causal factors. We define it as the causal prompt, serving as the goal of calibration. Next, our theoretical analysis, grounded by causal multi-distribution consistency theory, proves that this prompt can be obtained by enforcing segmentation consistency and optimality. Inspired by this, we propose CPC-SAM, a Causal Prompt Calibration method for SAM to achieve accurate OVMS. It integrates a lightweight causal prompt learner (CaPL) into SAM to obtain causal prompts. Specifically, we first generate multiple prompts using random annotations to simulate diverse distributions and then reweight them via CaPL by enforcing causal multi-distribution consistency in both task and entity levels. To ensure obtaining causal prompts, CaPL is optimized by minimizing the cumulative segmentation loss across the reweighted prompts to achieve consistency and optimality. A bi-level optimization strategy alternates between optimizing CaPL and SAM, ensuring accurate OVMS. Extensive experiments validate its superiority.
Enhancing Time Series Forecasting via Logic-Inspired Regularization
Mar 10, 2025Time series forecasting (TSF) plays a crucial role in many applications. Transformer-based methods are one of the mainstream techniques for TSF. Existing methods treat all token dependencies equally. However, we find that the effectiveness of token dependencies varies across different forecasting scenarios, and existing methods ignore these differences, which affects their performance. This raises two issues: (1) What are effective token dependencies? (2) How can we learn effective dependencies? From a logical perspective, we align Transformer-based TSF methods with the logical framework and define effective token dependencies as those that ensure the tokens as atomic formulas (Issue 1). We then align the learning process of Transformer methods with the process of obtaining atomic formulas in logic, which inspires us to design a method for learning these effective dependencies (Issue 2). Specifically, we propose Attention Logic Regularization (Attn-L-Reg), a plug-and-play method that guides the model to use fewer but more effective dependencies by making the attention map sparse, thereby ensuring the tokens as atomic formulas and improving prediction performance. Extensive experiments and theoretical analysis confirm the effectiveness of Attn-L-Reg.
Let Human Sketches Help: Empowering Challenging Image Segmentation Task with Freehand Sketches
Jan 31, 2025



Sketches, with their expressive potential, allow humans to convey the essence of an object through even a rough contour. For the first time, we harness this expressive potential to improve segmentation performance in challenging tasks like camouflaged object detection (COD). Our approach introduces an innovative sketch-guided interactive segmentation framework, allowing users to intuitively annotate objects with freehand sketches (drawing a rough contour of the object) instead of the traditional bounding boxes or points used in classic interactive segmentation models like SAM. We demonstrate that sketch input can significantly improve performance in existing iterative segmentation methods, outperforming text or bounding box annotations. Additionally, we introduce key modifications to network architectures and a novel sketch augmentation technique to fully harness the power of sketch input and further boost segmentation accuracy. Remarkably, our model' s output can be directly used to train other neural networks, achieving results comparable to pixel-by-pixel annotations--while reducing annotation time by up to 120 times, which shows great potential in democratizing the annotation process and enabling model training with less reliance on resource-intensive, laborious pixel-level annotations. We also present KOSCamo+, the first freehand sketch dataset for camouflaged object detection. The dataset, code, and the labeling tool will be open sourced.
Magic3DSketch: Create Colorful 3D Models From Sketch-Based 3D Modeling Guided by Text and Language-Image Pre-Training
Jul 27, 2024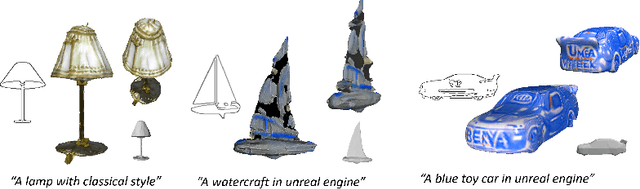
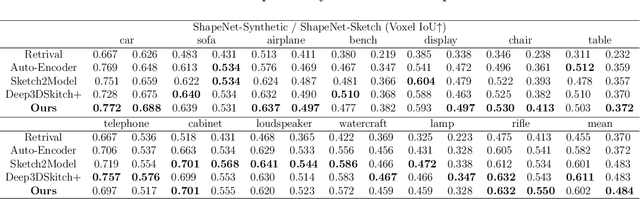
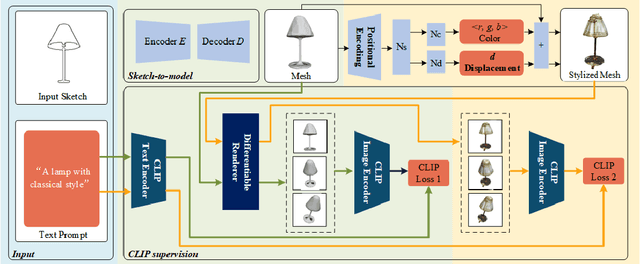
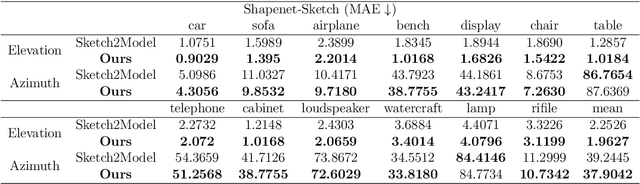
The requirement for 3D content is growing as AR/VR application emerges. At the same time, 3D modelling is only available for skillful experts, because traditional methods like Computer-Aided Design (CAD) are often too labor-intensive and skill-demanding, making it challenging for novice users. Our proposed method, Magic3DSketch, employs a novel technique that encodes sketches to predict a 3D mesh, guided by text descriptions and leveraging external prior knowledge obtained through text and language-image pre-training. The integration of language-image pre-trained neural networks complements the sparse and ambiguous nature of single-view sketch inputs. Our method is also more useful and offers higher degree of controllability compared to existing text-to-3D approaches, according to our user study. Moreover, Magic3DSketch achieves state-of-the-art performance in both synthetic and real dataset with the capability of producing more detailed structures and realistic shapes with the help of text input. Users are also more satisfied with models obtained by Magic3DSketch according to our user study. Additionally, we are also the first, to our knowledge, add color based on text description to the sketch-derived shapes. By combining sketches and text guidance with the help of language-image pretrained models, our Magic3DSketch can allow novice users to create custom 3D models with minimal effort and maximum creative freedom, with the potential to revolutionize future 3D modeling pipelines.
Not All Frequencies Are Created Equal:Towards a Dynamic Fusion of Frequencies in Time-Series Forecasting
Jul 18, 2024



Long-term time series forecasting is a long-standing challenge in various applications. A central issue in time series forecasting is that methods should expressively capture long-term dependency. Furthermore, time series forecasting methods should be flexible when applied to different scenarios. Although Fourier analysis offers an alternative to effectively capture reusable and periodic patterns to achieve long-term forecasting in different scenarios, existing methods often assume high-frequency components represent noise and should be discarded in time series forecasting. However, we conduct a series of motivation experiments and discover that the role of certain frequencies varies depending on the scenarios. In some scenarios, removing high-frequency components from the original time series can improve the forecasting performance, while in others scenarios, removing them is harmful to forecasting performance. Therefore, it is necessary to treat the frequencies differently according to specific scenarios. To achieve this, we first reformulate the time series forecasting problem as learning a transfer function of each frequency in the Fourier domain. Further, we design Frequency Dynamic Fusion (FreDF), which individually predicts each Fourier component, and dynamically fuses the output of different frequencies. Moreover, we provide a novel insight into the generalization ability of time series forecasting and propose the generalization bound of time series forecasting. Then we prove FreDF has a lower bound, indicating that FreDF has better generalization ability. Extensive experiments conducted on multiple benchmark datasets and ablation studies demonstrate the effectiveness of FreDF.
Reasoning3D -- Grounding and Reasoning in 3D: Fine-Grained Zero-Shot Open-Vocabulary 3D Reasoning Part Segmentation via Large Vision-Language Models
May 29, 2024In this paper, we introduce a new task: Zero-Shot 3D Reasoning Segmentation for parts searching and localization for objects, which is a new paradigm to 3D segmentation that transcends limitations for previous category-specific 3D semantic segmentation, 3D instance segmentation, and open-vocabulary 3D segmentation. We design a simple baseline method, Reasoning3D, with the capability to understand and execute complex commands for (fine-grained) segmenting specific parts for 3D meshes with contextual awareness and reasoned answers for interactive segmentation. Specifically, Reasoning3D leverages an off-the-shelf pre-trained 2D segmentation network, powered by Large Language Models (LLMs), to interpret user input queries in a zero-shot manner. Previous research have shown that extensive pre-training endows foundation models with prior world knowledge, enabling them to comprehend complex commands, a capability we can harness to "segment anything" in 3D with limited 3D datasets (source efficient). Experimentation reveals that our approach is generalizable and can effectively localize and highlight parts of 3D objects (in 3D mesh) based on implicit textual queries, including these articulated 3d objects and real-world scanned data. Our method can also generate natural language explanations corresponding to these 3D models and the decomposition. Moreover, our training-free approach allows rapid deployment and serves as a viable universal baseline for future research of part-level 3d (semantic) object understanding in various fields including robotics, object manipulation, part assembly, autonomous driving applications, augment reality and virtual reality (AR/VR), and medical applications. The code, the model weight, the deployment guide, and the evaluation protocol are: http://tianrun-chen.github.io/Reason3D/
Intriguing Properties of Positional Encoding in Time Series Forecasting
Apr 16, 2024Transformer-based methods have made significant progress in time series forecasting (TSF). They primarily handle two types of tokens, i.e., temporal tokens that contain all variables of the same timestamp, and variable tokens that contain all input time points for a specific variable. Transformer-based methods rely on positional encoding (PE) to mark tokens' positions, facilitating the model to perceive the correlation between tokens. However, in TSF, research on PE remains insufficient. To address this gap, we conduct experiments and uncover intriguing properties of existing PEs in TSF: (i) The positional information injected by PEs diminishes as the network depth increases; (ii) Enhancing positional information in deep networks is advantageous for improving the model's performance; (iii) PE based on the similarity between tokens can improve the model's performance. Motivated by these findings, we introduce two new PEs: Temporal Position Encoding (T-PE) for temporal tokens and Variable Positional Encoding (V-PE) for variable tokens. Both T-PE and V-PE incorporate geometric PE based on tokens' positions and semantic PE based on the similarity between tokens but using different calculations. To leverage both the PEs, we design a Transformer-based dual-branch framework named T2B-PE. It first calculates temporal tokens' correlation and variable tokens' correlation respectively and then fuses the dual-branch features through the gated unit. Extensive experiments demonstrate the superior robustness and effectiveness of T2B-PE. The code is available at: \href{https://github.com/jlu-phyComputer/T2B-PE}{https://github.com/jlu-phyComputer/T2B-PE}.