 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAMD: Coverage-Aware Multimodal Decoding for Efficient Reasoning of Multimodal Large Language Models
Mar 16, 2026Recent advances in Multimodal Large Language Models (MLLMs) have shown impressive reasoning capabilities across vision-language tasks, yet still face the challenge of compute-difficulty mismatch. Through empirical analyses, we identify that existing decoding methods may waste compute on easy cases while underserving hard ones, affecting both model effectiveness and efficiency. To address this issue, we first develop a theoretical framework that links sampling coverage, instance difficulty, and residual risk. Our analysis reveals that multimodal reasoning exhibits a heavy-tailed difficulty distribution; a small subset of hard or ambiguous samples dominates the residual failure probability. Based on this insight, we propose Coverage-Aware Multimodal Decoding (CAMD), an adaptive inference mechanism that dynamically allocates computation according to estimated uncertainty. CAMD integrates evidence-weighted scoring, posterior coverage estimation, and sequential Bayesian updating to balance efficiency and reliability under a limited token budget. Experiments on various benchmark datasets and baselines demonstrate the effectiveness and advantages of our approach.
Towards Generalizable Reasoning: Group Causal Counterfactual Policy Optimization for LLM Reasoning
Feb 06, 2026Large language models (LLMs) excel at complex tasks with advances in reasoning capabilities. However, existing reward mechanisms remain tightly coupled to final correctness and pay little attention to the underlying reasoning process: trajectories with sound reasoning but wrong answers receive low credit, while lucky guesses with flawed logic may be highly rewarded, affecting reasoning generalization. From a causal perspective, we interpret multi-candidate reasoning for a fixed question as a family of counterfactual experiments with theoretical supports. Building on this, we propose Group Causal Counterfactual Policy Optimization to explicitly train LLMs to learn generalizable reasoning patterns. It proposes an episodic causal counterfactual reward that jointly captures (i) robustness, encouraging the answer distribution induced by a reasoning step to remain stable under counterfactual perturbations; and (ii) effectiveness, enforcing sufficient variability so that the learned reasoning strategy can transfer across questions. We then construct token-level advantages from this reward and optimize the policy, encouraging LLMs to favor reasoning patterns that are process-valid and counterfactually robust. Extensive experiments on diverse benchmarks demonstrate its advantages.
Exploring Transferability of Self-Supervised Learning by Task Conflict Calibration
Nov 16, 2025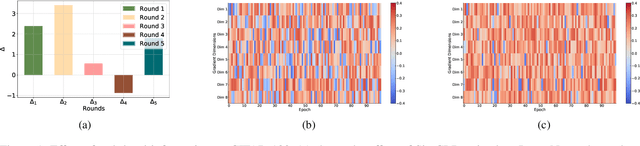
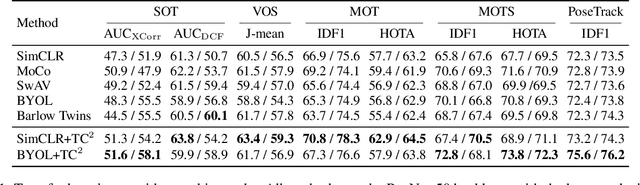
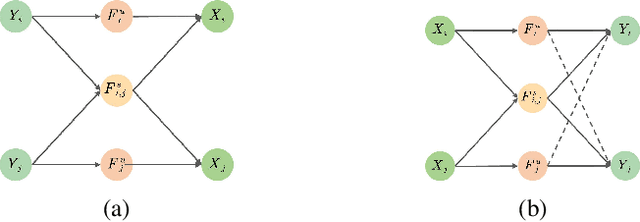
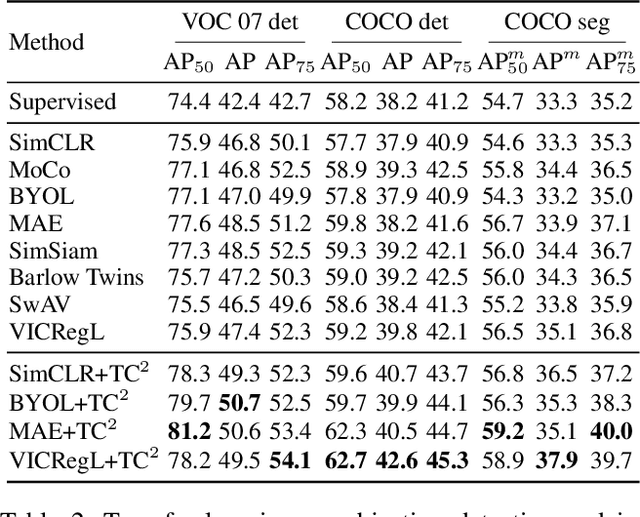
In this paper, we explore the transferability of SSL by addressing two central questions: (i) what is the representation transferability of SSL, and (ii) how can we effectively model this transferability? Transferability is defined as the ability of a representation learned from one task to support the objective of another. Inspired by the meta-learning paradigm, we construct multiple SSL tasks within each training batch to support explicitly modeling transferability. Based on empirical evidence and causal analysis, we find that although introducing task-level information improves transferability, it is still hindered by task conflict. To address this issue, we propose a Task Conflict Calibration (TC$^2$) method to alleviate the impact of task conflict. Specifically, it first splits batches to create multiple SSL tasks, infusing task-level information. Next, it uses a factor extraction network to produce causal generative factors for all tasks and a weight extraction network to assign dedicated weights to each sample, employing data reconstruction, orthogonality, and sparsity to ensure effectiveness. Finally, TC$^2$ calibrates sample representations during SSL training and integrates into the pipeline via a two-stage bi-level optimization framework to boost the transferability of learned representations. Experimental results on multiple downstream tasks demonstrate that our method consistently improves the transferability of SSL models.
Causal Reward Adjustment: Mitigating Reward Hacking in External Reasoning via Backdoor Correction
Aug 06, 2025External reasoning systems combine language models with process reward models (PRMs) to select high-quality reasoning paths for complex tasks such as mathematical problem solving. However, these systems are prone to reward hacking, where high-scoring but logically incorrect paths are assigned high scores by the PRMs, leading to incorrect answers. From a causal inference perspective, we attribute this phenomenon primarily to the presence of confounding semantic features. To address it, we propose Causal Reward Adjustment (CRA), a method that mitigates reward hacking by estimating the true reward of a reasoning path. CRA trains sparse autoencoders on the PRM's internal activations to recover interpretable features, then corrects confounding by using backdoor adjustment. Experiments on math solving datasets demonstrate that CRA mitigates reward hacking and improves final accuracy, without modifying the policy model or retraining PRM.
Hacking Hallucinations of MLLMs with Causal Sufficiency and Necessity
Aug 06, 2025



Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities across vision-language tasks. However, they may suffer from hallucinations--generating outputs that are semantically inconsistent with the input image or text. Through causal analyses, we find that: (i) hallucinations with omission may arise from the failure to adequately capture essential causal factors, and (ii) hallucinations with fabrication are likely caused by the model being misled by non-causal cues. To address these challenges, we propose a novel reinforcement learning framework guided by causal completeness, which jointly considers both causal sufficiency and causal necessity of tokens. Specifically, we evaluate each token's standalone contribution and counterfactual indispensability to define a token-level causal completeness reward. This reward is used to construct a causally informed advantage function within the GRPO optimization framework, encouraging the model to focus on tokens that are both causally sufficient and necessary for accurate generation. Experimental results across various benchmark datasets and tasks demonstrate the effectiveness of our approach, which effectively mitigates hallucinations in MLLMs.
Multi-Modal Learning with Bayesian-Oriented Gradient Calibration
May 29, 2025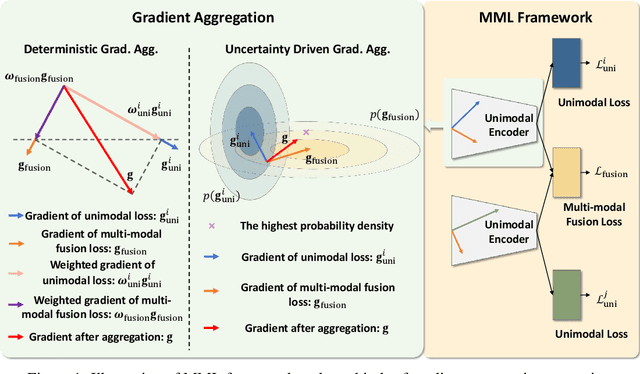
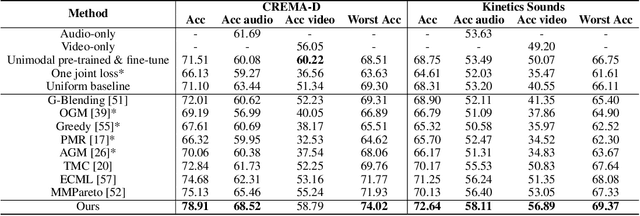
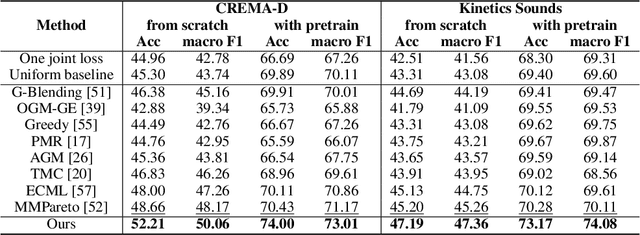
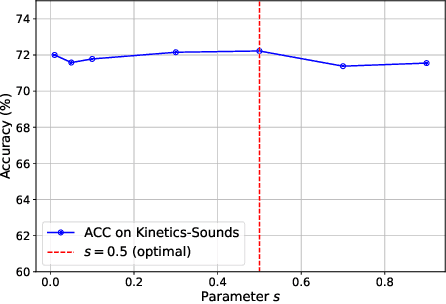
Multi-Modal Learning (MML) integrates information from diverse modalities to improve predictive accuracy. However, existing methods mainly aggregate gradients with fixed weights and treat all dimensions equally, overlooking the intrinsic gradient uncertainty of each modality. This may lead to (i) excessive updates in sensitive dimensions, degrading performance, and (ii) insufficient updates in less sensitive dimensions, hindering learning. To address this issue, we propose BOGC-MML, a Bayesian-Oriented Gradient Calibration method for MML to explicitly model the gradient uncertainty and guide the model optimization towards the optimal direction. Specifically, we first model each modality's gradient as a random variable and derive its probability distribution, capturing the full uncertainty in the gradient space. Then, we propose an effective method that converts the precision (inverse variance) of each gradient distribution into a scalar evidence. This evidence quantifies the confidence of each modality in every gradient dimension. Using these evidences, we explicitly quantify per-dimension uncertainties and fuse them via a reduced Dempster-Shafer rule. The resulting uncertainty-weighted aggregation produces a calibrated update direction that balances sensitivity and conservatism across dimensions. Extensive experiments on multiple benchmark datasets demonstrate the effectiveness and advantages of the proposed method.
CAIFormer: A Causal Informed Transformer for Multivariate Time Series Forecasting
May 22, 2025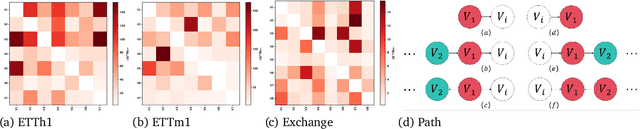

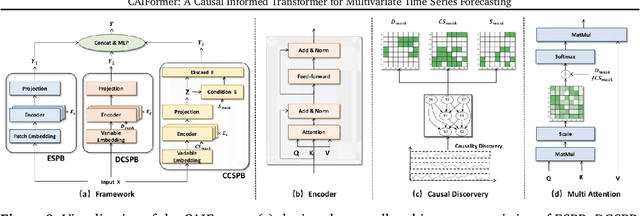

Most existing multivariate time series forecasting methods adopt an all-to-all paradigm that feeds all variable histories into a unified model to predict their future values without distinguishing their individual roles. However, this undifferentiated paradigm makes it difficult to identify variable-specific causal influences and often entangles causally relevant information with spurious correlations. To address this limitation, we propose an all-to-one forecasting paradigm that predicts each target variable separately. Specifically, we first construct a Structural Causal Model from observational data and then, for each target variable, we partition the historical sequence into four sub-segments according to the inferred causal structure: endogenous, direct causal, collider causal, and spurious correlation. The prediction relies solely on the first three causally relevant sub-segments, while the spurious correlation sub-segment is excluded. Furthermore, we propose Causal Informed Transformer (CAIFormer), a novel forecasting model comprising three components: Endogenous Sub-segment Prediction Block, Direct Causal Sub-segment Prediction Block, and Collider Causal Sub-segment Prediction Block, which process the endogenous, direct causal, and collider causal sub-segments, respectively. Their outputs are then combined to produce the final prediction. Extensive experiments on multiple benchmark datasets demonstrate the effectiveness of the CAIFormer.
Neuromodulated Meta-Learning
Nov 11, 2024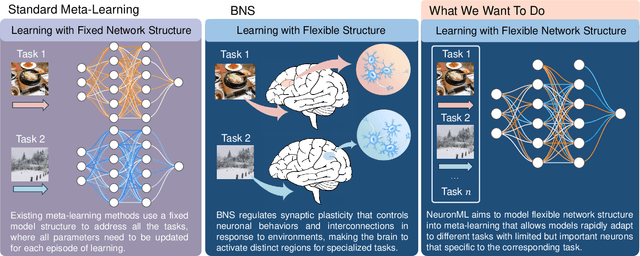

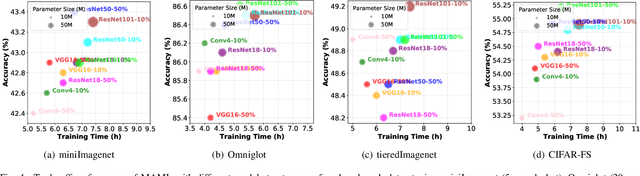
Humans excel at adapting perceptions and actions to diverse environments, enabling efficient interaction with the external world. This adaptive capability relies on the biological nervous system (BNS), which activates different brain regions for distinct tasks. Meta-learning similarly trains machines to handle multiple tasks but relies on a fixed network structure, not as flexible as BNS. To investigate the role of flexible network structure (FNS) in meta-learning, we conduct extensive empirical and theoretical analyses, finding that model performance is tied to structure, with no universally optimal pattern across tasks. This reveals the crucial role of FNS in meta-learning, ensuring meta-learning to generate the optimal structure for each task, thereby maximizing the performance and learning efficiency of meta-learning. Motivated by this insight, we propose to define, measure, and model FNS in meta-learning. First, we define that an effective FNS should possess frugality, plasticity, and sensitivity. Then, to quantify FNS in practice, we present three measurements for these properties, collectively forming the \emph{structure constraint} with theoretical supports. Building on this, we finally propose Neuromodulated Meta-Learning (NeuronML) to model FNS in meta-learning. It utilizes bi-level optimization to update both weights and structure with the structure constraint. Extensive theoretical and empirical evaluations demonstrate the effectiveness of NeuronML on various tasks. Code is publicly available at \href{https://github.com/WangJingyao07/NeuronML}{https://github.com/WangJingyao07/NeuronML}.
Not All Frequencies Are Created Equal:Towards a Dynamic Fusion of Frequencies in Time-Series Forecasting
Jul 18, 2024



Long-term time series forecasting is a long-standing challenge in various applications. A central issue in time series forecasting is that methods should expressively capture long-term dependency. Furthermore, time series forecasting methods should be flexible when applied to different scenarios. Although Fourier analysis offers an alternative to effectively capture reusable and periodic patterns to achieve long-term forecasting in different scenarios, existing methods often assume high-frequency components represent noise and should be discarded in time series forecasting. However, we conduct a series of motivation experiments and discover that the role of certain frequencies varies depending on the scenarios. In some scenarios, removing high-frequency components from the original time series can improve the forecasting performance, while in others scenarios, removing them is harmful to forecasting performance. Therefore, it is necessary to treat the frequencies differently according to specific scenarios. To achieve this, we first reformulate the time series forecasting problem as learning a transfer function of each frequency in the Fourier domain. Further, we design Frequency Dynamic Fusion (FreDF), which individually predicts each Fourier component, and dynamically fuses the output of different frequencies. Moreover, we provide a novel insight into the generalization ability of time series forecasting and propose the generalization bound of time series forecasting. Then we prove FreDF has a lower bound, indicating that FreDF has better generalization ability. Extensive experiments conducted on multiple benchmark datasets and ablation studies demonstrate the effectiveness of FreDF.
Self-Supervised Representation Learning with Meta Comprehensive Regularization
Mar 03, 2024Self-Supervised Learning (SSL) methods harness the concept of semantic invariance by utilizing data augmentation strategies to produce similar representations for different deformations of the same input. Essentially, the model captures the shared information among multiple augmented views of samples, while disregarding the non-shared information that may be beneficial for downstream tasks. To address this issue, we introduce a module called CompMod with Meta Comprehensive Regularization (MCR), embedded into existing self-supervised frameworks, to make the learned representations more comprehensive. Specifically, we update our proposed model through a bi-level optimization mechanism, enabling it to capture comprehensive features. Additionally, guided by the constrained extraction of features using maximum entropy coding, the self-supervised learning model learns more comprehensive features on top of learning consistent features. In addition, we provide theoretical support for our proposed method from information theory and causal counterfactual perspective. Experimental results show that our method achieves significant improvement in classification, object detection and instance segmentation tasks on multiple benchmark datasets.