 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Model Generalization for Compute-Aware Test-Time Reasoning
May 23, 2025External test-time reasoning enhances large language models (LLMs) by decoupling generation and selection. At inference time, the model generates multiple reasoning paths, and an auxiliary process reward model (PRM) is used to score and select the best one. A central challenge in this setting is test-time compute optimality (TCO), i.e., how to maximize answer accuracy under a fixed inference budget. In this work, we establish a theoretical framework to analyze how the generalization error of the PRM affects compute efficiency and reasoning performance. Leveraging PAC-Bayes theory, we derive generalization bounds and show that a lower generalization error of PRM leads to fewer samples required to find correct answers. Motivated by this analysis, we propose Compute-Aware Tree Search (CATS), an actor-critic framework that dynamically controls search behavior. The actor outputs sampling hyperparameters based on reward distributions and sparsity statistics, while the critic estimates their utility to guide budget allocation. Experiments on the MATH and AIME benchmarks with various LLMs and PRMs demonstrate that CATS consistently outperforms other external TTS methods, validating our theoretical predictions.
CAIFormer: A Causal Informed Transformer for Multivariate Time Series Forecasting
May 22, 2025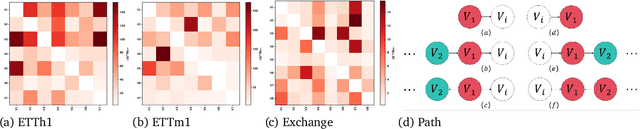

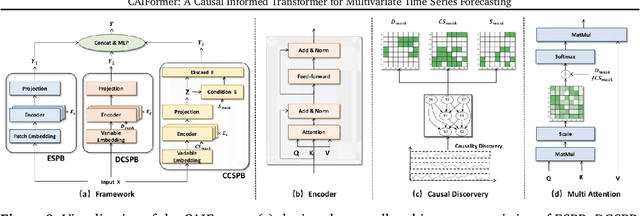

Most existing multivariate time series forecasting methods adopt an all-to-all paradigm that feeds all variable histories into a unified model to predict their future values without distinguishing their individual roles. However, this undifferentiated paradigm makes it difficult to identify variable-specific causal influences and often entangles causally relevant information with spurious correlations. To address this limitation, we propose an all-to-one forecasting paradigm that predicts each target variable separately. Specifically, we first construct a Structural Causal Model from observational data and then, for each target variable, we partition the historical sequence into four sub-segments according to the inferred causal structure: endogenous, direct causal, collider causal, and spurious correlation. The prediction relies solely on the first three causally relevant sub-segments, while the spurious correlation sub-segment is excluded. Furthermore, we propose Causal Informed Transformer (CAIFormer), a novel forecasting model comprising three components: Endogenous Sub-segment Prediction Block, Direct Causal Sub-segment Prediction Block, and Collider Causal Sub-segment Prediction Block, which process the endogenous, direct causal, and collider causal sub-segments, respectively. Their outputs are then combined to produce the final prediction. Extensive experiments on multiple benchmark datasets demonstrate the effectiveness of the CAIFormer.
Not All Frequencies Are Created Equal:Towards a Dynamic Fusion of Frequencies in Time-Series Forecasting
Jul 18, 2024



Long-term time series forecasting is a long-standing challenge in various applications. A central issue in time series forecasting is that methods should expressively capture long-term dependency. Furthermore, time series forecasting methods should be flexible when applied to different scenarios. Although Fourier analysis offers an alternative to effectively capture reusable and periodic patterns to achieve long-term forecasting in different scenarios, existing methods often assume high-frequency components represent noise and should be discarded in time series forecasting. However, we conduct a series of motivation experiments and discover that the role of certain frequencies varies depending on the scenarios. In some scenarios, removing high-frequency components from the original time series can improve the forecasting performance, while in others scenarios, removing them is harmful to forecasting performance. Therefore, it is necessary to treat the frequencies differently according to specific scenarios. To achieve this, we first reformulate the time series forecasting problem as learning a transfer function of each frequency in the Fourier domain. Further, we design Frequency Dynamic Fusion (FreDF), which individually predicts each Fourier component, and dynamically fuses the output of different frequencies. Moreover, we provide a novel insight into the generalization ability of time series forecasting and propose the generalization bound of time series forecasting. Then we prove FreDF has a lower bound, indicating that FreDF has better generalization ability. Extensive experiments conducted on multiple benchmark datasets and ablation studies demonstrate the effectiveness of FreDF.
Learning Invariant Causal Mechanism from Vision-Language Models
May 24, 2024



Pre-trained large-scale models have become a major research focus, but their effectiveness is limited in real-world applications due to diverse data distributions. In contrast, humans excel at decision-making across various domains by learning reusable knowledge that remains invariant despite environmental changes in a complex world. Although CLIP, as a successful vision-language pre-trained model, demonstrates remarkable performance in various visual downstream tasks, our experiments reveal unsatisfactory results in specific domains. Our further analysis with causal inference exposes the current CLIP model's inability to capture the invariant causal mechanisms across domains, attributed to its deficiency in identifying latent factors generating the data. To address this, we propose the Invariant Causal Mechanism of CLIP (CLIP-ICM), an algorithm designed to provably identify invariant latent factors with the aid of interventional data, and perform accurate prediction on various domains. Theoretical analysis demonstrates that our method has a lower generalization bound in out-of-distribution (OOD) scenarios. Experimental results showcase the outstanding performance of CLIP-ICM.