 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiological Reasoning-Informed Regression for Interpretable Regulatory DNA Activity Prediction
Jun 06, 2026DNA cis-regulatory elements (CREs) such as enhancers control gene expression levels. Accurately predicting regulatory activity from DNA sequences is valuable but challenging, as it requires understanding complex biological regulatory processes. Existing methods typically regress activity scores from sequences in a black-box manner, limiting both interpretability and regression performance. Meanwhile, large language models (LLMs) benefit from explicit reasoning processes, yet directly applying LLMs to raw DNA sequences performs poorly. In this paper, we bridge this gap by introducing R3LM, a framework that teaches LLMs reasoning-informed regression on regulatory DNA through structured biological knowledge. Specifically, we design a biologically grounded data format that structures DNA's regulatory information for improved LLM understanding, and construct CRE-ReasonBench, the first dataset that associates DNA sequences and activity scores with mechanistic reasoning traces. Through two-stage training that first teaches LLMs reasoning over structured biological information then performs regression, R3LM achieves state-of-the-art performance on enhancer prediction across three cell types, outperforming both LLMs with raw sequence input and specialized DNA models while providing interpretable mechanistic explanations. We expect R3LM as an interpretable reward model that can effectively assist biologists in CRE design. Code is available at https://github.com/DuanYi516/R3LM.
Qwen-Image-Bench: From Generation to Creation in Text-to-Image Evaluation
May 27, 2026Text-to-Image generation has evolved from basic image synthesis into a frequently used core capability in professional creative workflows, where simple text-image alignment can no longer satisfy users' pressing demands for faithful real-world reconstruction and genuine creative expression. Existing benchmarks, however, remain anchored in these foundational criteria and do not yet capture the nuanced capabilities that matter in authentic artistic practice, making it difficult to reliably distinguish state-of-the-art T2I models. To address the gap, we introduce Qwen-Image-Bench, a creator-centric benchmark co-designed with professional artists and grounded in real-world creation scenarios. Qwen-Image-Bench enriches conventional evaluation with two application-driven dimensions: Real-world Fidelity and Creative Generation. Drawing on the staged reasoning inherent in professional artistic workflows, we organize these five pillars into a top-down hierarchical taxonomy that further decomposes into 23 second-level sub-capabilities and 56 third-level verifiable rubrics. To ensure broad coverage, we curate 1000 stratified prompts with each prompt jointly exercising more than four fine-grained facets across multiple pillars. We train a unified judge model Q-Judger based on Qwen3.6-27B, supervised by 80 professional annotators from global art academies under blind labeling and triple-review protocols, that scores every image across all 56 verifiable facets, producing fine-grained, rubric-grounded, and fully attributable diagnostics rather than a single opaque score. Empirically, Qwen-Image-Bench reliably distinguishes leading T2I models, achieving the greatest separation on the two application-driven dimensions of Real-world Fidelity and Creative Generation where existing benchmarks provide little insight, while also providing a trustworthy optimization signal for production-level T2I development.
Pareto-Guided Optimal Transport for Multi-Reward Alignment
May 13, 2026Text-to-image generation models have achieved remarkable progress in preference optimization, yet achieving robust alignment across diverse reward models remains a significant challenge. Existing multi-reward fusion approaches rely on weighted summation, which is costly to tune and insufficient for balancing conflicting objectives. More critically, optimization with reward models is highly susceptible to reward hacking, where reward scores increase while the perceived quality of generated images deteriorates. We demonstrate that optimizing against a unified global target under heterogeneous reward upper bounds can induce reward hacking, a risk further exacerbated by the inherent instability of weak reward models. To mitigate this, we propose a Pareto Frontier-Guided Optimal Transport (PG-OT) framework. Our method constructs a prompt-specific Pareto frontier and maps dominated samples toward it via distribution-aware optimal transport. Furthermore, we develop both online and offline optimization strategies tailored to diverse reward signal characteristics. To provide a more rigorous assessment, we introduce the Joint Domination Rate (JDR) and Joint Collapse Rate (JCR) as principled metrics to quantify multi-reward synergy and reward hacking. Experimental results show that our approach outperforms strong baselines with an 11% gain in JDR and achieves a near 80% win rate in human evaluations.
SyncDPO: Enhancing Temporal Synchronization in Video-Audio Joint Generation via Preference Learning
May 12, 2026Recent advancements in video-audio joint generation have achieved remarkable success in semantic correspondence. However, achieving precise temporal synchronization, which requires fine-grained alignment between audio events and their visual triggers, remains a challenging problem. The post-training method for joint generation is largely dominated by Supervised Fine-Tuning, but the commonly used Mean Squared Error loss provides insufficient penalties for subtle temporal misalignments. Direct Preference Optimization offers an alternative by introducing explicit misaligned counterparts to better improve temporal sensitivity. In this paper we propose a post-training framework SyncDPO, leveraging DPO to improve the temporal sensitivity of V-A joint generation. Conventional DPO pipelines typically depend on costly sampling-and-ranking procedures to construct preference pairs, resulting in substantial computational cost. To improve efficiency, we introduce a suite of on-the-fly rule-based negative construction strategies that distort temporal structures without incurring additional annotation or sampling. We demonstrate that the temporal alignment capability can be effectively reinforced by providing explicit negative supervision through temporally distorted V-A pairs. Accordingly, we implement a curriculum learning strategy that progressively increases the difficulty of negative samples, transitioning from coarse misalignment to subtle inconsistencies. Extensive objective and subjective experiments across four diverse benchmarks, ranging from ambient sound videos to human speech videos, demonstrate that SyncDPO significantly outperforms other methods in improving model's temporal alignment capability. It also demonstrates superior generalization on out-of-distribution benchmark by capturing intrinsic motion-sound dynamics. Demo and code is available in https://syncdpo.github.io/syncdpo/.
Qwen-Image-2.0 Technical Report
May 11, 2026We present Qwen-Image-2.0, an omni-capable image generation foundation model that unifies high-fidelity generation and precise image editing within a single framework. Despite recent progress, existing models still struggle with ultra-long text rendering, multilingual typography, high-resolution photorealism, robust instruction following, and efficient deployment, especially in text-rich and compositionally complex scenarios. Qwen-Image-2.0 addresses these challenges by coupling Qwen3-VL as the condition encoder with a Multimodal Diffusion Transformer for joint condition-target modeling, supported by large-scale data curation and a customized multi-stage training pipeline. This enables strong multimodal understanding while preserving flexible generation and editing capabilities. The model supports instructions of up to 1K tokens for generating text-rich content such as slides, posters, infographics, and comics, while significantly improving multilingual text fidelity and typography. It also enhances photorealistic generation with richer details, more realistic textures, and coherent lighting, and follows complex prompts more reliably across diverse styles. Extensive human evaluations show that Qwen-Image-2.0 substantially outperforms previous Qwen-Image models in both generation and editing, marking a step toward more general, reliable, and practical image generation foundation models.
Extending Sequence Length is Not All You Need: Effective Integration of Multimodal Signals for Gene Expression Prediction
Feb 25, 2026Gene expression prediction, which predicts mRNA expression levels from DNA sequences, presents significant challenges. Previous works often focus on extending input sequence length to locate distal enhancers, which may influence target genes from hundreds of kilobases away. Our work first reveals that for current models, long sequence modeling can decrease performance. Even carefully designed algorithms only mitigate the performance degradation caused by long sequences. Instead, we find that proximal multimodal epigenomic signals near target genes prove more essential. Hence we focus on how to better integrate these signals, which has been overlooked. We find that different signal types serve distinct biological roles, with some directly marking active regulatory elements while others reflect background chromatin patterns that may introduce confounding effects. Simple concatenation may lead models to develop spurious associations with these background patterns. To address this challenge, we propose Prism, a framework that learns multiple combinations of high-dimensional epigenomic features to represent distinct background chromatin states and uses backdoor adjustment to mitigate confounding effects. Our experimental results demonstrate that proper modeling of multimodal epigenomic signals achieves state-of-the-art performance using only short sequences for gene expression prediction.
Say Cheese! Detail-Preserving Portrait Collection Generation via Natural Language Edits
Jan 28, 2026As social media platforms proliferate, users increasingly demand intuitive ways to create diverse, high-quality portrait collections. In this work, we introduce Portrait Collection Generation (PCG), a novel task that generates coherent portrait collections by editing a reference portrait image through natural language instructions. This task poses two unique challenges to existing methods: (1) complex multi-attribute modifications such as pose, spatial layout, and camera viewpoint; and (2) high-fidelity detail preservation including identity, clothing, and accessories. To address these challenges, we propose CHEESE, the first large-scale PCG dataset containing 24K portrait collections and 573K samples with high-quality modification text annotations, constructed through an Large Vison-Language Model-based pipeline with inversion-based verification. We further propose SCheese, a framework that combines text-guided generation with hierarchical identity and detail preservation. SCheese employs adaptive feature fusion mechanism to maintain identity consistency, and ConsistencyNet to inject fine-grained features for detail consistency. Comprehensive experiments validate the effectiveness of CHEESE in advancing PCG, with SCheese achieving state-of-the-art performance.
Learning User Preferences for Image Generation Model
Aug 11, 2025User preference prediction requires a comprehensive and accurate understanding of individual tastes. This includes both surface-level attributes, such as color and style, and deeper content-related aspects, such as themes and composition. However, existing methods typically rely on general human preferences or assume static user profiles, often neglecting individual variability and the dynamic, multifaceted nature of personal taste. To address these limitations, we propose an approach built upon Multimodal Large Language Models, introducing contrastive preference loss and preference tokens to learn personalized user preferences from historical interactions. The contrastive preference loss is designed to effectively distinguish between user ''likes'' and ''dislikes'', while the learnable preference tokens capture shared interest representations among existing users, enabling the model to activate group-specific preferences and enhance consistency across similar users. Extensive experiments demonstrate our model outperforms other methods in preference prediction accuracy, effectively identifying users with similar aesthetic inclinations and providing more precise guidance for generating images that align with individual tastes. The project page is \texttt{https://learn-user-pref.github.io/}.
Self-Supervised Representation Learning with Meta Comprehensive Regularization
Mar 03, 2024Self-Supervised Learning (SSL) methods harness the concept of semantic invariance by utilizing data augmentation strategies to produce similar representations for different deformations of the same input. Essentially, the model captures the shared information among multiple augmented views of samples, while disregarding the non-shared information that may be beneficial for downstream tasks. To address this issue, we introduce a module called CompMod with Meta Comprehensive Regularization (MCR), embedded into existing self-supervised frameworks, to make the learned representations more comprehensive. Specifically, we update our proposed model through a bi-level optimization mechanism, enabling it to capture comprehensive features. Additionally, guided by the constrained extraction of features using maximum entropy coding, the self-supervised learning model learns more comprehensive features on top of learning consistent features. In addition, we provide theoretical support for our proposed method from information theory and causal counterfactual perspective. Experimental results show that our method achieves significant improvement in classification, object detection and instance segmentation tasks on multiple benchmark datasets.
Spatio-Temporal Branching for Motion Prediction using Motion Increments
Aug 11, 2023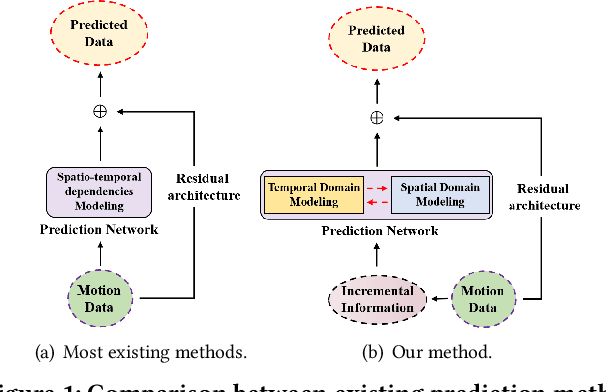
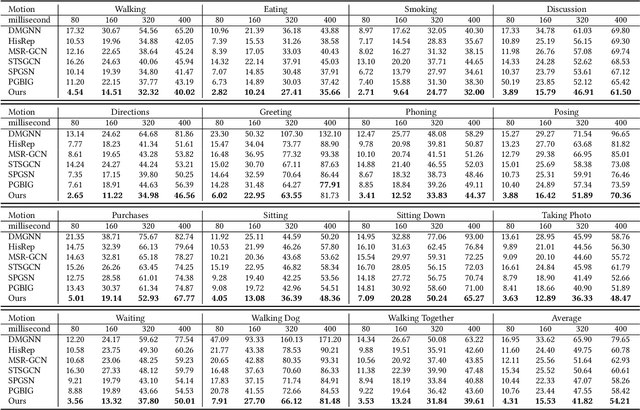
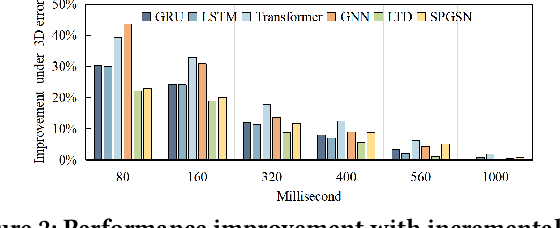
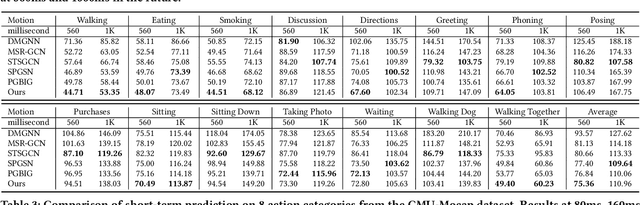
Human motion prediction (HMP) has emerged as a popular research topic due to its diverse applications, but it remains a challenging task due to the stochastic and aperiodic nature of future poses. Traditional methods rely on hand-crafted features and machine learning techniques, which often struggle to model the complex dynamics of human motion. Recent deep learning-based methods have achieved success by learning spatio-temporal representations of motion, but these models often overlook the reliability of motion data. Additionally, the temporal and spatial dependencies of skeleton nodes are distinct. The temporal relationship captures motion information over time, while the spatial relationship describes body structure and the relationships between different nodes. In this paper, we propose a novel spatio-temporal branching network using incremental information for HMP, which decouples the learning of temporal-domain and spatial-domain features, extracts more motion information, and achieves complementary cross-domain knowledge learning through knowledge distillation. Our approach effectively reduces noise interference and provides more expressive information for characterizing motion by separately extracting temporal and spatial features. We evaluate our approach on standard HMP benchmarks and outperform state-of-the-art methods in terms of prediction accuracy.