 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePremier: Personalized Preference Modulation with Learnable User Embedding in Text-to-Image Generation
Mar 21, 2026Text-to-image generation has advanced rapidly, yet it still struggles to capture the nuanced user preferences. Existing approaches typically rely on multimodal large language models to infer user preferences, but the derived prompts or latent codes rarely reflect them faithfully, leading to suboptimal personalization. We present Premier, a novel preference modulation framework for personalized image generation. Premier represents each user's preference as a learnable embedding and introduces a preference adapter that fuses the user embedding with the text prompt. To enable accurate and fine-grained preference control, the fused preference embedding is further used to modulate the generative process. To enhance the distinctness of individual preference and improve alignment between outputs and user-specific styles, we incorporate a dispersion loss that enforces separation among user embeddings. When user data are scarce, new users are represented as linear combinations of existing preference embeddings learned during training, enabling effective generalization. Experiments show that Premier outperforms prior methods under the same history length, achieving stronger preference alignment and superior performance on text consistency, ViPer proxy metrics, and expert evaluations.
Learning User Preferences for Image Generation Model
Aug 11, 2025User preference prediction requires a comprehensive and accurate understanding of individual tastes. This includes both surface-level attributes, such as color and style, and deeper content-related aspects, such as themes and composition. However, existing methods typically rely on general human preferences or assume static user profiles, often neglecting individual variability and the dynamic, multifaceted nature of personal taste. To address these limitations, we propose an approach built upon Multimodal Large Language Models, introducing contrastive preference loss and preference tokens to learn personalized user preferences from historical interactions. The contrastive preference loss is designed to effectively distinguish between user ''likes'' and ''dislikes'', while the learnable preference tokens capture shared interest representations among existing users, enabling the model to activate group-specific preferences and enhance consistency across similar users. Extensive experiments demonstrate our model outperforms other methods in preference prediction accuracy, effectively identifying users with similar aesthetic inclinations and providing more precise guidance for generating images that align with individual tastes. The project page is \texttt{https://learn-user-pref.github.io/}.
V2Flow: Unifying Visual Tokenization and Large Language Model Vocabularies for Autoregressive Image Generation
Mar 10, 2025We propose V2Flow, a novel tokenizer that produces discrete visual tokens capable of high-fidelity reconstruction, while ensuring structural and latent distribution alignment with the vocabulary space of large language models (LLMs). Leveraging this tight visual-vocabulary coupling, V2Flow enables autoregressive visual generation on top of existing LLMs. Our approach formulates visual tokenization as a flow-matching problem, aiming to learn a mapping from a standard normal prior to the continuous image distribution, conditioned on token sequences embedded within the LLMs vocabulary space. The effectiveness of V2Flow stems from two core designs. First, we propose a Visual Vocabulary resampler, which compresses visual data into compact token sequences, with each represented as a soft categorical distribution over LLM's vocabulary. This allows seamless integration of visual tokens into existing LLMs for autoregressive visual generation. Second, we present a masked autoregressive Rectified-Flow decoder, employing a masked transformer encoder-decoder to refine visual tokens into contextually enriched embeddings. These embeddings then condition a dedicated velocity field for precise reconstruction. Additionally, an autoregressive rectified-flow sampling strategy is incorporated, ensuring flexible sequence lengths while preserving competitive reconstruction quality. Extensive experiments show that V2Flow outperforms mainstream VQ-based tokenizers and facilitates autoregressive visual generation on top of existing. https://github.com/zhangguiwei610/V2Flow
Uniform Attention Maps: Boosting Image Fidelity in Reconstruction and Editing
Nov 29, 2024



Text-guided image generation and editing using diffusion models have achieved remarkable advancements. Among these, tuning-free methods have gained attention for their ability to perform edits without extensive model adjustments, offering simplicity and efficiency. However, existing tuning-free approaches often struggle with balancing fidelity and editing precision. Reconstruction errors in DDIM Inversion are partly attributed to the cross-attention mechanism in U-Net, which introduces misalignments during the inversion and reconstruction process. To address this, we analyze reconstruction from a structural perspective and propose a novel approach that replaces traditional cross-attention with uniform attention maps, significantly enhancing image reconstruction fidelity. Our method effectively minimizes distortions caused by varying text conditions during noise prediction. To complement this improvement, we introduce an adaptive mask-guided editing technique that integrates seamlessly with our reconstruction approach, ensuring consistency and accuracy in editing tasks. Experimental results demonstrate that our approach not only excels in achieving high-fidelity image reconstruction but also performs robustly in real image composition and editing scenarios. This study underscores the potential of uniform attention maps to enhance the fidelity and versatility of diffusion-based image processing methods. Code is available at https://github.com/Mowenyii/Uniform-Attention-Maps.
STAR: Scale-wise Text-to-image generation via Auto-Regressive representations
Jun 16, 2024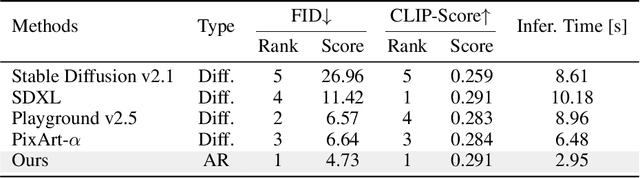
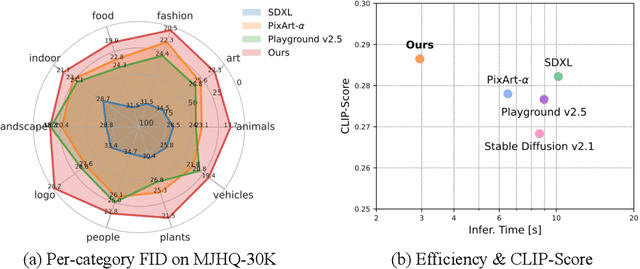
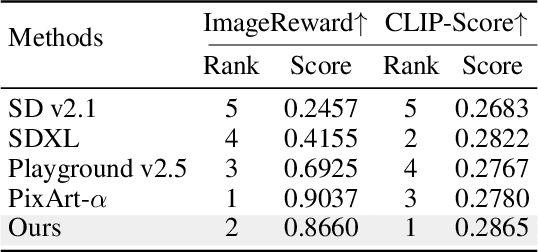
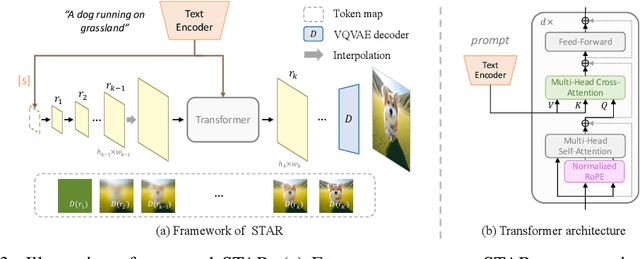
We present STAR, a text-to-image model that employs scale-wise auto-regressive paradigm. Unlike VAR, which is limited to class-conditioned synthesis within a fixed set of predetermined categories, our STAR enables text-driven open-set generation through three key designs: To boost diversity and generalizability with unseen combinations of objects and concepts, we introduce a pre-trained text encoder to extract representations for textual constraints, which we then use as guidance. To improve the interactions between generated images and fine-grained textual guidance, making results more controllable, additional cross-attention layers are incorporated at each scale. Given the natural structure correlation across different scales, we leverage 2D Rotary Positional Encoding (RoPE) and tweak it into a normalized version. This ensures consistent interpretation of relative positions across token maps at different scales and stabilizes the training process. Extensive experiments demonstrate that STAR surpasses existing benchmarks in terms of fidelity,image text consistency, and aesthetic quality. Our findings emphasize the potential of auto-regressive methods in the field of high-quality image synthesis, offering promising new directions for the T2I field currently dominated by diffusion methods.
Dynamic Prompt Optimizing for Text-to-Image Generation
Apr 05, 2024



Text-to-image generative models, specifically those based on diffusion models like Imagen and Stable Diffusion, have made substantial advancements. Recently, there has been a surge of interest in the delicate refinement of text prompts. Users assign weights or alter the injection time steps of certain words in the text prompts to improve the quality of generated images. However, the success of fine-control prompts depends on the accuracy of the text prompts and the careful selection of weights and time steps, which requires significant manual intervention. To address this, we introduce the \textbf{P}rompt \textbf{A}uto-\textbf{E}diting (PAE) method. Besides refining the original prompts for image generation, we further employ an online reinforcement learning strategy to explore the weights and injection time steps of each word, leading to the dynamic fine-control prompts. The reward function during training encourages the model to consider aesthetic score, semantic consistency, and user preferences. Experimental results demonstrate that our proposed method effectively improves the original prompts, generating visually more appealing images while maintaining semantic alignment. Code is available at https://github.com/Mowenyii/PAE.
StyleInject: Parameter Efficient Tuning of Text-to-Image Diffusion Models
Jan 25, 2024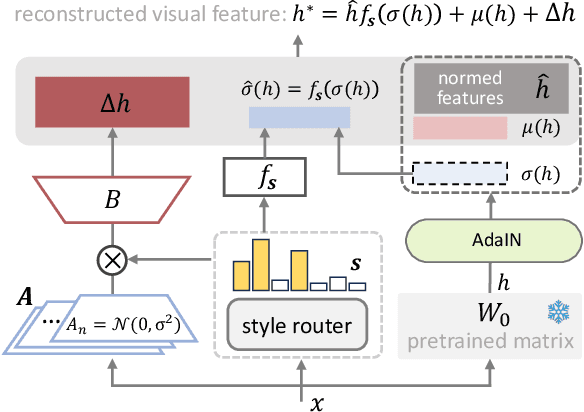



The ability to fine-tune generative models for text-to-image generation tasks is crucial, particularly facing the complexity involved in accurately interpreting and visualizing textual inputs. While LoRA is efficient for language model adaptation, it often falls short in text-to-image tasks due to the intricate demands of image generation, such as accommodating a broad spectrum of styles and nuances. To bridge this gap, we introduce StyleInject, a specialized fine-tuning approach tailored for text-to-image models. StyleInject comprises multiple parallel low-rank parameter matrices, maintaining the diversity of visual features. It dynamically adapts to varying styles by adjusting the variance of visual features based on the characteristics of the input signal. This approach significantly minimizes the impact on the original model's text-image alignment capabilities while adeptly adapting to various styles in transfer learning. StyleInject proves particularly effective in learning from and enhancing a range of advanced, community-fine-tuned generative models. Our comprehensive experiments, including both small-sample and large-scale data fine-tuning as well as base model distillation, show that StyleInject surpasses traditional LoRA in both text-image semantic consistency and human preference evaluation, all while ensuring greater parameter efficiency.
Learning and Evaluating Human Preferences for Conversational Head Generation
Aug 02, 2023



A reliable and comprehensive evaluation metric that aligns with manual preference assessments is crucial for conversational head video synthesis methods development. Existing quantitative evaluations often fail to capture the full complexity of human preference, as they only consider limited evaluation dimensions. Qualitative evaluations and user studies offer a solution but are time-consuming and labor-intensive. This limitation hinders the advancement of conversational head generation algorithms and systems. In this paper, we propose a novel learning-based evaluation metric named Preference Score (PS) for fitting human preference according to the quantitative evaluations across different dimensions. PS can serve as a quantitative evaluation without the need for human annotation. Experimental results validate the superiority of Preference Score in aligning with human perception, and also demonstrate robustness and generalizability to unseen data, making it a valuable tool for advancing conversation head generation. We expect this metric could facilitate new advances in conversational head generation. Project Page: https://https://github.com/dc3ea9f/PreferenceScore.
Interactive Conversational Head Generation
Jul 05, 2023



We introduce a new conversation head generation benchmark for synthesizing behaviors of a single interlocutor in a face-to-face conversation. The capability to automatically synthesize interlocutors which can participate in long and multi-turn conversations is vital and offer benefits for various applications, including digital humans, virtual agents, and social robots. While existing research primarily focuses on talking head generation (one-way interaction), hindering the ability to create a digital human for conversation (two-way) interaction due to the absence of listening and interaction parts. In this work, we construct two datasets to address this issue, ``ViCo'' for independent talking and listening head generation tasks at the sentence level, and ``ViCo-X'', for synthesizing interlocutors in multi-turn conversational scenarios. Based on ViCo and ViCo-X, we define three novel tasks targeting the interaction modeling during the face-to-face conversation: 1) responsive listening head generation making listeners respond actively to the speaker with non-verbal signals, 2) expressive talking head generation guiding speakers to be aware of listeners' behaviors, and 3) conversational head generation to integrate the talking/listening ability in one interlocutor. Along with the datasets, we also propose corresponding baseline solutions to the three aforementioned tasks. Experimental results show that our baseline method could generate responsive and vivid agents that can collaborate with real person to fulfil the whole conversation. Project page: https://vico.solutions/.
Deep Equilibrium Multimodal Fusion
Jun 29, 2023



Multimodal fusion integrates the complementary information present in multiple modalities and has gained much attention recently. Most existing fusion approaches either learn a fixed fusion strategy during training and inference, or are only capable of fusing the information to a certain extent. Such solutions may fail to fully capture the dynamics of interactions across modalities especially when there are complex intra- and inter-modality correlations to be considered for informative multimodal fusion. In this paper, we propose a novel deep equilibrium (DEQ) method towards multimodal fusion via seeking a fixed point of the dynamic multimodal fusion process and modeling the feature correlations in an adaptive and recursive manner. This new way encodes the rich information within and across modalities thoroughly from low level to high level for efficacious downstream multimodal learning and is readily pluggable to various multimodal frameworks. Extensive experiments on BRCA, MM-IMDB, CMU-MOSI, SUN RGB-D, and VQA-v2 demonstrate the superiority of our DEQ fusion. More remarkably, DEQ fusion consistently achieves state-of-the-art performance on multiple multimodal benchmarks. The code will be released.