 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePareto-Guided Optimal Transport for Multi-Reward Alignment
May 13, 2026Text-to-image generation models have achieved remarkable progress in preference optimization, yet achieving robust alignment across diverse reward models remains a significant challenge. Existing multi-reward fusion approaches rely on weighted summation, which is costly to tune and insufficient for balancing conflicting objectives. More critically, optimization with reward models is highly susceptible to reward hacking, where reward scores increase while the perceived quality of generated images deteriorates. We demonstrate that optimizing against a unified global target under heterogeneous reward upper bounds can induce reward hacking, a risk further exacerbated by the inherent instability of weak reward models. To mitigate this, we propose a Pareto Frontier-Guided Optimal Transport (PG-OT) framework. Our method constructs a prompt-specific Pareto frontier and maps dominated samples toward it via distribution-aware optimal transport. Furthermore, we develop both online and offline optimization strategies tailored to diverse reward signal characteristics. To provide a more rigorous assessment, we introduce the Joint Domination Rate (JDR) and Joint Collapse Rate (JCR) as principled metrics to quantify multi-reward synergy and reward hacking. Experimental results show that our approach outperforms strong baselines with an 11% gain in JDR and achieves a near 80% win rate in human evaluations.
Learning User Preferences for Image Generation Model
Aug 11, 2025User preference prediction requires a comprehensive and accurate understanding of individual tastes. This includes both surface-level attributes, such as color and style, and deeper content-related aspects, such as themes and composition. However, existing methods typically rely on general human preferences or assume static user profiles, often neglecting individual variability and the dynamic, multifaceted nature of personal taste. To address these limitations, we propose an approach built upon Multimodal Large Language Models, introducing contrastive preference loss and preference tokens to learn personalized user preferences from historical interactions. The contrastive preference loss is designed to effectively distinguish between user ''likes'' and ''dislikes'', while the learnable preference tokens capture shared interest representations among existing users, enabling the model to activate group-specific preferences and enhance consistency across similar users. Extensive experiments demonstrate our model outperforms other methods in preference prediction accuracy, effectively identifying users with similar aesthetic inclinations and providing more precise guidance for generating images that align with individual tastes. The project page is \texttt{https://learn-user-pref.github.io/}.
Uniform Attention Maps: Boosting Image Fidelity in Reconstruction and Editing
Nov 29, 2024



Text-guided image generation and editing using diffusion models have achieved remarkable advancements. Among these, tuning-free methods have gained attention for their ability to perform edits without extensive model adjustments, offering simplicity and efficiency. However, existing tuning-free approaches often struggle with balancing fidelity and editing precision. Reconstruction errors in DDIM Inversion are partly attributed to the cross-attention mechanism in U-Net, which introduces misalignments during the inversion and reconstruction process. To address this, we analyze reconstruction from a structural perspective and propose a novel approach that replaces traditional cross-attention with uniform attention maps, significantly enhancing image reconstruction fidelity. Our method effectively minimizes distortions caused by varying text conditions during noise prediction. To complement this improvement, we introduce an adaptive mask-guided editing technique that integrates seamlessly with our reconstruction approach, ensuring consistency and accuracy in editing tasks. Experimental results demonstrate that our approach not only excels in achieving high-fidelity image reconstruction but also performs robustly in real image composition and editing scenarios. This study underscores the potential of uniform attention maps to enhance the fidelity and versatility of diffusion-based image processing methods. Code is available at https://github.com/Mowenyii/Uniform-Attention-Maps.
Dynamic Prompt Optimizing for Text-to-Image Generation
Apr 05, 2024



Text-to-image generative models, specifically those based on diffusion models like Imagen and Stable Diffusion, have made substantial advancements. Recently, there has been a surge of interest in the delicate refinement of text prompts. Users assign weights or alter the injection time steps of certain words in the text prompts to improve the quality of generated images. However, the success of fine-control prompts depends on the accuracy of the text prompts and the careful selection of weights and time steps, which requires significant manual intervention. To address this, we introduce the \textbf{P}rompt \textbf{A}uto-\textbf{E}diting (PAE) method. Besides refining the original prompts for image generation, we further employ an online reinforcement learning strategy to explore the weights and injection time steps of each word, leading to the dynamic fine-control prompts. The reward function during training encourages the model to consider aesthetic score, semantic consistency, and user preferences. Experimental results demonstrate that our proposed method effectively improves the original prompts, generating visually more appealing images while maintaining semantic alignment. Code is available at https://github.com/Mowenyii/PAE.
MetaMask: Revisiting Dimensional Confounder for Self-Supervised Learning
Sep 16, 2022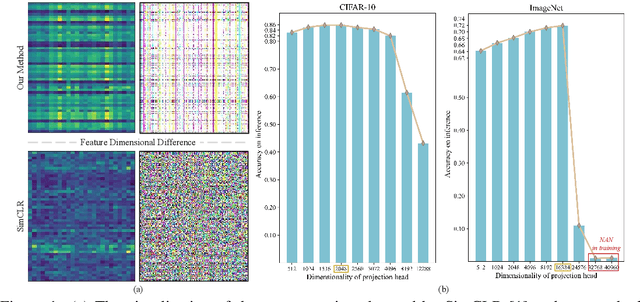
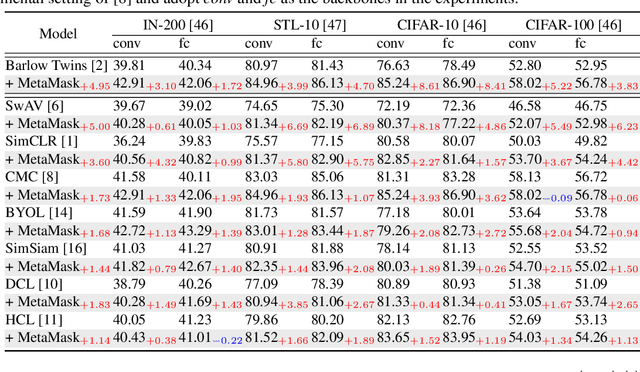
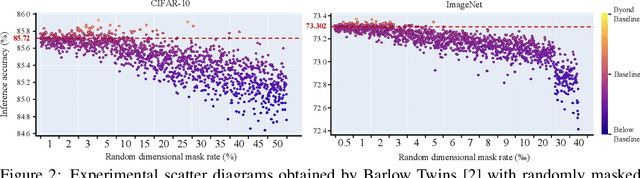
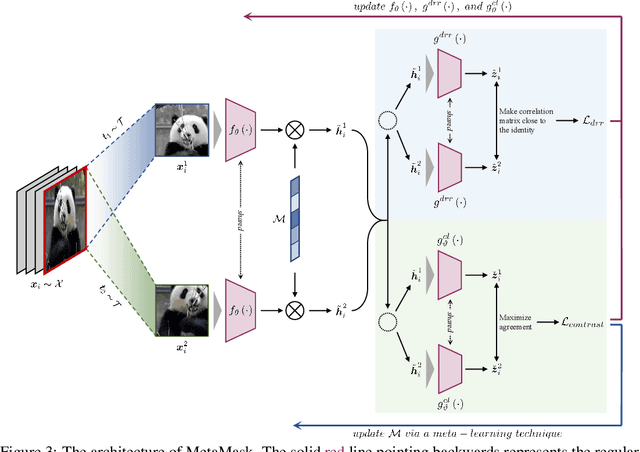
As a successful approach to self-supervised learning, contrastive learning aims to learn invariant information shared among distortions of the input sample. While contrastive learning has yielded continuous advancements in sampling strategy and architecture design, it still remains two persistent defects: the interference of task-irrelevant information and sample inefficiency, which are related to the recurring existence of trivial constant solutions. From the perspective of dimensional analysis, we find out that the dimensional redundancy and dimensional confounder are the intrinsic issues behind the phenomena, and provide experimental evidence to support our viewpoint. We further propose a simple yet effective approach MetaMask, short for the dimensional Mask learned by Meta-learning, to learn representations against dimensional redundancy and confounder. MetaMask adopts the redundancy-reduction technique to tackle the dimensional redundancy issue and innovatively introduces a dimensional mask to reduce the gradient effects of specific dimensions containing the confounder, which is trained by employing a meta-learning paradigm with the objective of improving the performance of masked representations on a typical self-supervised task. We provide solid theoretical analyses to prove MetaMask can obtain tighter risk bounds for downstream classification compared to typical contrastive methods. Empirically, our method achieves state-of-the-art performance on various benchmarks.
Supporting Vision-Language Model Inference with Causality-pruning Knowledge Prompt
May 23, 2022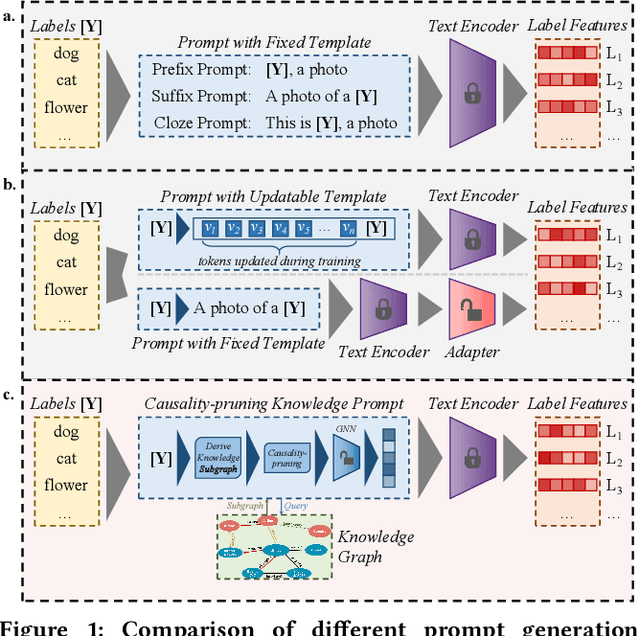
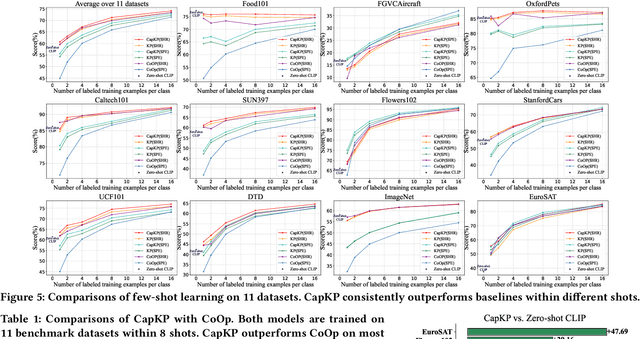
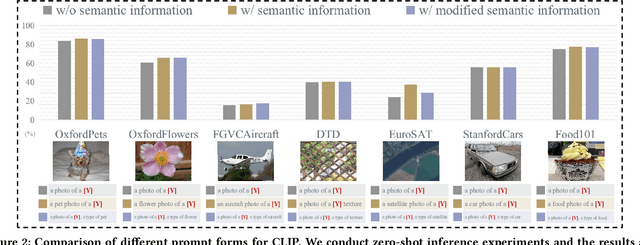
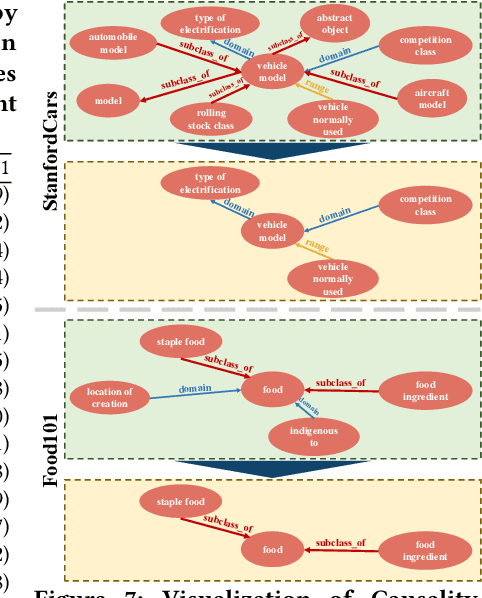
Vision-language models are pre-trained by aligning image-text pairs in a common space so that the models can deal with open-set visual concepts by learning semantic information from textual labels. To boost the transferability of these models on downstream tasks in a zero-shot manner, recent works explore generating fixed or learnable prompts, i.e., classification weights are synthesized from natural language describing task-relevant categories, to reduce the gap between tasks in the training and test phases. However, how and what prompts can improve inference performance remains unclear. In this paper, we explicitly provide exploration and clarify the importance of including semantic information in prompts, while existing prompt methods generate prompts without exploring the semantic information of textual labels. A challenging issue is that manually constructing prompts, with rich semantic information, requires domain expertise and is extremely time-consuming. To this end, we propose Causality-pruning Knowledge Prompt (CapKP) for adapting pre-trained vision-language models to downstream image recognition. CapKP retrieves an ontological knowledge graph by treating the textual label as a query to explore task-relevant semantic information. To further refine the derived semantic information, CapKP introduces causality-pruning by following the first principle of Granger causality. Empirically, we conduct extensive evaluations to demonstrate the effectiveness of CapKP, e.g., with 8 shots, CapKP outperforms the manual-prompt method by 12.51% and the learnable-prompt method by 1.39% on average, respectively. Experimental analyses prove the superiority of CapKP in domain generalization compared to benchmark approaches.