 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUAF: A Unified Audio Front-end LLM for Full-Duplex Speech Interaction
Apr 21, 2026Full-duplex speech interaction, as the most natural and intuitive mode of human communication, is driving artificial intelligence toward more human-like conversational systems. Traditional cascaded speech processing pipelines suffer from critical limitations, including accumulated latency, information loss, and error propagation across modules. To address these issues, recent efforts focus on the end-to-end audio large language models (LLMs) like GPT-4o, which primarily unify speech understanding and generation task. However, most of these models are inherently half-duplex, and rely on a suite of separate, task-specific front-end components, such as voice activity detection (VAD) and turn-taking detection (TD). In our development of speech assistant, we observed that optimizing the speech front-end is equally crucial as advancing the back-end unified model for achieving seamless, responsive interactions. To bridge this gap, we propose the first unified audio front-end LLM (UAF) tailored for full-duplex speech systems. Our model reformulates diverse audio front-end tasks into a single auto-regressive sequence prediction problem, including VAD, TD, speaker recognition (SR), automatic speech recognition (ASR) and question answer (QA). It takes streaming fixed-duration audio chunk (e.g., 600 ms) as input, leverages a reference audio prompt to anchor the target speaker at the beginning, and regressively generates discrete tokens encoding both semantic content and system-level state controls (e.g., interruption signals). Experiments demonstrate that our model achieves leading performance across multiple audio front-end tasks and significantly enhances response latency and interruption accuracy in real-world interaction scenarios.
Learning User Preferences for Image Generation Model
Aug 11, 2025User preference prediction requires a comprehensive and accurate understanding of individual tastes. This includes both surface-level attributes, such as color and style, and deeper content-related aspects, such as themes and composition. However, existing methods typically rely on general human preferences or assume static user profiles, often neglecting individual variability and the dynamic, multifaceted nature of personal taste. To address these limitations, we propose an approach built upon Multimodal Large Language Models, introducing contrastive preference loss and preference tokens to learn personalized user preferences from historical interactions. The contrastive preference loss is designed to effectively distinguish between user ''likes'' and ''dislikes'', while the learnable preference tokens capture shared interest representations among existing users, enabling the model to activate group-specific preferences and enhance consistency across similar users. Extensive experiments demonstrate our model outperforms other methods in preference prediction accuracy, effectively identifying users with similar aesthetic inclinations and providing more precise guidance for generating images that align with individual tastes. The project page is \texttt{https://learn-user-pref.github.io/}.
Teaching Language Models to Evolve with Users: Dynamic Profile Modeling for Personalized Alignment
May 21, 2025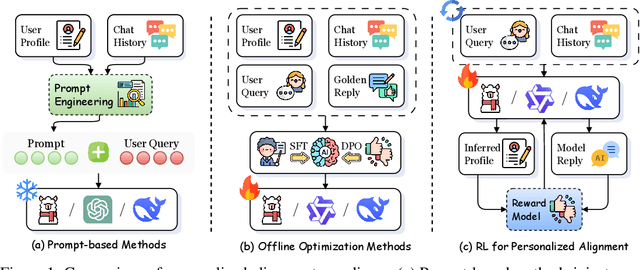
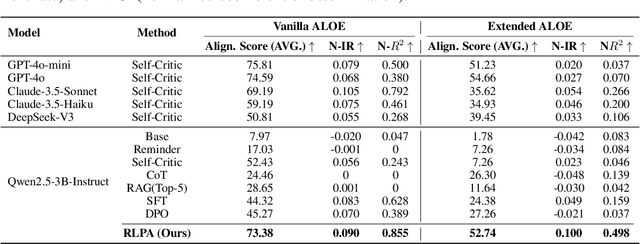
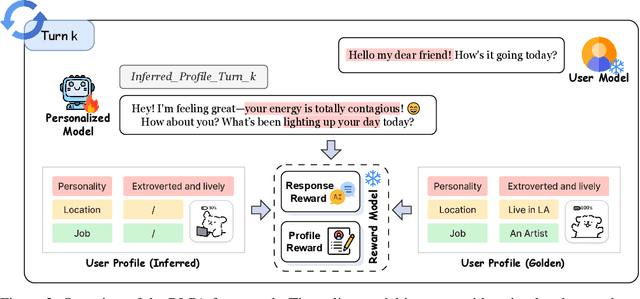

Personalized alignment is essential for enabling large language models (LLMs) to engage effectively in user-centric dialogue. While recent prompt-based and offline optimization methods offer preliminary solutions, they fall short in cold-start scenarios and long-term personalization due to their inherently static and shallow designs. In this work, we introduce the Reinforcement Learning for Personalized Alignment (RLPA) framework, in which an LLM interacts with a simulated user model to iteratively infer and refine user profiles through dialogue. The training process is guided by a dual-level reward structure: the Profile Reward encourages accurate construction of user representations, while the Response Reward incentivizes generation of responses consistent with the inferred profile. We instantiate RLPA by fine-tuning Qwen-2.5-3B-Instruct, resulting in Qwen-RLPA, which achieves state-of-the-art performance in personalized dialogue. Empirical evaluations demonstrate that Qwen-RLPA consistently outperforms prompting and offline fine-tuning baselines, and even surpasses advanced commercial models such as Claude-3.5 and GPT-4o. Further analysis highlights Qwen-RLPA's robustness in reconciling conflicting user preferences, sustaining long-term personalization and delivering more efficient inference compared to recent reasoning-focused LLMs. These results emphasize the potential of dynamic profile inference as a more effective paradigm for building personalized dialogue systems.
V2Flow: Unifying Visual Tokenization and Large Language Model Vocabularies for Autoregressive Image Generation
Mar 10, 2025We propose V2Flow, a novel tokenizer that produces discrete visual tokens capable of high-fidelity reconstruction, while ensuring structural and latent distribution alignment with the vocabulary space of large language models (LLMs). Leveraging this tight visual-vocabulary coupling, V2Flow enables autoregressive visual generation on top of existing LLMs. Our approach formulates visual tokenization as a flow-matching problem, aiming to learn a mapping from a standard normal prior to the continuous image distribution, conditioned on token sequences embedded within the LLMs vocabulary space. The effectiveness of V2Flow stems from two core designs. First, we propose a Visual Vocabulary resampler, which compresses visual data into compact token sequences, with each represented as a soft categorical distribution over LLM's vocabulary. This allows seamless integration of visual tokens into existing LLMs for autoregressive visual generation. Second, we present a masked autoregressive Rectified-Flow decoder, employing a masked transformer encoder-decoder to refine visual tokens into contextually enriched embeddings. These embeddings then condition a dedicated velocity field for precise reconstruction. Additionally, an autoregressive rectified-flow sampling strategy is incorporated, ensuring flexible sequence lengths while preserving competitive reconstruction quality. Extensive experiments show that V2Flow outperforms mainstream VQ-based tokenizers and facilitates autoregressive visual generation on top of existing. https://github.com/zhangguiwei610/V2Flow
Optimal Brain Iterative Merging: Mitigating Interference in LLM Merging
Feb 17, 2025



Large Language Models (LLMs) have demonstrated impressive capabilities, but their high computational costs pose challenges for customization. Model merging offers a cost-effective alternative, yet existing methods suffer from interference among parameters, leading to performance degradation. In this work, we propose Optimal Brain Iterative Merging (OBIM), a novel method designed to mitigate both intra-model and inter-model interference. OBIM consists of two key components: (1) A saliency measurement mechanism that evaluates parameter importance based on loss changes induced by individual weight alterations, reducing intra-model interference by preserving only high-saliency parameters. (2) A mutually exclusive iterative merging framework, which incrementally integrates models using a binary mask to avoid direct parameter averaging, thereby mitigating inter-model interference. We validate OBIM through experiments on both Supervised Fine-Tuned (SFT) models and post-pretrained checkpoints. The results show that OBIM significantly outperforms existing merging techniques. Overall, OBIM provides an effective and practical solution for enhancing LLM merging.
Skywork-MoE: A Deep Dive into Training Techniques for Mixture-of-Experts Language Models
Jun 03, 2024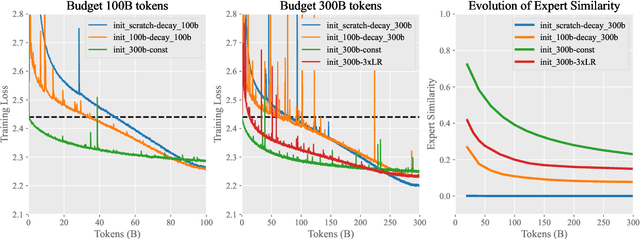
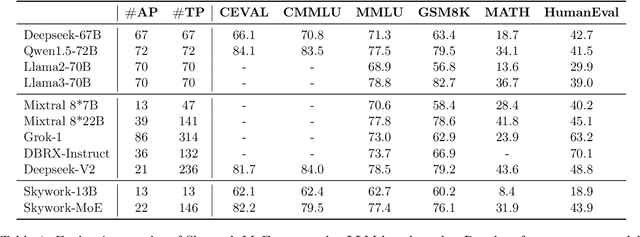
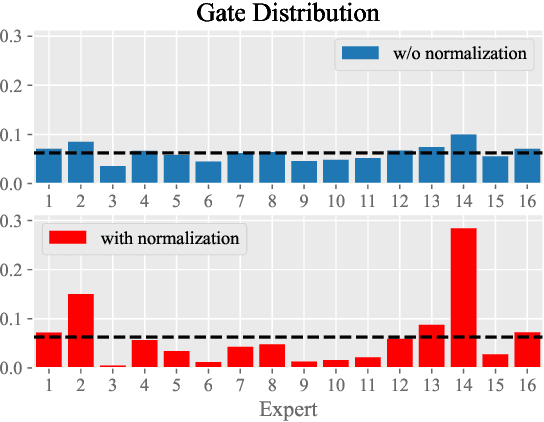
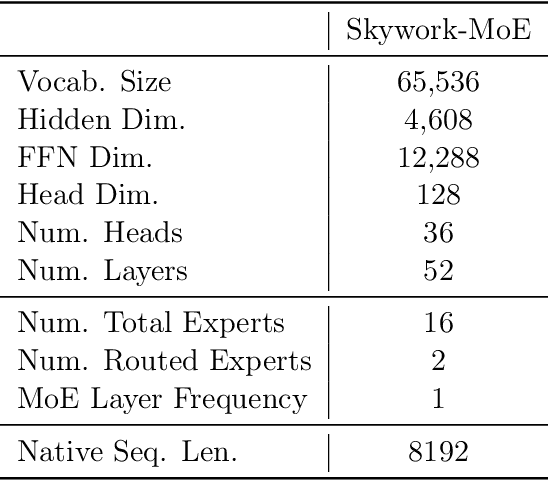
In this technical report, we introduce the training methodologies implemented in the development of Skywork-MoE, a high-performance mixture-of-experts (MoE) large language model (LLM) with 146 billion parameters and 16 experts. It is initialized from the pre-existing dense checkpoints of our Skywork-13B model. We explore the comparative effectiveness of upcycling versus training from scratch initializations. Our findings suggest that the choice between these two approaches should consider both the performance of the existing dense checkpoints and the MoE training budget. We highlight two innovative techniques: gating logit normalization, which improves expert diversification, and adaptive auxiliary loss coefficients, allowing for layer-specific adjustment of auxiliary loss coefficients. Our experimental results validate the effectiveness of these methods. Leveraging these techniques and insights, we trained our upcycled Skywork-MoE on a condensed subset of our SkyPile corpus. The evaluation results demonstrate that our model delivers strong performance across a wide range of benchmarks.
Skywork: A More Open Bilingual Foundation Model
Oct 30, 2023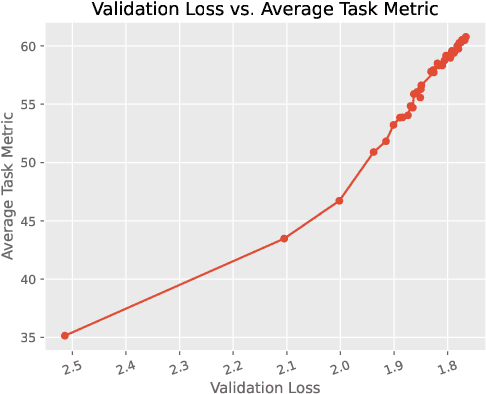
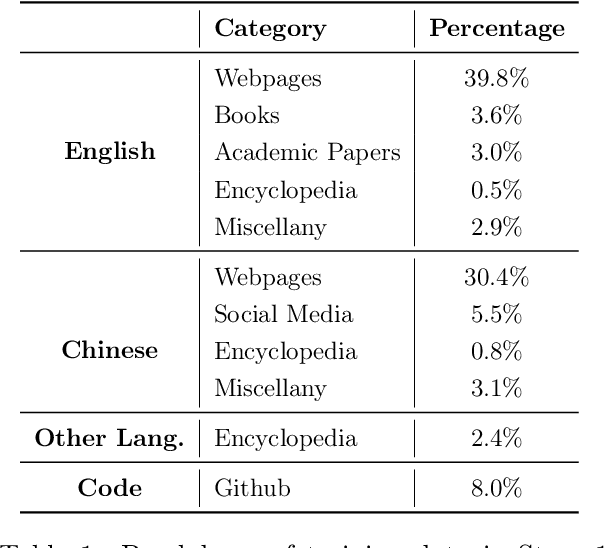
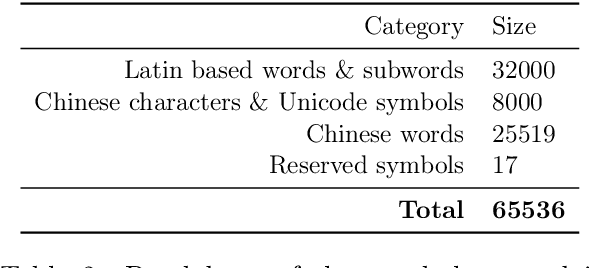
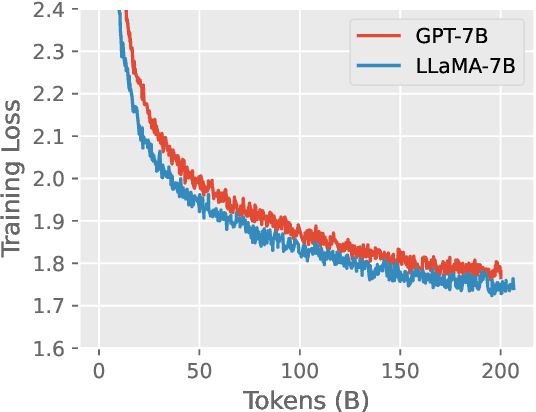
In this technical report, we present Skywork-13B, a family of large language models (LLMs) trained on a corpus of over 3.2 trillion tokens drawn from both English and Chinese texts. This bilingual foundation model is the most extensively trained and openly published LLMs of comparable size to date. We introduce a two-stage training methodology using a segmented corpus, targeting general purpose training and then domain-specific enhancement training, respectively. We show that our model not only excels on popular benchmarks, but also achieves \emph{state of the art} performance in Chinese language modeling on diverse domains. Furthermore, we propose a novel leakage detection method, demonstrating that test data contamination is a pressing issue warranting further investigation by the LLM community. To spur future research, we release Skywork-13B along with checkpoints obtained during intermediate stages of the training process. We are also releasing part of our SkyPile corpus, a collection of over 150 billion tokens of web text, which is the largest high quality open Chinese pre-training corpus to date. We hope Skywork-13B and our open corpus will serve as a valuable open-source resource to democratize access to high-quality LLMs.
SkyMath: Technical Report
Oct 26, 2023Large language models (LLMs) have shown great potential to solve varieties of natural language processing (NLP) tasks, including mathematical reasoning. In this work, we present SkyMath, a large language model for mathematics with 13 billion parameters. By applying self-compare fine-tuning, we have enhanced mathematical reasoning abilities of Skywork-13B-Base remarkably. On GSM8K, SkyMath outperforms all known open-source models of similar size and has established a new SOTA performance.