 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV2Flow: Unifying Visual Tokenization and Large Language Model Vocabularies for Autoregressive Image Generation
Mar 10, 2025We propose V2Flow, a novel tokenizer that produces discrete visual tokens capable of high-fidelity reconstruction, while ensuring structural and latent distribution alignment with the vocabulary space of large language models (LLMs). Leveraging this tight visual-vocabulary coupling, V2Flow enables autoregressive visual generation on top of existing LLMs. Our approach formulates visual tokenization as a flow-matching problem, aiming to learn a mapping from a standard normal prior to the continuous image distribution, conditioned on token sequences embedded within the LLMs vocabulary space. The effectiveness of V2Flow stems from two core designs. First, we propose a Visual Vocabulary resampler, which compresses visual data into compact token sequences, with each represented as a soft categorical distribution over LLM's vocabulary. This allows seamless integration of visual tokens into existing LLMs for autoregressive visual generation. Second, we present a masked autoregressive Rectified-Flow decoder, employing a masked transformer encoder-decoder to refine visual tokens into contextually enriched embeddings. These embeddings then condition a dedicated velocity field for precise reconstruction. Additionally, an autoregressive rectified-flow sampling strategy is incorporated, ensuring flexible sequence lengths while preserving competitive reconstruction quality. Extensive experiments show that V2Flow outperforms mainstream VQ-based tokenizers and facilitates autoregressive visual generation on top of existing. https://github.com/zhangguiwei610/V2Flow
From Poses to Identity: Training-Free Person Re-Identification via Feature Centralization
Mar 02, 2025



Person re-identification (ReID) aims to extract accurate identity representation features. However, during feature extraction, individual samples are inevitably affected by noise (background, occlusions, and model limitations). Considering that features from the same identity follow a normal distribution around identity centers after training, we propose a Training-Free Feature Centralization ReID framework (Pose2ID) by aggregating the same identity features to reduce individual noise and enhance the stability of identity representation, which preserves the feature's original distribution for following strategies such as re-ranking. Specifically, to obtain samples of the same identity, we introduce two components:Identity-Guided Pedestrian Generation: by leveraging identity features to guide the generation process, we obtain high-quality images with diverse poses, ensuring identity consistency even in complex scenarios such as infrared, and occlusion.Neighbor Feature Centralization: it explores each sample's potential positive samples from its neighborhood. Experiments demonstrate that our generative model exhibits strong generalization capabilities and maintains high identity consistency. With the Feature Centralization framework, we achieve impressive performance even with an ImageNet pre-trained model without ReID training, reaching mAP/Rank-1 of 52.81/78.92 on Market1501. Moreover, our method sets new state-of-the-art results across standard, cross-modality, and occluded ReID tasks, showcasing strong adaptability.
ProtoHPE: Prototype-guided High-frequency Patch Enhancement for Visible-Infrared Person Re-identification
Oct 11, 2023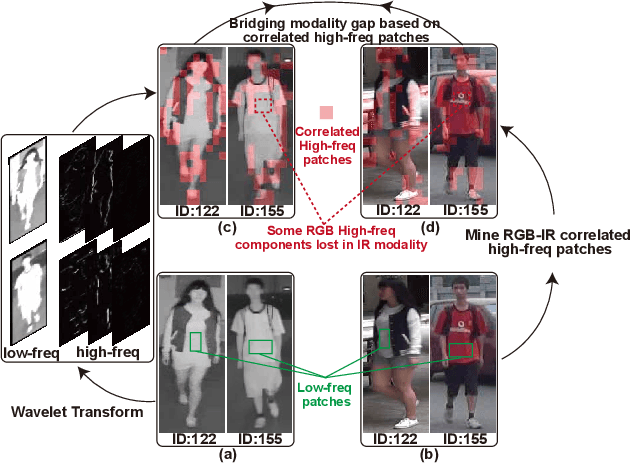
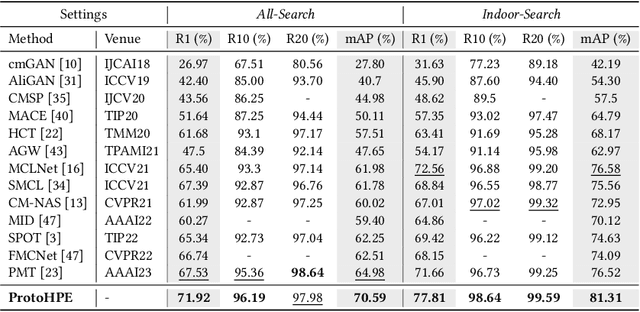
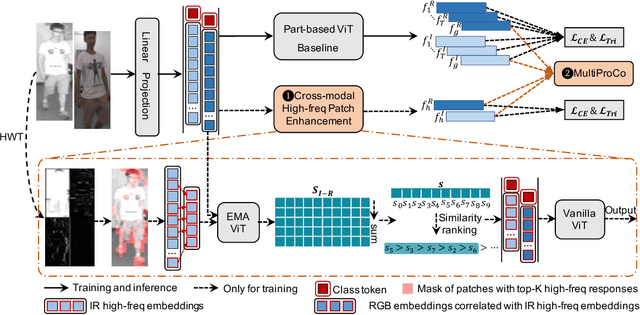
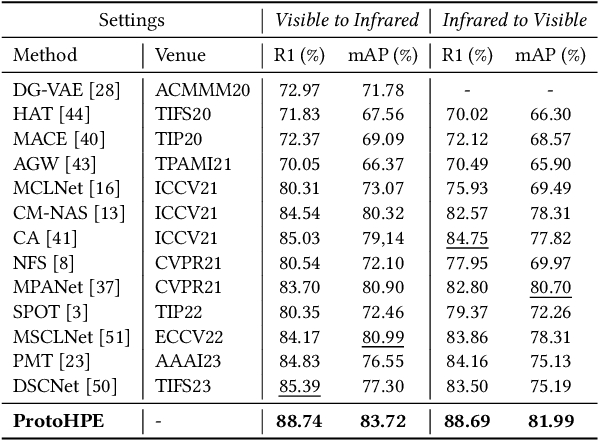
Visible-infrared person re-identification is challenging due to the large modality gap. To bridge the gap, most studies heavily rely on the correlation of visible-infrared holistic person images, which may perform poorly under severe distribution shifts. In contrast, we find that some cross-modal correlated high-frequency components contain discriminative visual patterns and are less affected by variations such as wavelength, pose, and background clutter than holistic images. Therefore, we are motivated to bridge the modality gap based on such high-frequency components, and propose \textbf{Proto}type-guided \textbf{H}igh-frequency \textbf{P}atch \textbf{E}nhancement (ProtoHPE) with two core designs. \textbf{First}, to enhance the representation ability of cross-modal correlated high-frequency components, we split patches with such components by Wavelet Transform and exponential moving average Vision Transformer (ViT), then empower ViT to take the split patches as auxiliary input. \textbf{Second}, to obtain semantically compact and discriminative high-frequency representations of the same identity, we propose Multimodal Prototypical Contrast. To be specific, it hierarchically captures the comprehensive semantics of different modal instances, facilitating the aggregation of high-frequency representations belonging to the same identity. With it, ViT can capture key high-frequency components during inference without relying on ProtoHPE, thus bringing no extra complexity. Extensive experiments validate the effectiveness of ProtoHPE.