 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensiCrafter: Physically-Constrained Generation and Fabrication of Self-Supporting Hollow Structures
Nov 12, 2025The rise of 3D generative models has enabled automatic 3D geometry and texture synthesis from multimodal inputs (e.g., text or images). However, these methods often ignore physical constraints and manufacturability considerations. In this work, we address the challenge of producing 3D designs that are both lightweight and self-supporting. We present DensiCrafter, a framework for generating lightweight, self-supporting 3D hollow structures by optimizing the density field. Starting from coarse voxel grids produced by Trellis, we interpret these as continuous density fields to optimize and introduce three differentiable, physically constrained, and simulation-free loss terms. Additionally, a mass regularization penalizes unnecessary material, while a restricted optimization domain preserves the outer surface. Our method seamlessly integrates with pretrained Trellis-based models (e.g., Trellis, DSO) without any architectural changes. In extensive evaluations, we achieve up to 43% reduction in material mass on the text-to-3D task. Compared to state-of-the-art baselines, our method could improve the stability and maintain high geometric fidelity. Real-world 3D-printing experiments confirm that our hollow designs can be reliably fabricated and could be self-supporting.
DATE: Dynamic Absolute Time Enhancement for Long Video Understanding
Sep 11, 2025Long video understanding remains a fundamental challenge for multimodal large language models (MLLMs), particularly in tasks requiring precise temporal reasoning and event localization. Existing approaches typically adopt uniform frame sampling and rely on implicit position encodings to model temporal order. However, these methods struggle with long-range dependencies, leading to critical information loss and degraded temporal comprehension. In this paper, we propose Dynamic Absolute Time Enhancement (DATE) that enhances temporal awareness in MLLMs through the Timestamp Injection Mechanism (TIM) and a semantically guided Temporal-Aware Similarity Sampling (TASS) strategy. Specifically, we interleave video frame embeddings with textual timestamp tokens to construct a continuous temporal reference system. We further reformulate the video sampling problem as a vision-language retrieval task and introduce a two-stage algorithm to ensure both semantic relevance and temporal coverage: enriching each query into a descriptive caption to better align with the vision feature, and sampling key event with a similarity-driven temporally regularized greedy strategy. Our method achieves remarkable improvements w.r.t. absolute time understanding and key event localization, resulting in state-of-the-art performance among 7B and 72B models on hour-long video benchmarks. Particularly, our 7B model even exceeds many 72B models on some benchmarks.
Neighbor-Based Feature and Index Enhancement for Person Re-Identification
Apr 16, 2025



Person re-identification (Re-ID) aims to match the same pedestrian in a large gallery with different cameras and views. Enhancing the robustness of the extracted feature representations is a main challenge in Re-ID. Existing methods usually improve feature representation by improving model architecture, but most methods ignore the potential contextual information, which limits the effectiveness of feature representation and retrieval performance. Neighborhood information, especially the potential information of multi-order neighborhoods, can effectively enrich feature expression and improve retrieval accuracy, but this has not been fully explored in existing research. Therefore, we propose a novel model DMON-ARO that leverages latent neighborhood information to enhance both feature representation and index performance. Our approach is built on two complementary modules: Dynamic Multi-Order Neighbor Modeling (DMON) and Asymmetric Relationship Optimization (ARO). The DMON module dynamically aggregates multi-order neighbor relationships, allowing it to capture richer contextual information and enhance feature representation through adaptive neighborhood modeling. Meanwhile, ARO refines the distance matrix by optimizing query-to-gallery relationships, improving the index accuracy. Extensive experiments on three benchmark datasets demonstrate that our approach achieves performance improvements against baseline models, which illustrate the effectiveness of our model. Specifically, our model demonstrates improvements in Rank-1 accuracy and mAP. Moreover, this method can also be directly extended to other re-identification tasks.
From Poses to Identity: Training-Free Person Re-Identification via Feature Centralization
Mar 02, 2025



Person re-identification (ReID) aims to extract accurate identity representation features. However, during feature extraction, individual samples are inevitably affected by noise (background, occlusions, and model limitations). Considering that features from the same identity follow a normal distribution around identity centers after training, we propose a Training-Free Feature Centralization ReID framework (Pose2ID) by aggregating the same identity features to reduce individual noise and enhance the stability of identity representation, which preserves the feature's original distribution for following strategies such as re-ranking. Specifically, to obtain samples of the same identity, we introduce two components:Identity-Guided Pedestrian Generation: by leveraging identity features to guide the generation process, we obtain high-quality images with diverse poses, ensuring identity consistency even in complex scenarios such as infrared, and occlusion.Neighbor Feature Centralization: it explores each sample's potential positive samples from its neighborhood. Experiments demonstrate that our generative model exhibits strong generalization capabilities and maintains high identity consistency. With the Feature Centralization framework, we achieve impressive performance even with an ImageNet pre-trained model without ReID training, reaching mAP/Rank-1 of 52.81/78.92 on Market1501. Moreover, our method sets new state-of-the-art results across standard, cross-modality, and occluded ReID tasks, showcasing strong adaptability.
Domain Adaptation Broad Learning System Based on Locally Linear Embedding
Jun 28, 2021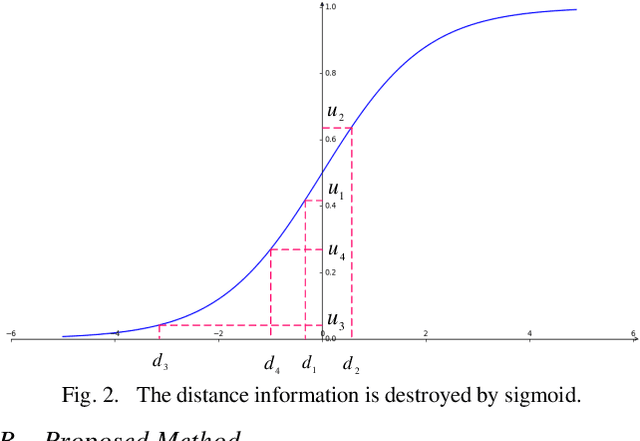
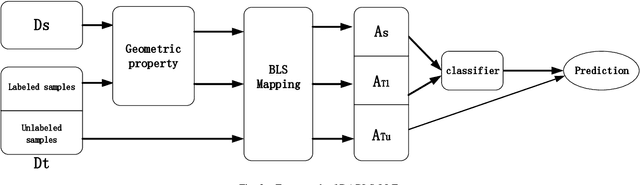

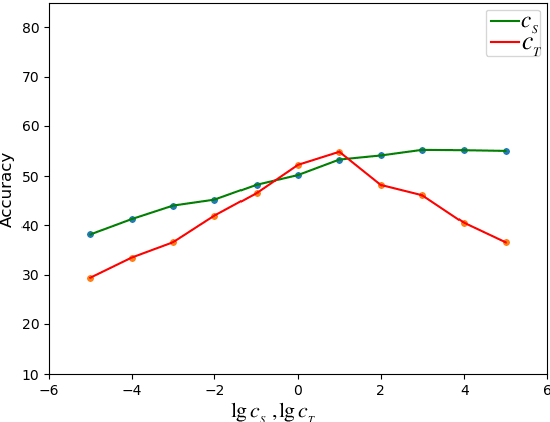
Broad learning system (BLS) has been proposed for a few years. It demonstrates an effective learning capability for many classification and regression problems. However, BLS and its improved versions are mainly used to deal with unsupervised, supervised and semi-supervised learning problems in a single domain. As far as we know, a little attention is paid to the cross-domain learning ability of BLS. Therefore, we introduce BLS into the field of transfer learning and propose a novel algorithm called domain adaptation broad learning system based on locally linear embedding (DABLS-LLE). The proposed algorithm can learn a robust classification model by using a small part of labeled data from the target domain and all labeled data from the source domain. The proposed algorithm inherits the computational efficiency and learning capability of BLS. Experiments on benchmark dataset (Office-Caltech-10) verify the effectiveness of our approach. The results show that our approach can get better classification accuracy with less running time than many existing transfer learning approaches. It shows that our approach can bring a new superiority for BLS.
On the Selective and Invariant Representation of DCNN for High-Resolution Remote Sensing Image Recognition
Aug 04, 2017
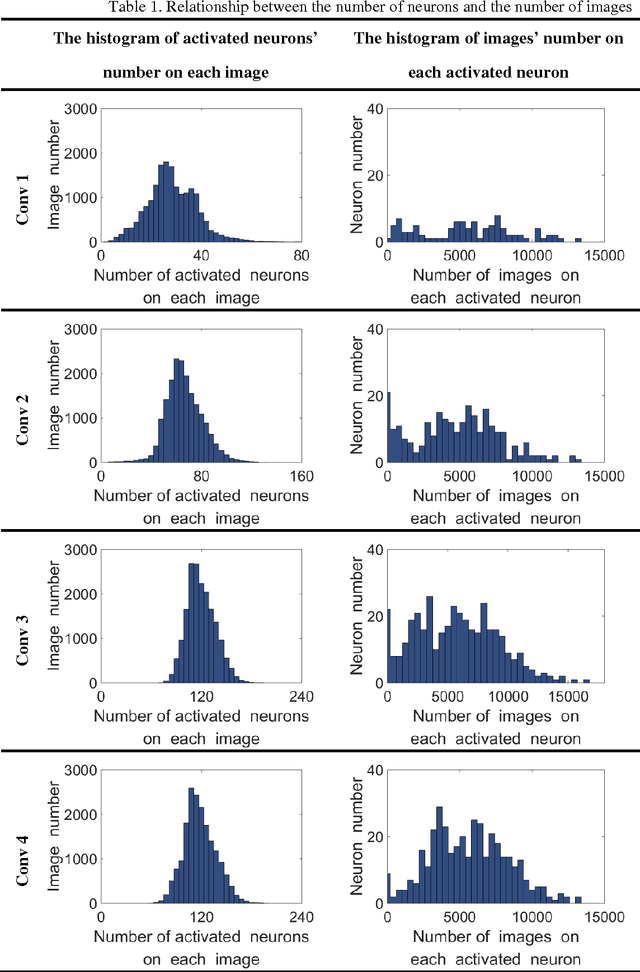
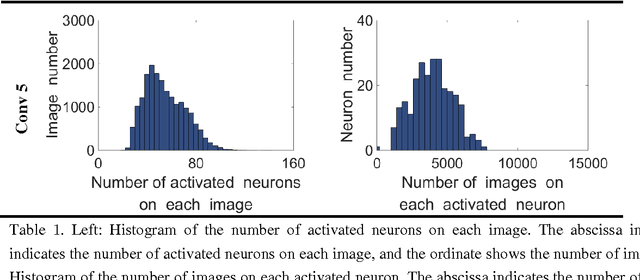
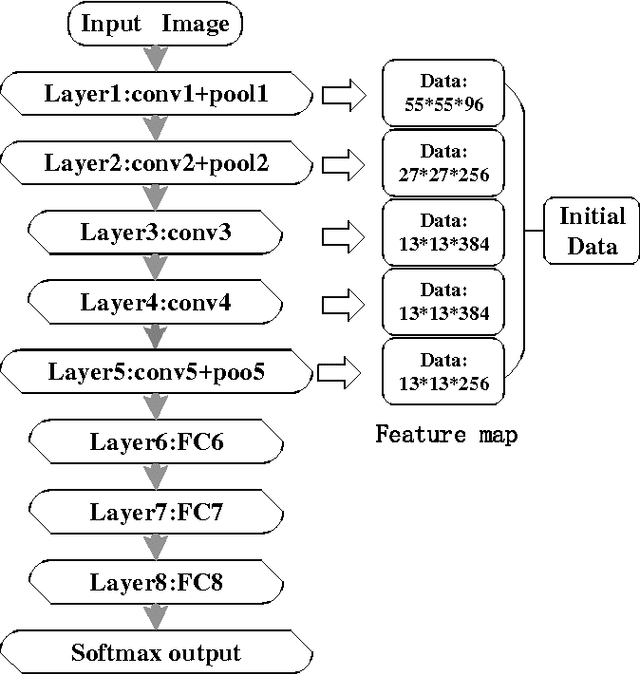
Human vision possesses strong invariance in image recognition. The cognitive capability of deep convolutional neural network (DCNN) is close to the human visual level because of hierarchical coding directly from raw image. Owing to its superiority in feature representation, DCNN has exhibited remarkable performance in scene recognition of high-resolution remote sensing (HRRS) images and classification of hyper-spectral remote sensing images. In-depth investigation is still essential for understanding why DCNN can accurately identify diverse ground objects via its effective feature representation. Thus, we train the deep neural network called AlexNet on our large scale remote sensing image recognition benchmark. At the neuron level in each convolution layer, we analyze the general properties of DCNN in HRRS image recognition by use of a framework of visual stimulation-characteristic response combined with feature coding-classification decoding. Specifically, we use histogram statistics, representational dissimilarity matrix, and class activation mapping to observe the selective and invariance representations of DCNN in HRRS image recognition. We argue that selective and invariance representations play important roles in remote sensing images tasks, such as classification, detection, and segment. Also selective and invariance representations are significant to design new DCNN liked models for analyzing and understanding remote sensing images.