 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtoHPE: Prototype-guided High-frequency Patch Enhancement for Visible-Infrared Person Re-identification
Paper and Code
Oct 11, 2023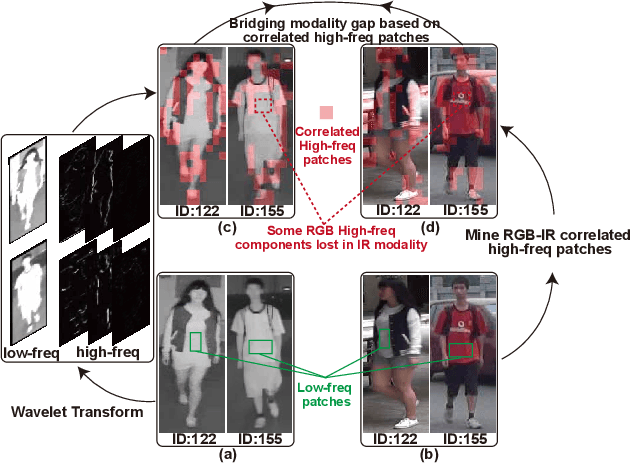
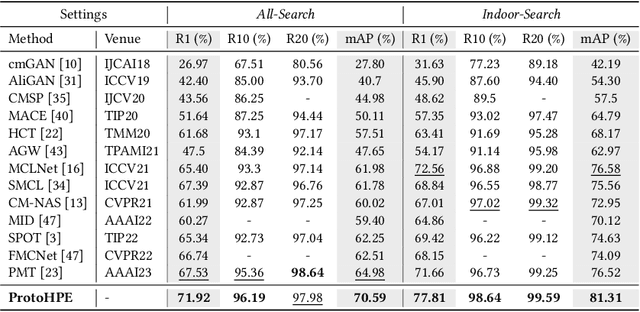
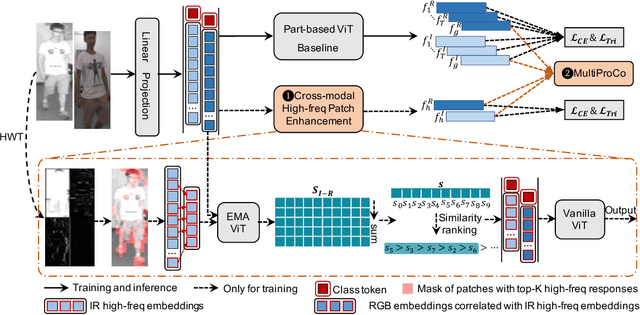
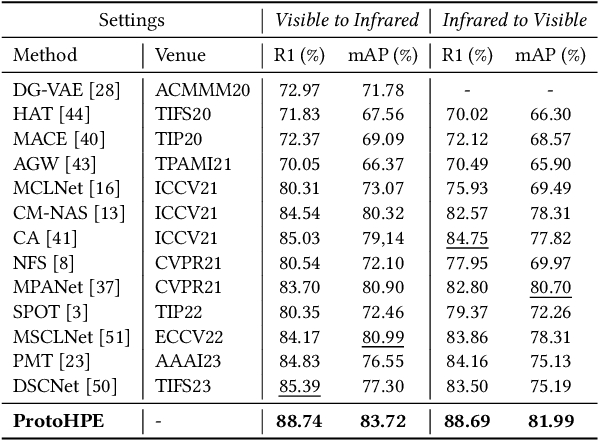
Visible-infrared person re-identification is challenging due to the large modality gap. To bridge the gap, most studies heavily rely on the correlation of visible-infrared holistic person images, which may perform poorly under severe distribution shifts. In contrast, we find that some cross-modal correlated high-frequency components contain discriminative visual patterns and are less affected by variations such as wavelength, pose, and background clutter than holistic images. Therefore, we are motivated to bridge the modality gap based on such high-frequency components, and propose \textbf{Proto}type-guided \textbf{H}igh-frequency \textbf{P}atch \textbf{E}nhancement (ProtoHPE) with two core designs. \textbf{First}, to enhance the representation ability of cross-modal correlated high-frequency components, we split patches with such components by Wavelet Transform and exponential moving average Vision Transformer (ViT), then empower ViT to take the split patches as auxiliary input. \textbf{Second}, to obtain semantically compact and discriminative high-frequency representations of the same identity, we propose Multimodal Prototypical Contrast. To be specific, it hierarchically captures the comprehensive semantics of different modal instances, facilitating the aggregation of high-frequency representations belonging to the same identity. With it, ViT can capture key high-frequency components during inference without relying on ProtoHPE, thus bringing no extra complexity. Extensive experiments validate the effectiveness of ProtoHPE.