 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLLMReID: Multimodal Large Language Model-based Person Re-identification
Jan 24, 2024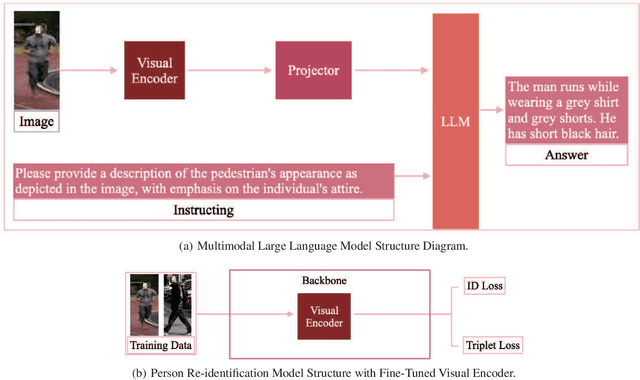
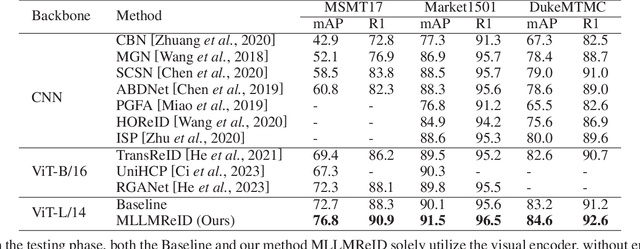
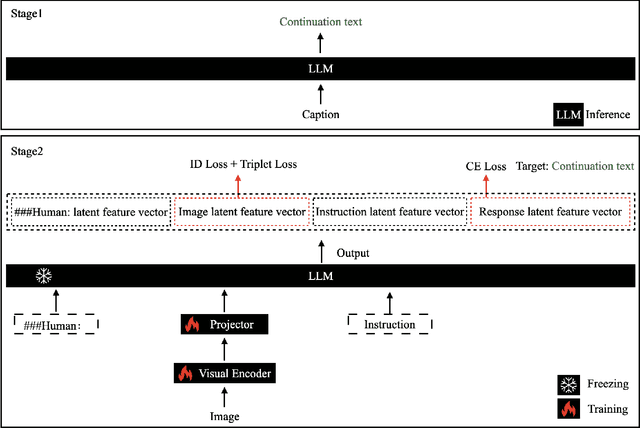

Multimodal large language models (MLLM) have achieved satisfactory results in many tasks. However, their performance in the task of person re-identification (ReID) has not been explored to date. This paper will investigate how to adapt them for the task of ReID. An intuitive idea is to fine-tune MLLM with ReID image-text datasets, and then use their visual encoder as a backbone for ReID. However, there still exist two apparent issues: (1) Designing instructions for ReID, MLLMs may overfit specific instructions, and designing a variety of instructions will lead to higher costs. (2) Latent image feature vectors from LLMs are not involved in loss computation. Instructional learning, aligning image-text features, results in indirect optimization and a learning objective that inadequately utilizes features, limiting effectiveness in person feature learning. To address these problems, this paper proposes MLLMReID: Multimodal Large Language Model-based ReID. Firstly, we proposed Common Instruction, a simple approach that leverages the essence ability of LLMs to continue writing, avoiding complex and diverse instruction design. Secondly, we proposed DirectReID, which effectively employs the latent image feature vectors of images outputted by LLMs in ReID tasks. The experimental results demonstrate the superiority of our method. We will open-source the code on GitHub.
ProtoHPE: Prototype-guided High-frequency Patch Enhancement for Visible-Infrared Person Re-identification
Oct 11, 2023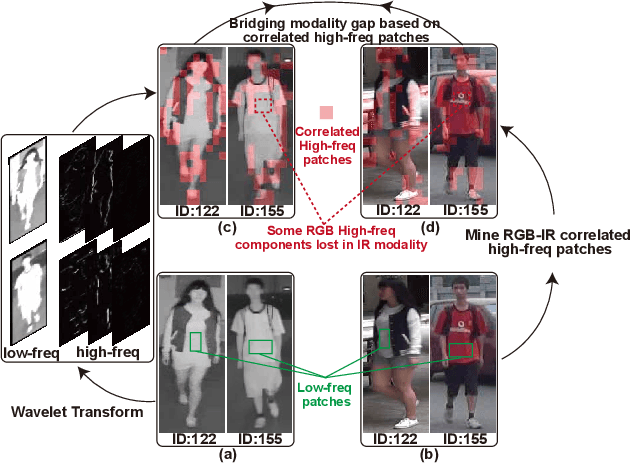
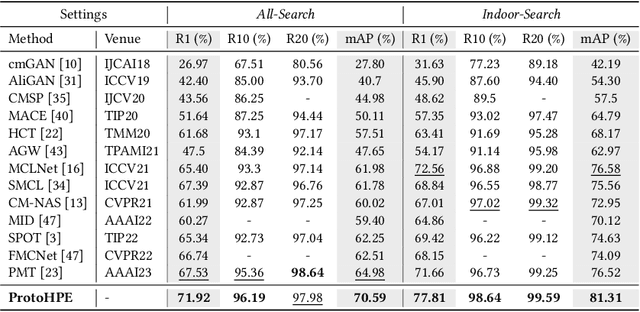
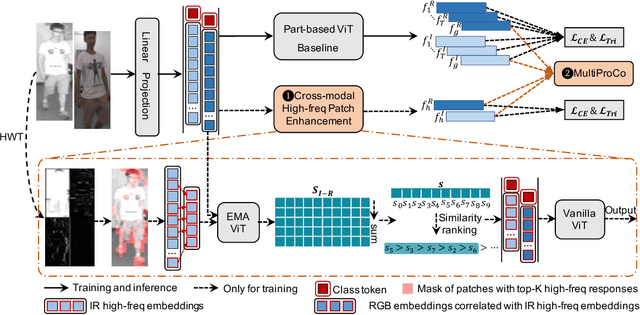
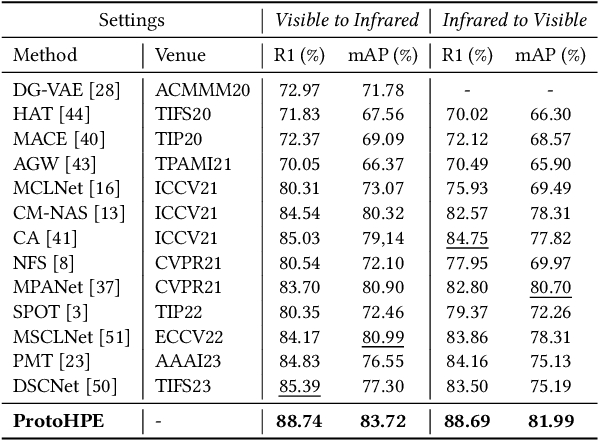
Visible-infrared person re-identification is challenging due to the large modality gap. To bridge the gap, most studies heavily rely on the correlation of visible-infrared holistic person images, which may perform poorly under severe distribution shifts. In contrast, we find that some cross-modal correlated high-frequency components contain discriminative visual patterns and are less affected by variations such as wavelength, pose, and background clutter than holistic images. Therefore, we are motivated to bridge the modality gap based on such high-frequency components, and propose \textbf{Proto}type-guided \textbf{H}igh-frequency \textbf{P}atch \textbf{E}nhancement (ProtoHPE) with two core designs. \textbf{First}, to enhance the representation ability of cross-modal correlated high-frequency components, we split patches with such components by Wavelet Transform and exponential moving average Vision Transformer (ViT), then empower ViT to take the split patches as auxiliary input. \textbf{Second}, to obtain semantically compact and discriminative high-frequency representations of the same identity, we propose Multimodal Prototypical Contrast. To be specific, it hierarchically captures the comprehensive semantics of different modal instances, facilitating the aggregation of high-frequency representations belonging to the same identity. With it, ViT can capture key high-frequency components during inference without relying on ProtoHPE, thus bringing no extra complexity. Extensive experiments validate the effectiveness of ProtoHPE.
CAKE: A Scalable Commonsense-Aware Framework For Multi-View Knowledge Graph Completion
Mar 08, 2022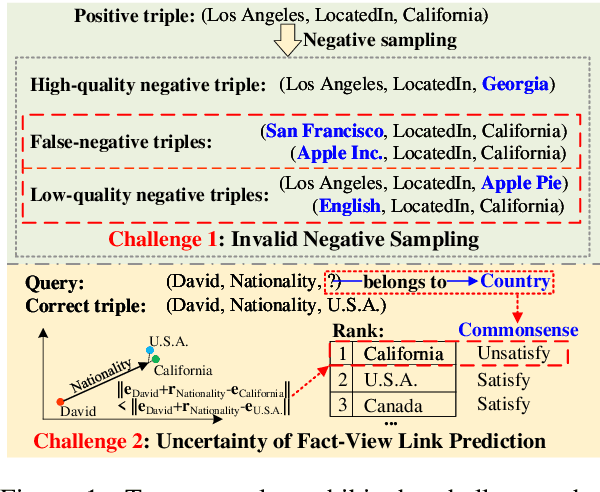
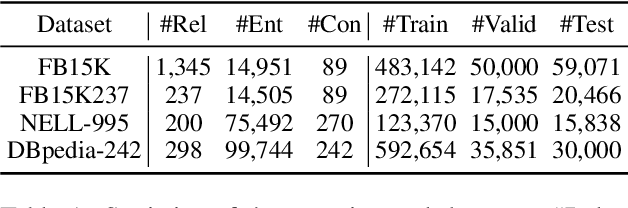
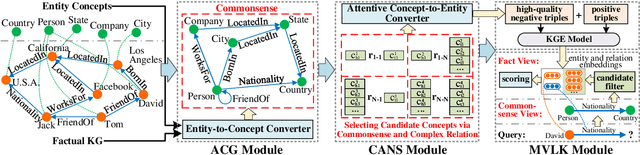
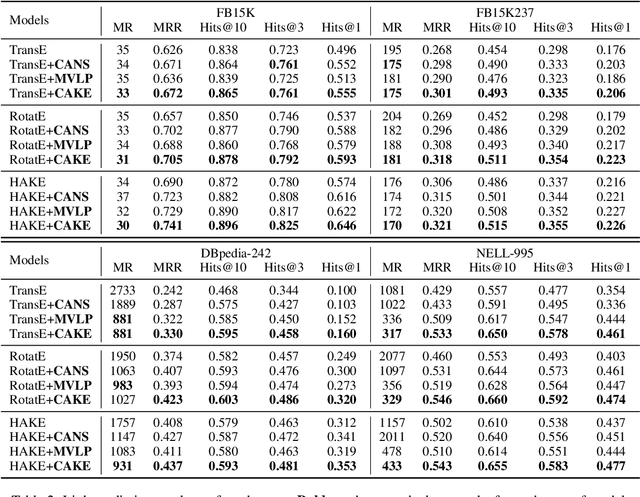
Knowledge graphs store a large number of factual triples while they are still incomplete, inevitably. The previous knowledge graph completion (KGC) models predict missing links between entities merely relying on fact-view data, ignoring the valuable commonsense knowledge. The previous knowledge graph embedding (KGE) techniques suffer from invalid negative sampling and the uncertainty of fact-view link prediction, limiting KGC's performance. To address the above challenges, we propose a novel and scalable Commonsense-Aware Knowledge Embedding (CAKE) framework to automatically extract commonsense from factual triples with entity concepts. The generated commonsense augments effective self-supervision to facilitate both high-quality negative sampling (NS) and joint commonsense and fact-view link prediction. Experimental results on the KGC task demonstrate that assembling our framework could enhance the performance of the original KGE models, and the proposed commonsense-aware NS module is superior to other NS techniques. Besides, our proposed framework could be easily adaptive to various KGE models and explain the predicted results.
EngineKGI: Closed-Loop Knowledge Graph Inference
Dec 02, 2021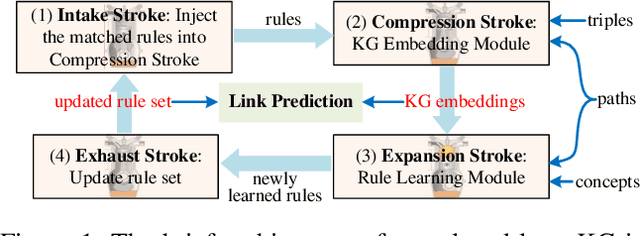
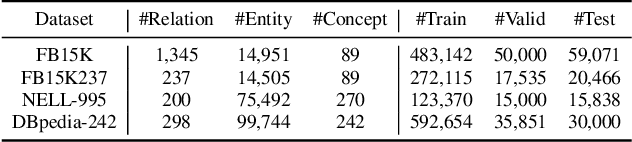
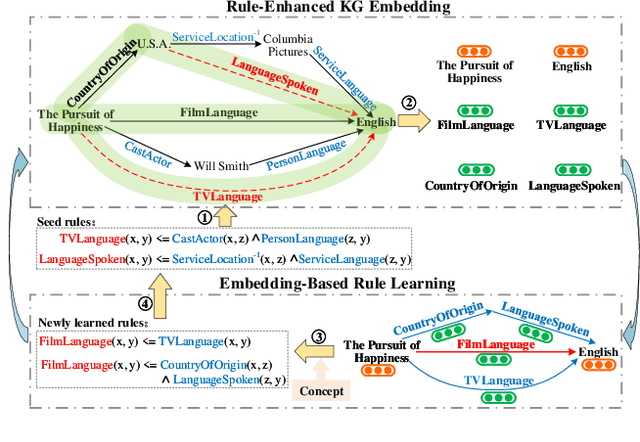
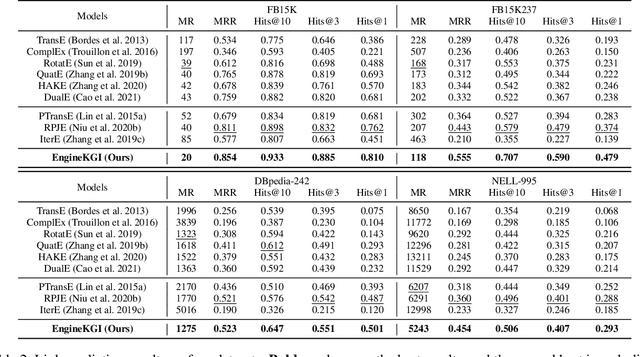
Knowledge Graph (KG) inference is the vital technique to address the natural incompleteness of KGs. The existing KG inference approaches can be classified into rule learning-based and KG embedding-based models. However, these approaches cannot well balance accuracy, generalization, interpretability and efficiency, simultaneously. Besides, these models always rely on pure triples and neglect additional information. Therefore, both KG embedding (KGE) and rule learning KG inference approaches face challenges due to the sparse entities and the limited semantics. We propose a novel and effective closed-loop KG inference framework EngineKGI operating similarly as an engine based on these observations. EngineKGI combines KGE and rule learning to complement each other in a closed-loop pattern while taking advantage of semantics in paths and concepts. KGE module exploits paths to enhance the semantic association between entities and introduces rules for interpretability. A novel rule pruning mechanism is proposed in the rule learning module by leveraging paths as initial candidate rules and employing KG embeddings together with concepts for extracting more high-quality rules. Experimental results on four real-world datasets show that our model outperforms other baselines on link prediction tasks, demonstrating the effectiveness and superiority of our model on KG inference in a joint logic and data-driven fashion with a closed-loop mechanism.
Entity Concept-enhanced Few-shot Relation Extraction
Jun 04, 2021
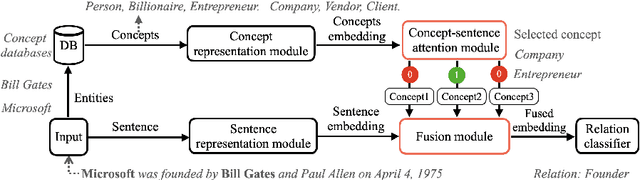

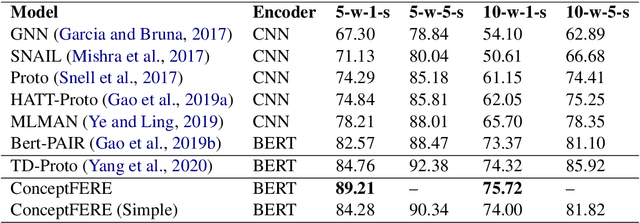
Few-shot relation extraction (FSRE) is of great importance in long-tail distribution problem, especially in special domain with low-resource data. Most existing FSRE algorithms fail to accurately classify the relations merely based on the information of the sentences together with the recognized entity pairs, due to limited samples and lack of knowledge. To address this problem, in this paper, we proposed a novel entity CONCEPT-enhanced FEw-shot Relation Extraction scheme (ConceptFERE), which introduces the inherent concepts of entities to provide clues for relation prediction and boost the relations classification performance. Firstly, a concept-sentence attention module is developed to select the most appropriate concept from multiple concepts of each entity by calculating the semantic similarity between sentences and concepts. Secondly, a self-attention based fusion module is presented to bridge the gap of concept embedding and sentence embedding from different semantic spaces. Extensive experiments on the FSRE benchmark dataset FewRel have demonstrated the effectiveness and the superiority of the proposed ConceptFERE scheme as compared to the state-of-the-art baselines. Code is available at https://github.com/LittleGuoKe/ConceptFERE.
Spatiotemporal Transformer for Video-based Person Re-identification
Mar 30, 2021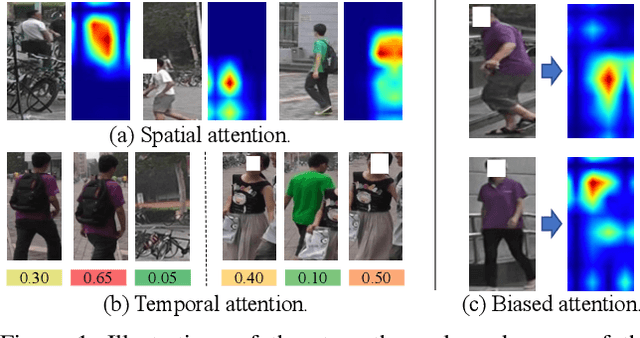
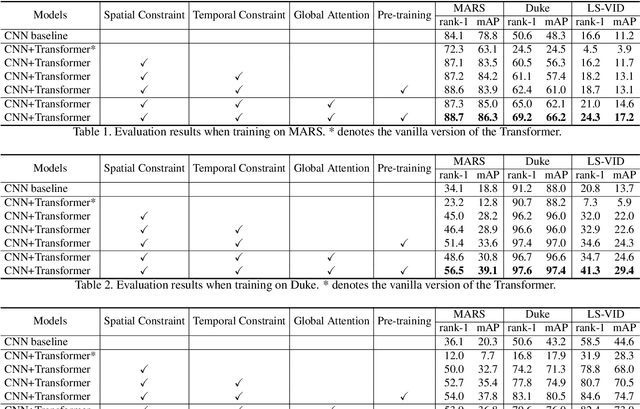
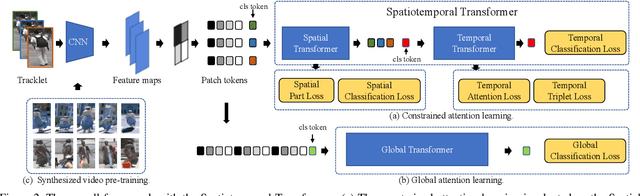
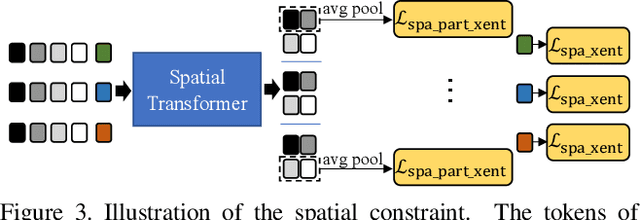
Recently, the Transformer module has been transplanted from natural language processing to computer vision. This paper applies the Transformer to video-based person re-identification, where the key issue is to extract the discriminative information from a tracklet. We show that, despite the strong learning ability, the vanilla Transformer suffers from an increased risk of over-fitting, arguably due to a large number of attention parameters and insufficient training data. To solve this problem, we propose a novel pipeline where the model is pre-trained on a set of synthesized video data and then transferred to the downstream domains with the perception-constrained Spatiotemporal Transformer (STT) module and Global Transformer (GT) module. The derived algorithm achieves significant accuracy gain on three popular video-based person re-identification benchmarks, MARS, DukeMTMC-VideoReID, and LS-VID, especially when the training and testing data are from different domains. More importantly, our research sheds light on the application of the Transformer on highly-structured visual data.
UnrealPerson: An Adaptive Pipeline towards Costless Person Re-identification
Dec 09, 2020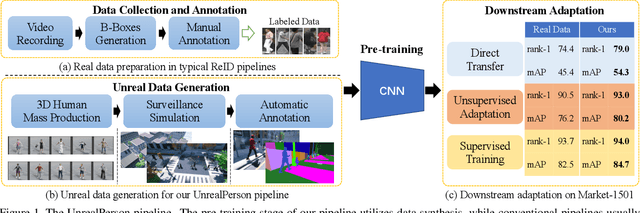

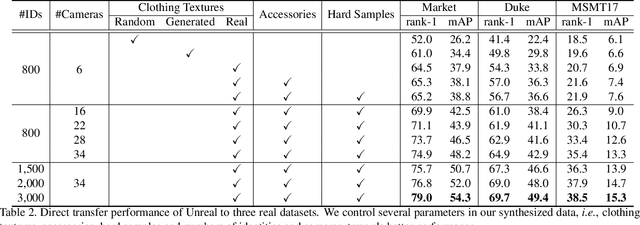

The main difficulty of person re-identification (ReID) lies in collecting annotated data and transferring the model across different domains. This paper presents UnrealPerson, a novel pipeline that makes full use of unreal image data to decrease the costs in both the training and deployment stages. Its fundamental part is a system that can generate synthesized images of high-quality and from controllable distributions. Instance-level annotation goes with the synthesized data and is almost free. We point out some details in image synthesis that largely impact the data quality. With 3,000 IDs and 120,000 instances, our method achieves a 38.5% rank-1 accuracy when being directly transferred to MSMT17. It almost doubles the former record using synthesized data and even surpasses previous direct transfer records using real data. This offers a good basis for unsupervised domain adaption, where our pre-trained model is easily plugged into the state-of-the-art algorithms towards higher accuracy. In addition, the data distribution can be flexibly adjusted to fit some corner ReID scenarios, which widens the application of our pipeline. We will publish our data synthesis toolkit and synthesized data in https://github.com/FlyHighest/UnrealPerson.
AutoETER: Automated Entity Type Representation for Knowledge Graph Embedding
Oct 06, 2020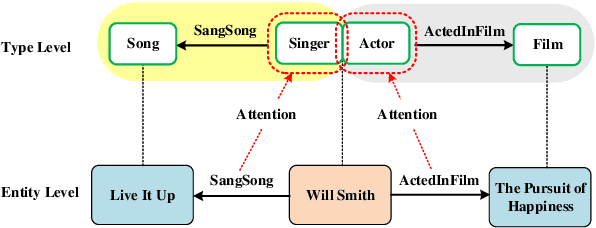
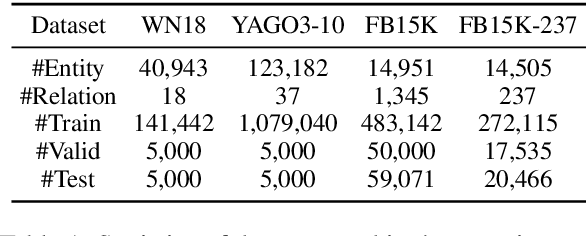
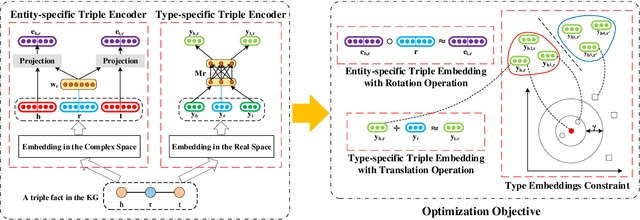
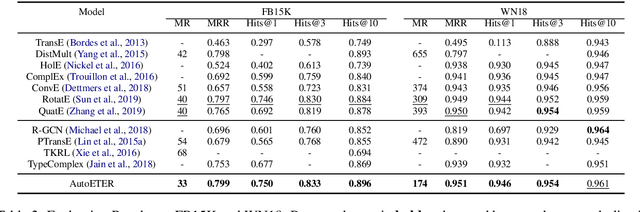
Recent advances in Knowledge Graph Embedding (KGE) allow for representing entities and relations in continuous vector spaces. Some traditional KGE models leveraging additional type information can improve the representation of entities which however totally rely on the explicit types or neglect the diverse type representations specific to various relations. Besides, none of the existing methods is capable of inferring all the relation patterns of symmetry, inversion and composition as well as the complex properties of 1-N, N-1 and N-N relations, simultaneously. To explore the type information for any KG, we develop a novel KGE framework with Automated Entity TypE Representation (AutoETER), which learns the latent type embedding of each entity by regarding each relation as a translation operation between the types of two entities with a relation-aware projection mechanism. Particularly, our designed automated type representation learning mechanism is a pluggable module which can be easily incorporated with any KGE model. Besides, our approach could model and infer all the relation patterns and complex relations. Experiments on four datasets demonstrate the superior performance of our model compared to state-of-the-art baselines on link prediction tasks, and the visualization of type clustering provides clearly the explanation of type embeddings and verifies the effectiveness of our model.
Joint Semantics and Data-Driven Path Representation for Knowledge Graph Inference
Oct 06, 2020

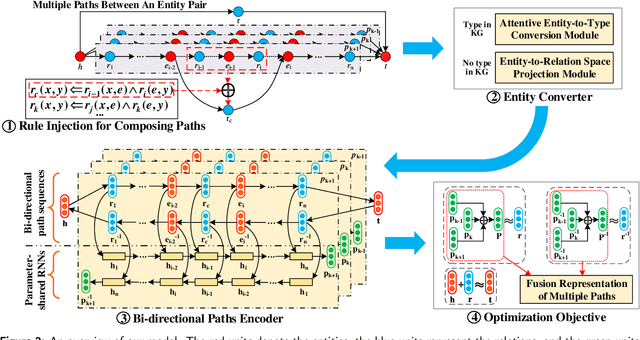
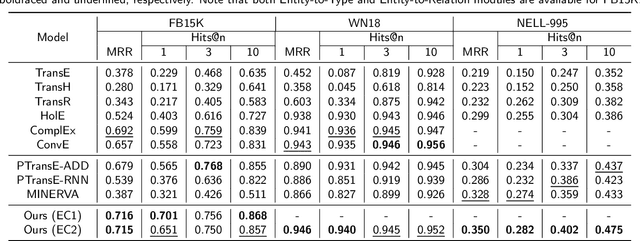
Inference on a large-scale knowledge graph (KG) is of great importance for KG applications like question answering. The path-based reasoning models can leverage much information over paths other than pure triples in the KG, which face several challenges: all the existing path-based methods are data-driven, lacking explainability for path representation. Besides, some methods either consider only relational paths or ignore the heterogeneity between entities and relations both contained in paths, which cannot capture the rich semantics of paths well. To address the above challenges, in this work, we propose a novel joint semantics and data-driven path representation that balances explainability and generalization in the framework of KG embedding. More specifically, we inject horn rules to obtain the condensed paths by the transparent and explainable path composition procedure. The entity converter is designed to transform the entities along paths into the representations in the semantic level similar to relations for reducing the heterogeneity between entities and relations, in which the KGs both with and without type information are considered. Our proposed model is evaluated on two classes of tasks: link prediction and path query answering task. The experimental results show that it has a significant performance gain over several different state-of-the-art baselines.
Rule-Guided Compositional Representation Learning on Knowledge Graphs
Dec 28, 2019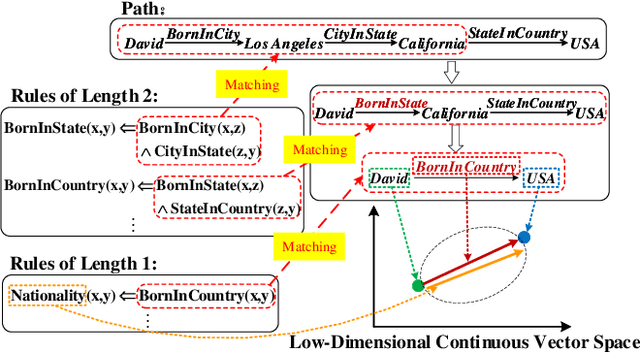
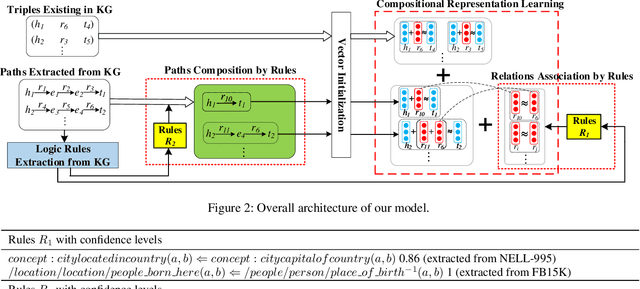
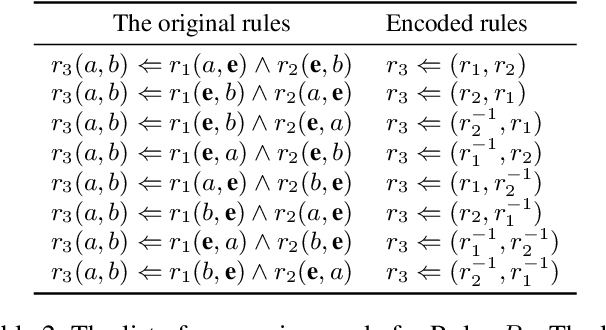
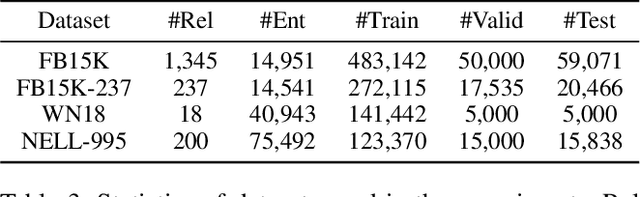
Representation learning on a knowledge graph (KG) is to embed entities and relations of a KG into low-dimensional continuous vector spaces. Early KG embedding methods only pay attention to structured information encoded in triples, which would cause limited performance due to the structure sparseness of KGs. Some recent attempts consider paths information to expand the structure of KGs but lack explainability in the process of obtaining the path representations. In this paper, we propose a novel Rule and Path-based Joint Embedding (RPJE) scheme, which takes full advantage of the explainability and accuracy of logic rules, the generalization of KG embedding as well as the supplementary semantic structure of paths. Specifically, logic rules of different lengths (the number of relations in rule body) in the form of Horn clauses are first mined from the KG and elaborately encoded for representation learning. Then, the rules of length 2 are applied to compose paths accurately while the rules of length 1 are explicitly employed to create semantic associations among relations and constrain relation embeddings. Besides, the confidence level of each rule is also considered in optimization to guarantee the availability of applying the rule to representation learning. Extensive experimental results illustrate that RPJE outperforms other state-of-the-art baselines on KG completion task, which also demonstrate the superiority of utilizing logic rules as well as paths for improving the accuracy and explainability of representation learning.