 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Layer-wise Analysis of Supervised Fine-Tuning
Apr 12, 2026While critical for alignment, Supervised Fine-Tuning (SFT) incurs the risk of catastrophic forgetting, yet the layer-wise emergence of instruction-following capabilities remains elusive. We investigate this mechanism via a comprehensive analysis utilizing information-theoretic, geometric, and optimization metrics across model scales (1B-32B). Our experiments reveal a distinct depth-dependent pattern: middle layers (20\%-80\%) are stable, whereas final layers exhibit high sensitivity. Leveraging this insight, we propose Mid-Block Efficient Tuning, which selectively updates these critical intermediate layers. Empirically, our method outperforms standard LoRA up to 10.2\% on GSM8K (OLMo2-7B) with reduced parameter overhead, demonstrating that effective alignment is architecturally localized rather than distributed. The code is publicly available at https://anonymous.4open.science/r/base_sft.
REMA: A Unified Reasoning Manifold Framework for Interpreting Large Language Model
Sep 26, 2025Understanding how Large Language Models (LLMs) perform complex reasoning and their failure mechanisms is a challenge in interpretability research. To provide a measurable geometric analysis perspective, we define the concept of the Reasoning Manifold, a latent low-dimensional geometric structure formed by the internal representations corresponding to all correctly reasoned generations. This structure can be conceptualized as the embodiment of the effective thinking paths that the model has learned to successfully solve a given task. Based on this concept, we build REMA, a framework that explains the origins of failures by quantitatively comparing the spatial relationships of internal model representations corresponding to both erroneous and correct reasoning samples. Specifically, REMA first quantifies the geometric deviation of each erroneous representation by calculating its k-nearest neighbors distance to the approximated manifold formed by correct representations, thereby providing a unified failure signal. It then localizes the divergence points where these deviations first become significant by tracking this deviation metric across the model's layers and comparing it against a baseline of internal fluctuations from correct representations, thus identifying where the reasoning chain begins to go off-track. Our extensive experiments on diverse language and multimodal models and tasks demonstrate the low-dimensional nature of the reasoning manifold and the high separability between erroneous and correct reasoning representations. The results also validate the effectiveness of the REMA framework in analyzing the origins of reasoning failures. This research connects abstract reasoning failures to measurable geometric deviations in representations, providing new avenues for in-depth understanding and diagnosis of the internal computational processes of black-box models.
How Chain-of-Thought Works? Tracing Information Flow from Decoding, Projection, and Activation
Jul 28, 2025Chain-of-Thought (CoT) prompting significantly enhances model reasoning, yet its internal mechanisms remain poorly understood. We analyze CoT's operational principles by reversely tracing information flow across decoding, projection, and activation phases. Our quantitative analysis suggests that CoT may serve as a decoding space pruner, leveraging answer templates to guide output generation, with higher template adherence strongly correlating with improved performance. Furthermore, we surprisingly find that CoT modulates neuron engagement in a task-dependent manner: reducing neuron activation in open-domain tasks, yet increasing it in closed-domain scenarios. These findings offer a novel mechanistic interpretability framework and critical insights for enabling targeted CoT interventions to design more efficient and robust prompts. We released our code and data at https://anonymous.4open.science/r/cot-D247.
Extending Memorization Dynamics in Pythia Models from Instance-Level Insights
Jun 14, 2025Large language models have demonstrated a remarkable ability for verbatim memorization. While numerous works have explored factors influencing model memorization, the dynamic evolution memorization patterns remains underexplored. This paper presents a detailed analysis of memorization in the Pythia model family across varying scales and training steps under prefix perturbations. Using granular metrics, we examine how model architecture, data characteristics, and perturbations influence these patterns. Our findings reveal that: (1) as model scale increases, memorization expands incrementally while efficiency decreases rapidly; (2) as model scale increases, the rate of new memorization acquisition decreases while old memorization forgetting increases; (3) data characteristics (token frequency, repetition count, and uncertainty) differentially affect memorized versus non-memorized samples; and (4) prefix perturbations reduce memorization and increase generation uncertainty proportionally to perturbation strength, with low-redundancy samples showing higher vulnerability and larger models offering no additional robustness. These findings advance our understanding of memorization mechanisms, with direct implications for training optimization, privacy safeguards, and architectural improvements.
Reassessing the Role of Chain-of-Thought in Sentiment Analysis: Insights and Limitations
Jan 15, 2025



The relationship between language and thought remains an unresolved philosophical issue. Existing viewpoints can be broadly categorized into two schools: one asserting their independence, and another arguing that language constrains thought. In the context of large language models, this debate raises a crucial question: Does a language model's grasp of semantic meaning depend on thought processes? To explore this issue, we investigate whether reasoning techniques can facilitate semantic understanding. Specifically, we conceptualize thought as reasoning, employ chain-of-thought prompting as a reasoning technique, and examine its impact on sentiment analysis tasks. The experiments show that chain-of-thought has a minimal impact on sentiment analysis tasks. Both the standard and chain-of-thought prompts focus on aspect terms rather than sentiment in the generated content. Furthermore, counterfactual experiments reveal that the model's handling of sentiment tasks primarily depends on information from demonstrations. The experimental results support the first viewpoint.
Word Order's Impacts: Insights from Reordering and Generation Analysis
Mar 18, 2024Existing works have studied the impacts of the order of words within natural text. They usually analyze it by destroying the original order of words to create a scrambled sequence, and then comparing the models' performance between the original and scrambled sequences. The experimental results demonstrate marginal drops. Considering this findings, different hypothesis about word order is proposed, including ``the order of words is redundant with lexical semantics'', and ``models do not rely on word order''. In this paper, we revisit the aforementioned hypotheses by adding a order reconstruction perspective, and selecting datasets of different spectrum. Specifically, we first select four different datasets, and then design order reconstruction and continuing generation tasks. Empirical findings support that ChatGPT relies on word order to infer, but cannot support or negate the redundancy relations between word order lexical semantics.
ROME: Memorization Insights from Text, Probability and Hidden State in Large Language Models
Mar 04, 2024Probing the memorization of large language models holds significant importance. Previous works have established metrics for quantifying memorization, explored various influencing factors, such as data duplication, model size, and prompt length, and evaluated memorization by comparing model outputs with training corpora. However, the training corpora are of enormous scale and its pre-processing is time-consuming. To explore memorization without accessing training data, we propose a novel approach, named ROME, wherein memorization is explored by comparing disparities across memorized and non-memorized. Specifically, models firstly categorize the selected samples into memorized and non-memorized groups, and then comparing the demonstrations in the two groups from the insights of text, probability, and hidden state. Experimental findings show the disparities in factors including word length, part-of-speech, word frequency, mean and variance, just to name a few.
Word Order and World Knowledge
Mar 01, 2024



Word order is an important concept in natural language, and in this work, we study how word order affects the induction of world knowledge from raw text using language models. We use word analogies to probe for such knowledge. Specifically, in addition to the natural word order, we first respectively extract texts of six fixed word orders from five languages and then pretrain the language models on these texts. Finally, we analyze the experimental results of the fixed word orders on word analogies and show that i) certain fixed word orders consistently outperform or underperform others, though the specifics vary across languages, and ii) the Wov2Lex hypothesis is not hold in pre-trained language models, and the natural word order typically yields mediocre results. The source code will be made publicly available at https://github.com/lshowway/probing_by_analogy.
Effects of Tonal Coarticulation and Prosodic Positions on Tonal Contours of Low Rising Tones: In the Case of Xiamen Dialect
Jun 04, 2023



Few studies have worked on the effects of tonal coarticulation and prosodic positions on the low rising tone in Xiamen Dialect. This study addressed such an issue. To do so, a new method, the Tonal Contour Analysis in Tonal Triangle, was proposed to measure the subtle curvature of the tonal contour. Findings are as follows: (1) The low rising tone in Xiamen Dialect has a tendency towards the falling-rising tone, which is significantly affected by the tonal coarticulation and prosodic positions. (2) The low rising tone presents as a falling-rising tone when preceded by a tone with a high offset, and as a low rising tone when preceded by a tone that ends up low. (3) The curvature of the low rising tone is greatest in the sentence-initial position, and is positively correlated to its own duration.
Ered: Enhanced Text Representations with Entities and Descriptions
Aug 18, 2022
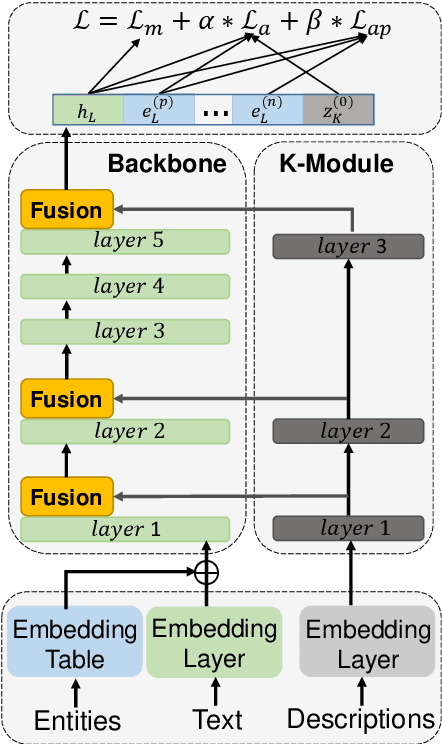
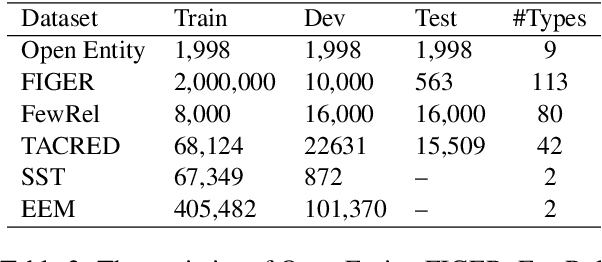
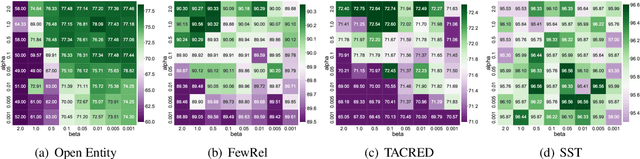
External knowledge,e.g., entities and entity descriptions, can help humans understand texts. Many works have been explored to include external knowledge in the pre-trained models. These methods, generally, design pre-training tasks and implicitly introduce knowledge by updating model weights, alternatively, use it straightforwardly together with the original text. Though effective, there are some limitations. On the one hand, it is implicit and only model weights are paid attention to, the pre-trained entity embeddings are ignored. On the other hand, entity descriptions may be lengthy, and inputting into the model together with the original text may distract the model's attention. This paper aims to explicitly include both entities and entity descriptions in the fine-tuning stage. First, the pre-trained entity embeddings are fused with the original text representation and updated by the backbone model layer by layer. Second, descriptions are represented by the knowledge module outside the backbone model, and each knowledge layer is selectively connected to one backbone layer for fusing. Third, two knowledge-related auxiliary tasks, i.e., entity/description enhancement and entity enhancement/pollution task, are designed to smooth the semantic gaps among evolved representations. We conducted experiments on four knowledge-oriented tasks and two common tasks, and the results achieved new state-of-the-art on several datasets. Besides, we conduct an ablation study to show that each module in our method is necessary. The code is available at https://github.com/lshowway/Ered.