 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial-R1: Towards Human-like Social Reasoning in LLMs
Mar 10, 2026While large language models demonstrate remarkable capabilities across numerous domains, social intelligence - the capacity to perceive social cues, infer mental states, and generate appropriate responses - remains a critical challenge, particularly for enabling effective human-AI collaboration and developing AI that truly serves human needs. Current models often rely on superficial patterns rather than genuine social reasoning. We argue that cultivating human-like social intelligence requires training with challenging cases that resist shortcut solutions. To this end, we introduce ToMBench-Hard, an adversarial benchmark designed to provide hard training examples for social reasoning. Building on this, we propose Social-R1, a reinforcement learning framework that aligns model reasoning with human cognition through multi-dimensional rewards. Unlike outcome-based RL, Social-R1 supervises the entire reasoning process, enforcing structural alignment, logical integrity, and information density. Results show that our approach enables a 4B parameter model to surpass much larger counterparts and generalize robustly across eight diverse benchmarks. These findings demonstrate that challenging training cases with trajectory-level alignment offer a path toward efficient and reliable social intelligence.
HumanLLM: Towards Personalized Understanding and Simulation of Human Nature
Jan 22, 2026Motivated by the remarkable progress of large language models (LLMs) in objective tasks like mathematics and coding, there is growing interest in their potential to simulate human behavior--a capability with profound implications for transforming social science research and customer-centric business insights. However, LLMs often lack a nuanced understanding of human cognition and behavior, limiting their effectiveness in social simulation and personalized applications. We posit that this limitation stems from a fundamental misalignment: standard LLM pretraining on vast, uncontextualized web data does not capture the continuous, situated context of an individual's decisions, thoughts, and behaviors over time. To bridge this gap, we introduce HumanLLM, a foundation model designed for personalized understanding and simulation of individuals. We first construct the Cognitive Genome Dataset, a large-scale corpus curated from real-world user data on platforms like Reddit, Twitter, Blogger, and Amazon. Through a rigorous, multi-stage pipeline involving data filtering, synthesis, and quality control, we automatically extract over 5.5 million user logs to distill rich profiles, behaviors, and thinking patterns. We then formulate diverse learning tasks and perform supervised fine-tuning to empower the model to predict a wide range of individualized human behaviors, thoughts, and experiences. Comprehensive evaluations demonstrate that HumanLLM achieves superior performance in predicting user actions and inner thoughts, more accurately mimics user writing styles and preferences, and generates more authentic user profiles compared to base models. Furthermore, HumanLLM shows significant gains on out-of-domain social intelligence benchmarks, indicating enhanced generalization.
Large Vision-Language Models as Emotion Recognizers in Context Awareness
Jul 16, 2024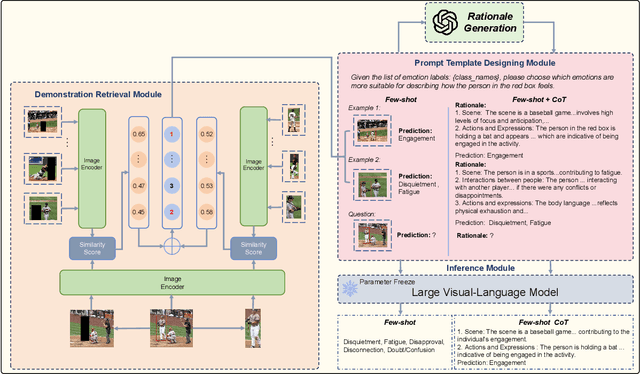
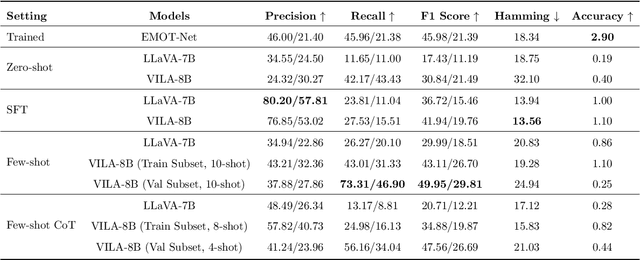

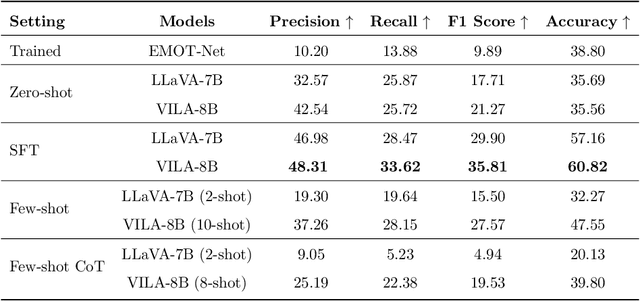
Context-aware emotion recognition (CAER) is a complex and significant task that requires perceiving emotions from various contextual cues. Previous approaches primarily focus on designing sophisticated architectures to extract emotional cues from images. However, their knowledge is confined to specific training datasets and may reflect the subjective emotional biases of the annotators. Furthermore, acquiring large amounts of labeled data is often challenging in real-world applications. In this paper, we systematically explore the potential of leveraging Large Vision-Language Models (LVLMs) to empower the CAER task from three paradigms: 1) We fine-tune LVLMs on two CAER datasets, which is the most common way to transfer large models to downstream tasks. 2) We design zero-shot and few-shot patterns to evaluate the performance of LVLMs in scenarios with limited data or even completely unseen. In this case, a training-free framework is proposed to fully exploit the In-Context Learning (ICL) capabilities of LVLMs. Specifically, we develop an image similarity-based ranking algorithm to retrieve examples; subsequently, the instructions, retrieved examples, and the test example are combined to feed LVLMs to obtain the corresponding sentiment judgment. 3) To leverage the rich knowledge base of LVLMs, we incorporate Chain-of-Thought (CoT) into our framework to enhance the model's reasoning ability and provide interpretable results. Extensive experiments and analyses demonstrate that LVLMs achieve competitive performance in the CAER task across different paradigms. Notably, the superior performance in few-shot settings indicates the feasibility of LVLMs for accomplishing specific tasks without extensive training.
Skip and Skip: Segmenting Medical Images with Prompts
Jun 21, 2024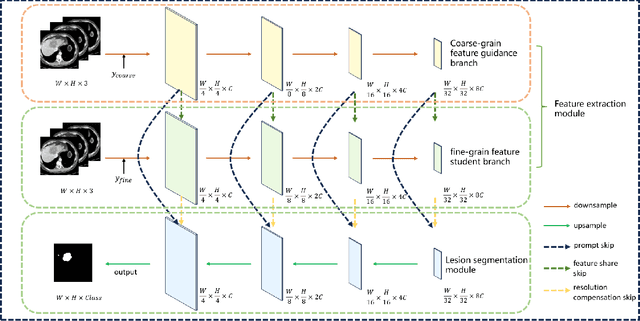
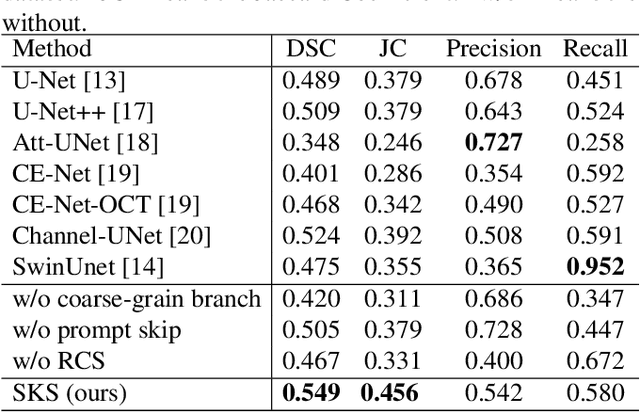

Most medical image lesion segmentation methods rely on hand-crafted accurate annotations of the original image for supervised learning. Recently, a series of weakly supervised or unsupervised methods have been proposed to reduce the dependence on pixel-level annotations. However, these methods are essentially based on pixel-level annotation, ignoring the image-level diagnostic results of the current massive medical images. In this paper, we propose a dual U-shaped two-stage framework that utilizes image-level labels to prompt the segmentation. In the first stage, we pre-train a classification network with image-level labels, which is used to obtain the hierarchical pyramid features and guide the learning of downstream branches. In the second stage, we feed the hierarchical features obtained from the classification branch into the downstream branch through short-skip and long-skip and get the lesion masks under the supervised learning of pixel-level labels. Experiments show that our framework achieves better results than networks simply using pixel-level annotations.
RecAI: Leveraging Large Language Models for Next-Generation Recommender Systems
Mar 11, 2024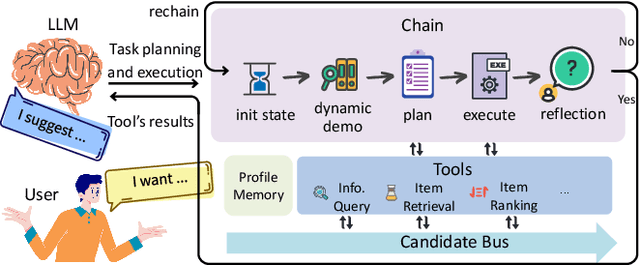
This paper introduces RecAI, a practical toolkit designed to augment or even revolutionize recommender systems with the advanced capabilities of Large Language Models (LLMs). RecAI provides a suite of tools, including Recommender AI Agent, Recommendation-oriented Language Models, Knowledge Plugin, RecExplainer, and Evaluator, to facilitate the integration of LLMs into recommender systems from multifaceted perspectives. The new generation of recommender systems, empowered by LLMs, are expected to be more versatile, explainable, conversational, and controllable, paving the way for more intelligent and user-centric recommendation experiences. We hope the open-source of RecAI can help accelerate evolution of new advanced recommender systems. The source code of RecAI is available at \url{https://github.com/microsoft/RecAI}.
Aligning Language Models for Versatile Text-based Item Retrieval
Feb 29, 2024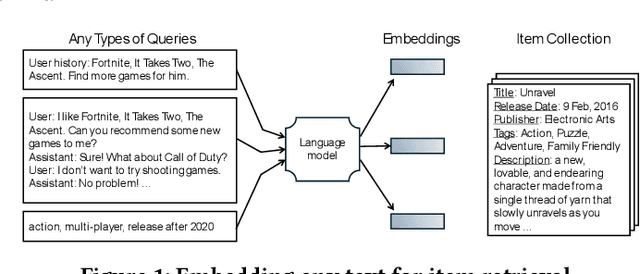
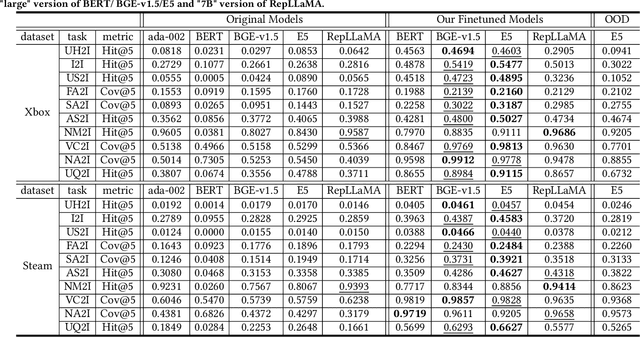


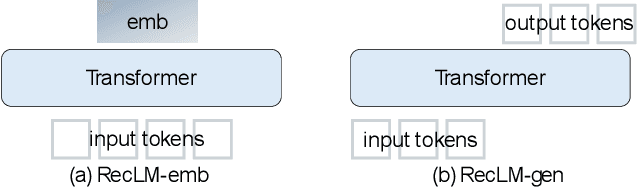
This paper addresses the gap between general-purpose text embeddings and the specific demands of item retrieval tasks. We demonstrate the shortcomings of existing models in capturing the nuances necessary for zero-shot performance on item retrieval tasks. To overcome these limitations, we propose generate in-domain dataset from ten tasks tailored to unlocking models' representation ability for item retrieval. Our empirical studies demonstrate that fine-tuning embedding models on the dataset leads to remarkable improvements in a variety of retrieval tasks. We also illustrate the practical application of our refined model in a conversational setting, where it enhances the capabilities of LLM-based Recommender Agents like Chat-Rec. Our code is available at https://github.com/microsoft/RecAI.
MISS: A Generative Pretraining and Finetuning Approach for Med-VQA
Jan 18, 2024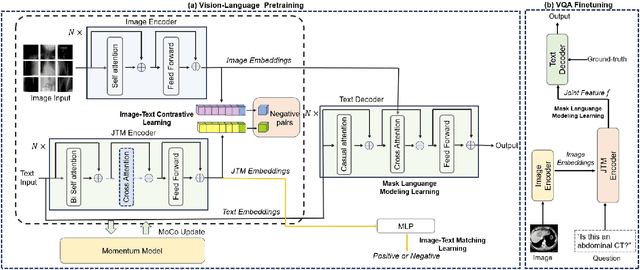
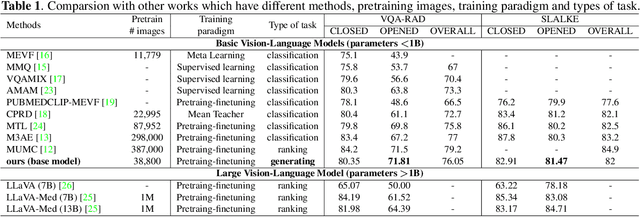
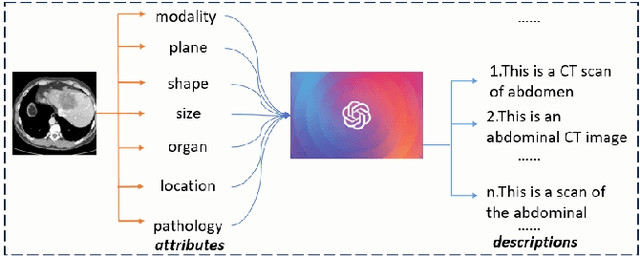
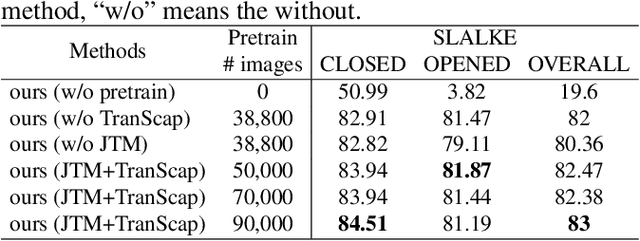
Medical visual question answering (VQA) is a challenging multimodal task, where Vision-Language Pre-training (VLP) models can effectively improve the generalization performance. However, most methods in the medical field treat VQA as an answer classification task which is difficult to transfer to practical application scenarios. Additionally, due to the privacy of medical images and the expensive annotation process, large-scale medical image-text pairs datasets for pretraining are severely lacking. In this paper, we propose a large-scale MultI-task Self-Supervised learning based framework (MISS) for medical VQA tasks. Unlike existing methods, we treat medical VQA as a generative task. We unify the text encoder and multimodal encoder and align image-text features through multi-task learning. Furthermore, we propose a Transfer-and-Caption method that extends the feature space of single-modal image datasets using large language models (LLMs), enabling those traditional medical vision field task data to be applied to VLP. Experiments show that our method achieves excellent results with fewer multimodal datasets and demonstrates the advantages of generative VQA models. The code and model weights will be released upon the paper's acceptance.
RecExplainer: Aligning Large Language Models for Recommendation Model Interpretability
Nov 18, 2023



Recommender systems are widely used in various online services, with embedding-based models being particularly popular due to their expressiveness in representing complex signals. However, these models often lack interpretability, making them less reliable and transparent for both users and developers. With the emergence of large language models (LLMs), we find that their capabilities in language expression, knowledge-aware reasoning, and instruction following are exceptionally powerful. Based on this, we propose a new model interpretation approach for recommender systems, by using LLMs as surrogate models and learn to mimic and comprehend target recommender models. Specifically, we introduce three alignment methods: behavior alignment, intention alignment, and hybrid alignment. Behavior alignment operates in the language space, representing user preferences and item information as text to learn the recommendation model's behavior; intention alignment works in the latent space of the recommendation model, using user and item representations to understand the model's behavior; hybrid alignment combines both language and latent spaces for alignment training. To demonstrate the effectiveness of our methods, we conduct evaluation from two perspectives: alignment effect, and explanation generation ability on three public datasets. Experimental results indicate that our approach effectively enables LLMs to comprehend the patterns of recommendation models and generate highly credible recommendation explanations.
Recommender AI Agent: Integrating Large Language Models for Interactive Recommendations
Sep 01, 2023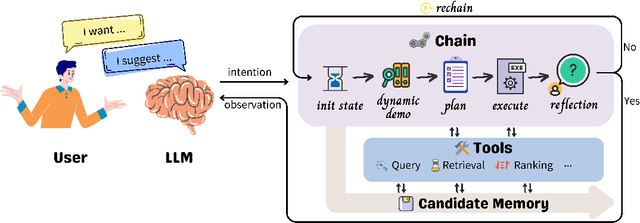
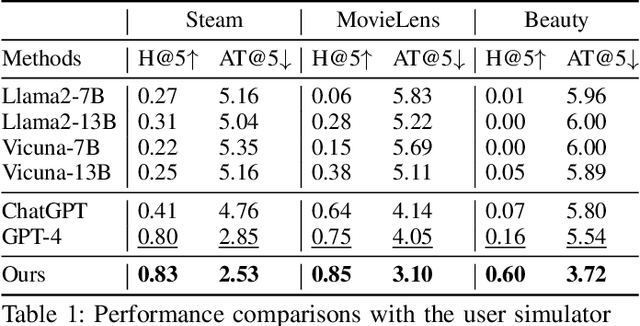
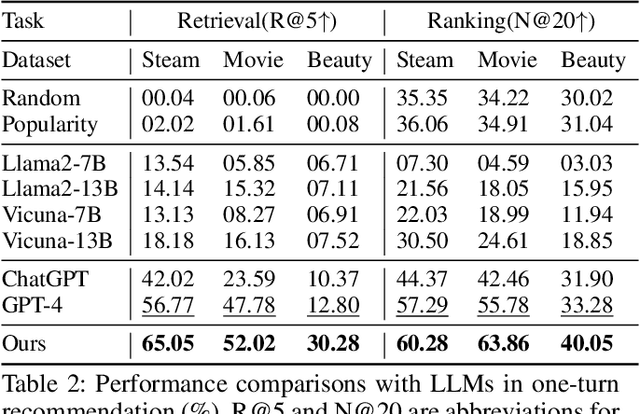
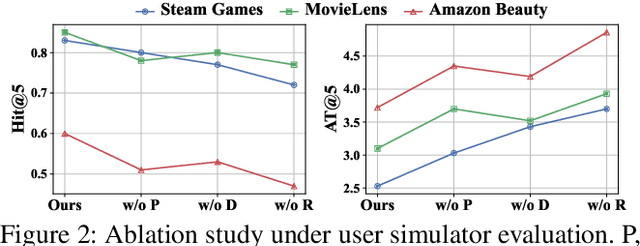
Recommender models excel at providing domain-specific item recommendations by leveraging extensive user behavior data. Despite their ability to act as lightweight domain experts, they struggle to perform versatile tasks such as providing explanations and engaging in conversations. On the other hand, large language models (LLMs) represent a significant step towards artificial general intelligence, showcasing remarkable capabilities in instruction comprehension, commonsense reasoning, and human interaction. However, LLMs lack the knowledge of domain-specific item catalogs and behavioral patterns, particularly in areas that diverge from general world knowledge, such as online e-commerce. Finetuning LLMs for each domain is neither economic nor efficient. In this paper, we bridge the gap between recommender models and LLMs, combining their respective strengths to create a versatile and interactive recommender system. We introduce an efficient framework called InteRecAgent, which employs LLMs as the brain and recommender models as tools. We first outline a minimal set of essential tools required to transform LLMs into InteRecAgent. We then propose an efficient workflow within InteRecAgent for task execution, incorporating key components such as a memory bus, dynamic demonstration-augmented task planning, and reflection. InteRecAgent enables traditional recommender systems, such as those ID-based matrix factorization models, to become interactive systems with a natural language interface through the integration of LLMs. Experimental results on several public datasets show that InteRecAgent achieves satisfying performance as a conversational recommender system, outperforming general-purpose LLMs.
When Large Language Models Meet Personalization: Perspectives of Challenges and Opportunities
Jul 31, 2023The advent of large language models marks a revolutionary breakthrough in artificial intelligence. With the unprecedented scale of training and model parameters, the capability of large language models has been dramatically improved, leading to human-like performances in understanding, language synthesizing, and common-sense reasoning, etc. Such a major leap-forward in general AI capacity will change the pattern of how personalization is conducted. For one thing, it will reform the way of interaction between humans and personalization systems. Instead of being a passive medium of information filtering, large language models present the foundation for active user engagement. On top of such a new foundation, user requests can be proactively explored, and user's required information can be delivered in a natural and explainable way. For another thing, it will also considerably expand the scope of personalization, making it grow from the sole function of collecting personalized information to the compound function of providing personalized services. By leveraging large language models as general-purpose interface, the personalization systems may compile user requests into plans, calls the functions of external tools to execute the plans, and integrate the tools' outputs to complete the end-to-end personalization tasks. Today, large language models are still being developed, whereas the application in personalization is largely unexplored. Therefore, we consider it to be the right time to review the challenges in personalization and the opportunities to address them with LLMs. In particular, we dedicate this perspective paper to the discussion of the following aspects: the development and challenges for the existing personalization system, the newly emerged capabilities of large language models, and the potential ways of making use of large language models for personalization.