 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKAT-Coder-V2 Technical Report
Mar 29, 2026We present KAT-Coder-V2, an agentic coding model developed by the KwaiKAT team at Kuaishou. KAT-Coder-V2 adopts a "Specialize-then-Unify" paradigm that decomposes agentic coding into five expert domains - SWE, WebCoding, Terminal, WebSearch, and General - each undergoing independent supervised fine-tuning and reinforcement learning, before being consolidated into a single model via on-policy distillation. We develop KwaiEnv, a modular infrastructure sustaining tens of thousands of concurrent sandbox instances, and scale RL training along task complexity, intent alignment, and scaffold generalization. We further propose MCLA for stabilizing MoE RL training and Tree Training for eliminating redundant computation over tree-structured trajectories with up to 6.2x speedup. KAT-Coder-V2 achieves 79.6% on SWE-bench Verified (vs. Claude Opus 4.6 at 80.8%), 88.7 on PinchBench (surpassing GLM-5 and MiniMax M2.7), ranks first across all three frontend aesthetics scenarios, and maintains strong generalist scores on Terminal-Bench Hard (46.8) and tau^2-Bench (93.9). Our model is publicly available at https://streamlake.com/product/kat-coder.
Why Self-Training Helps and Hurts: Denoising vs. Signal Forgetting
Feb 15, 2026Iterative self-training (self-distillation) repeatedly refits a model on pseudo-labels generated by its own predictions. We study this procedure in overparameterized linear regression: an initial estimator is trained on noisy labels, and each subsequent iterate is trained on fresh covariates with noiseless pseudo-labels from the previous model. In the high-dimensional regime, we derive deterministic-equivalent recursions for the prediction risk and effective noise across iterations, and prove that the empirical quantities concentrate sharply around these limits. The recursion separates two competing forces: a systematic component that grows with iteration due to progressive signal forgetting, and a stochastic component that decays due to denoising via repeated data-dependent projections. Their interaction yields a $U$-shaped test-risk curve and an optimal early-stopping time. In spiked covariance models, iteration further acts as an iteration-dependent spectral filter that preserves strong eigendirections while suppressing weaker ones, inducing an implicit form of soft feature selection distinct from ridge regression. Finally, we propose an iterated generalized cross-validation criterion and prove its uniform consistency for estimating the risk along the self-training trajectory, enabling fully data-driven selection of the stopping time and regularization. Experiments on synthetic covariances validate the theory and illustrate the predicted denoising-forgetting trade-off.
Which Reasoning Trajectories Teach Students to Reason Better? A Simple Metric of Informative Alignment
Jan 20, 2026Long chain-of-thought (CoT) trajectories provide rich supervision signals for distilling reasoning from teacher to student LLMs. However, both prior work and our experiments show that trajectories from stronger teachers do not necessarily yield better students, highlighting the importance of data-student suitability in distillation. Existing methods assess suitability primarily through student likelihood, favoring trajectories that closely align with the model's current behavior but overlooking more informative ones. Addressing this, we propose Rank-Surprisal Ratio (RSR), a simple metric that captures both alignment and informativeness to assess the suitability of a reasoning trajectory. RSR is motivated by the observation that effective trajectories typically combine low absolute probability with relatively high-ranked tokens under the student model, balancing learning signal strength and behavioral alignment. Concretely, RSR is defined as the ratio of a trajectory's average token-wise rank to its average negative log-likelihood, and is straightforward to compute and interpret. Across five student models and reasoning trajectories from 11 diverse teachers, RSR strongly correlates with post-training performance (average Spearman 0.86), outperforming existing metrics. We further demonstrate its practical utility in both trajectory selection and teacher selection.
Can Deep Research Agents Find and Organize? Evaluating the Synthesis Gap with Expert Taxonomies
Jan 18, 2026Deep Research Agents are increasingly used for automated survey generation. However, whether they can write surveys like human experts remains unclear. Existing benchmarks focus on fluency or citation accuracy, but none evaluates the core capabilities: retrieving essential papers and organizing them into coherent knowledge structures. We introduce TaxoBench, a diagnostic benchmark derived from 72 highly-cited computer science surveys. We manually extract expert-authored taxonomy trees containing 3,815 precisely categorized citations as ground truth. Our benchmark supports two evaluation modes: Deep Research mode tests end-to-end retrieval and organization given only a topic, while Bottom-Up mode isolates structuring capability by providing the exact papers human experts used. We evaluate 7 leading Deep Research agents and 12 frontier LLMs. Results reveal a dual bottleneck: the best agent recalls only 20.9% of expert-selected papers, and even with perfect input, the best model achieves only 0.31 ARI in organization. Current deep research agents remain far from expert-level survey writing. Our benchmark is publicly available at https://github.com/KongLongGeFDU/TaxoBench.
PCA++: How Uniformity Induces Robustness to Background Noise in Contrastive Learning
Nov 15, 2025High-dimensional data often contain low-dimensional signals obscured by structured background noise, which limits the effectiveness of standard PCA. Motivated by contrastive learning, we address the problem of recovering shared signal subspaces from positive pairs, paired observations sharing the same signal but differing in background. Our baseline, PCA+, uses alignment-only contrastive learning and succeeds when background variation is mild, but fails under strong noise or high-dimensional regimes. To address this, we introduce PCA++, a hard uniformity-constrained contrastive PCA that enforces identity covariance on projected features. PCA++ has a closed-form solution via a generalized eigenproblem, remains stable in high dimensions, and provably regularizes against background interference. We provide exact high-dimensional asymptotics in both fixed-aspect-ratio and growing-spike regimes, showing uniformity's role in robust signal recovery. Empirically, PCA++ outperforms standard PCA and alignment-only PCA+ on simulations, corrupted-MNIST, and single-cell transcriptomics, reliably recovering condition-invariant structure. More broadly, we clarify uniformity's role in contrastive learning, showing that explicit feature dispersion defends against structured noise and enhances robustness.
LLMEval-3: A Large-Scale Longitudinal Study on Robust and Fair Evaluation of Large Language Models
Aug 07, 2025Existing evaluation of Large Language Models (LLMs) on static benchmarks is vulnerable to data contamination and leaderboard overfitting, critical issues that obscure true model capabilities. To address this, we introduce LLMEval-3, a framework for dynamic evaluation of LLMs. LLMEval-3 is built on a proprietary bank of 220k graduate-level questions, from which it dynamically samples unseen test sets for each evaluation run. Its automated pipeline ensures integrity via contamination-resistant data curation, a novel anti-cheating architecture, and a calibrated LLM-as-a-judge process achieving 90% agreement with human experts, complemented by a relative ranking system for fair comparison. An 20-month longitudinal study of nearly 50 leading models reveals a performance ceiling on knowledge memorization and exposes data contamination vulnerabilities undetectable by static benchmarks. The framework demonstrates exceptional robustness in ranking stability and consistency, providing strong empirical validation for the dynamic evaluation paradigm. LLMEval-3 offers a robust and credible methodology for assessing the true capabilities of LLMs beyond leaderboard scores, promoting the development of more trustworthy evaluation standards.
Avoid Recommending Out-of-Domain Items: Constrained Generative Recommendation with LLMs
May 06, 2025Large Language Models (LLMs) have shown promise for generative recommender systems due to their transformative capabilities in user interaction. However, ensuring they do not recommend out-of-domain (OOD) items remains a challenge. We study two distinct methods to address this issue: RecLM-ret, a retrieval-based method, and RecLM-cgen, a constrained generation method. Both methods integrate seamlessly with existing LLMs to ensure in-domain recommendations. Comprehensive experiments on three recommendation datasets demonstrate that RecLM-cgen consistently outperforms RecLM-ret and existing LLM-based recommender models in accuracy while eliminating OOD recommendations, making it the preferred method for adoption. Additionally, RecLM-cgen maintains strong generalist capabilities and is a lightweight plug-and-play module for easy integration into LLMs, offering valuable practical benefits for the community. Source code is available at https://github.com/microsoft/RecAI
Aligning Language Models for Versatile Text-based Item Retrieval
Feb 29, 2024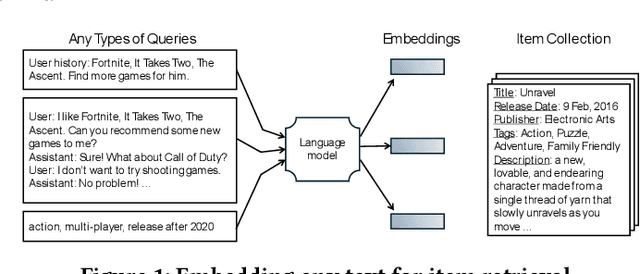
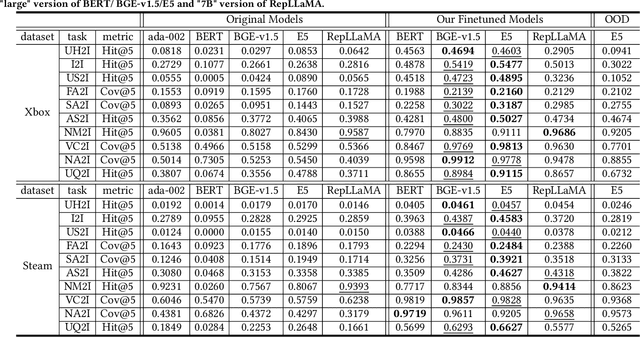


This paper addresses the gap between general-purpose text embeddings and the specific demands of item retrieval tasks. We demonstrate the shortcomings of existing models in capturing the nuances necessary for zero-shot performance on item retrieval tasks. To overcome these limitations, we propose generate in-domain dataset from ten tasks tailored to unlocking models' representation ability for item retrieval. Our empirical studies demonstrate that fine-tuning embedding models on the dataset leads to remarkable improvements in a variety of retrieval tasks. We also illustrate the practical application of our refined model in a conversational setting, where it enhances the capabilities of LLM-based Recommender Agents like Chat-Rec. Our code is available at https://github.com/microsoft/RecAI.
Ensemble linear interpolators: The role of ensembling
Sep 06, 2023



Interpolators are unstable. For example, the mininum $\ell_2$ norm least square interpolator exhibits unbounded test errors when dealing with noisy data. In this paper, we study how ensemble stabilizes and thus improves the generalization performance, measured by the out-of-sample prediction risk, of an individual interpolator. We focus on bagged linear interpolators, as bagging is a popular randomization-based ensemble method that can be implemented in parallel. We introduce the multiplier-bootstrap-based bagged least square estimator, which can then be formulated as an average of the sketched least square estimators. The proposed multiplier bootstrap encompasses the classical bootstrap with replacement as a special case, along with a more intriguing variant which we call the Bernoulli bootstrap. Focusing on the proportional regime where the sample size scales proportionally with the feature dimensionality, we investigate the out-of-sample prediction risks of the sketched and bagged least square estimators in both underparametrized and overparameterized regimes. Our results reveal the statistical roles of sketching and bagging. In particular, sketching modifies the aspect ratio and shifts the interpolation threshold of the minimum $\ell_2$ norm estimator. However, the risk of the sketched estimator continues to be unbounded around the interpolation threshold due to excessive variance. In stark contrast, bagging effectively mitigates this variance, leading to a bounded limiting out-of-sample prediction risk. To further understand this stability improvement property, we establish that bagging acts as a form of implicit regularization, substantiated by the equivalence of the bagged estimator with its explicitly regularized counterpart. We also discuss several extensions.
ConvFormer: Revisiting Transformer for Sequential User Modeling
Aug 05, 2023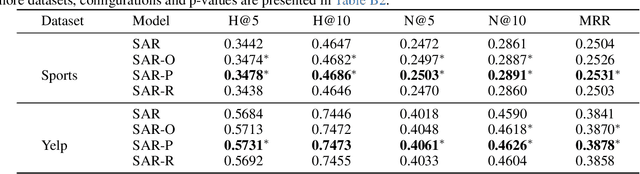
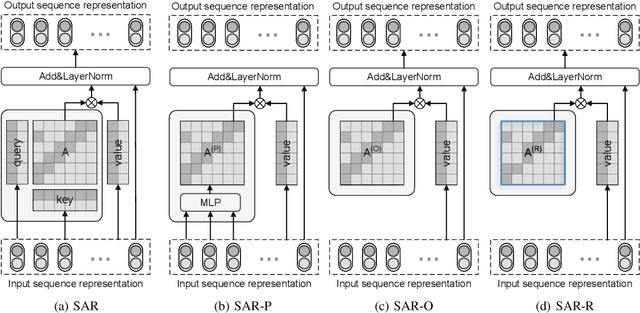

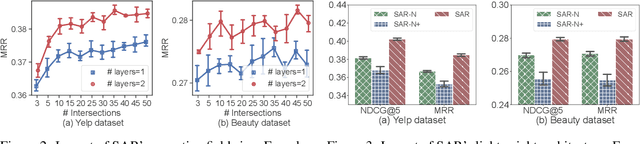
Sequential user modeling, a critical task in personalized recommender systems, focuses on predicting the next item a user would prefer, requiring a deep understanding of user behavior sequences. Despite the remarkable success of Transformer-based models across various domains, their full potential in comprehending user behavior remains untapped. In this paper, we re-examine Transformer-like architectures aiming to advance state-of-the-art performance. We start by revisiting the core building blocks of Transformer-based methods, analyzing the effectiveness of the item-to-item mechanism within the context of sequential user modeling. After conducting a thorough experimental analysis, we identify three essential criteria for devising efficient sequential user models, which we hope will serve as practical guidelines to inspire and shape future designs. Following this, we introduce ConvFormer, a simple but powerful modification to the Transformer architecture that meets these criteria, yielding state-of-the-art results. Additionally, we present an acceleration technique to minimize the complexity associated with processing extremely long sequences. Experiments on four public datasets showcase ConvFormer's superiority and confirm the validity of our proposed criteria.