 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanLLM: Towards Personalized Understanding and Simulation of Human Nature
Jan 22, 2026Motivated by the remarkable progress of large language models (LLMs) in objective tasks like mathematics and coding, there is growing interest in their potential to simulate human behavior--a capability with profound implications for transforming social science research and customer-centric business insights. However, LLMs often lack a nuanced understanding of human cognition and behavior, limiting their effectiveness in social simulation and personalized applications. We posit that this limitation stems from a fundamental misalignment: standard LLM pretraining on vast, uncontextualized web data does not capture the continuous, situated context of an individual's decisions, thoughts, and behaviors over time. To bridge this gap, we introduce HumanLLM, a foundation model designed for personalized understanding and simulation of individuals. We first construct the Cognitive Genome Dataset, a large-scale corpus curated from real-world user data on platforms like Reddit, Twitter, Blogger, and Amazon. Through a rigorous, multi-stage pipeline involving data filtering, synthesis, and quality control, we automatically extract over 5.5 million user logs to distill rich profiles, behaviors, and thinking patterns. We then formulate diverse learning tasks and perform supervised fine-tuning to empower the model to predict a wide range of individualized human behaviors, thoughts, and experiences. Comprehensive evaluations demonstrate that HumanLLM achieves superior performance in predicting user actions and inner thoughts, more accurately mimics user writing styles and preferences, and generates more authentic user profiles compared to base models. Furthermore, HumanLLM shows significant gains on out-of-domain social intelligence benchmarks, indicating enhanced generalization.
Why not Collaborative Filtering in Dual View? Bridging Sparse and Dense Models
Jan 14, 2026Collaborative Filtering (CF) remains the cornerstone of modern recommender systems, with dense embedding--based methods dominating current practice. However, these approaches suffer from a critical limitation: our theoretical analysis reveals a fundamental signal-to-noise ratio (SNR) ceiling when modeling unpopular items, where parameter-based dense models experience diminishing SNR under severe data sparsity. To overcome this bottleneck, we propose SaD (Sparse and Dense), a unified framework that integrates the semantic expressiveness of dense embeddings with the structural reliability of sparse interaction patterns. We theoretically show that aligning these dual views yields a strictly superior global SNR. Concretely, SaD introduces a lightweight bidirectional alignment mechanism: the dense view enriches the sparse view by injecting semantic correlations, while the sparse view regularizes the dense model through explicit structural signals. Extensive experiments demonstrate that, under this dual-view alignment, even a simple matrix factorization--style dense model can achieve state-of-the-art performance. Moreover, SaD is plug-and-play and can be seamlessly applied to a wide range of existing recommender models, highlighting the enduring power of collaborative filtering when leveraged from dual perspectives. Further evaluations on real-world benchmarks show that SaD consistently outperforms strong baselines, ranking first on the BarsMatch leaderboard. The code is publicly available at https://github.com/harris26-G/SaD.
NAMeGEn: Creative Name Generation via A Novel Agent-based Multiple Personalized Goal Enhancement Framework
Nov 19, 2025Trained on diverse human-authored texts, Large Language Models (LLMs) unlocked the potential for Creative Natural Language Generation (CNLG), benefiting various applications like advertising and storytelling. Nevertheless, CNLG still remains difficult due to two main challenges. (1) Multi-objective flexibility: user requirements are often personalized, fine-grained, and pluralistic, which LLMs struggle to satisfy simultaneously; (2) Interpretive complexity: beyond generation, creativity also involves understanding and interpreting implicit meaning to enhance users' perception. These challenges significantly limit current methods, especially in short-form text generation, in generating creative and insightful content. To address this, we focus on Chinese baby naming, a representative short-form CNLG task requiring adherence to explicit user constraints (e.g., length, semantics, anthroponymy) while offering meaningful aesthetic explanations. We propose NAMeGEn, a novel multi-agent optimization framework that iteratively alternates between objective extraction, name generation, and evaluation to meet diverse requirements and generate accurate explanations. To support this task, we further construct a classical Chinese poetry corpus with 17k+ poems to enhance aesthetics, and introduce CBNames, a new benchmark with tailored metrics. Extensive experiments demonstrate that NAMeGEn effectively generates creative names that meet diverse, personalized requirements while providing meaningful explanations, outperforming six baseline methods spanning various LLM backbones without any training.
Learning Pluralistic User Preferences through Reinforcement Learning Fine-tuned Summaries
Jul 17, 2025
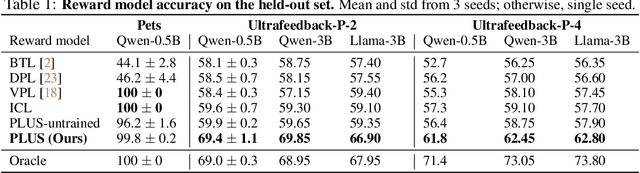
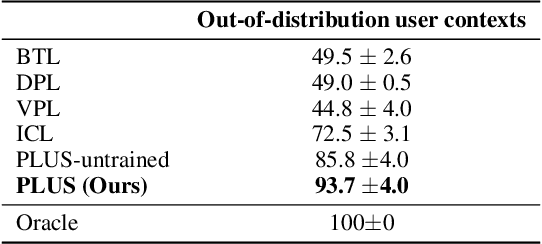
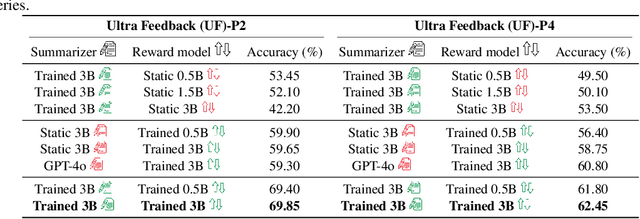
As everyday use cases of large language model (LLM) AI assistants have expanded, it is becoming increasingly important to personalize responses to align to different users' preferences and goals. While reinforcement learning from human feedback (RLHF) is effective at improving LLMs to be generally more helpful and fluent, it does not account for variability across users, as it models the entire user population with a single reward model. We present a novel framework, Preference Learning Using Summarization (PLUS), that learns text-based summaries of each user's preferences, characteristics, and past conversations. These summaries condition the reward model, enabling it to make personalized predictions about the types of responses valued by each user. We train the user-summarization model with reinforcement learning, and update the reward model simultaneously, creating an online co-adaptation loop. We show that in contrast with prior personalized RLHF techniques or with in-context learning of user information, summaries produced by PLUS capture meaningful aspects of a user's preferences. Across different pluralistic user datasets, we show that our method is robust to new users and diverse conversation topics. Additionally, we demonstrate that the textual summaries generated about users can be transferred for zero-shot personalization of stronger, proprietary models like GPT-4. The resulting user summaries are not only concise and portable, they are easy for users to interpret and modify, allowing for more transparency and user control in LLM alignment.
MotiveBench: How Far Are We From Human-Like Motivational Reasoning in Large Language Models?
Jun 16, 2025
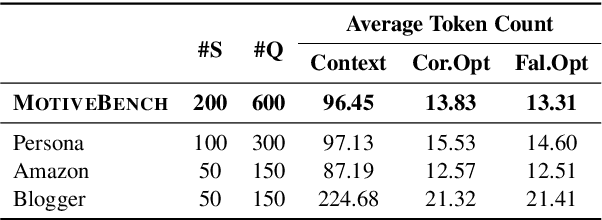
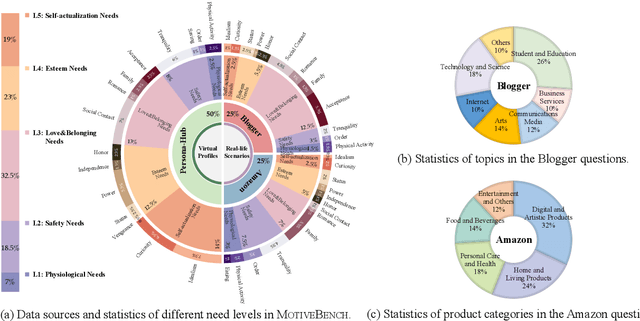
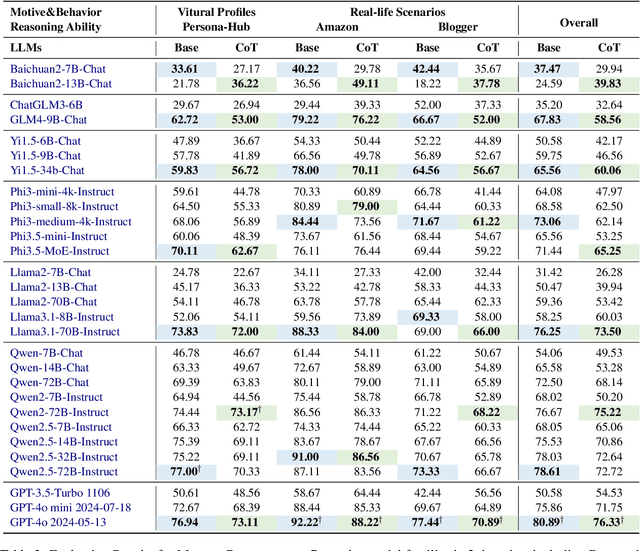
Large language models (LLMs) have been widely adopted as the core of agent frameworks in various scenarios, such as social simulations and AI companions. However, the extent to which they can replicate human-like motivations remains an underexplored question. Existing benchmarks are constrained by simplistic scenarios and the absence of character identities, resulting in an information asymmetry with real-world situations. To address this gap, we propose MotiveBench, which consists of 200 rich contextual scenarios and 600 reasoning tasks covering multiple levels of motivation. Using MotiveBench, we conduct extensive experiments on seven popular model families, comparing different scales and versions within each family. The results show that even the most advanced LLMs still fall short in achieving human-like motivational reasoning. Our analysis reveals key findings, including the difficulty LLMs face in reasoning about "love & belonging" motivations and their tendency toward excessive rationality and idealism. These insights highlight a promising direction for future research on the humanization of LLMs. The dataset, benchmark, and code are available at https://aka.ms/motivebench.
Unveiling the Learning Mind of Language Models: A Cognitive Framework and Empirical Study
Jun 16, 2025
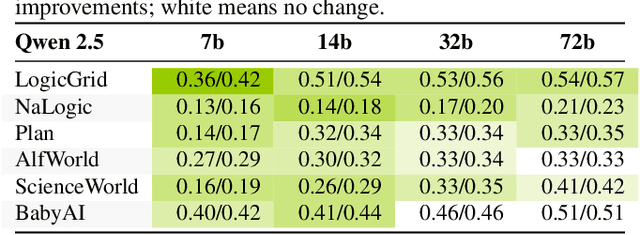

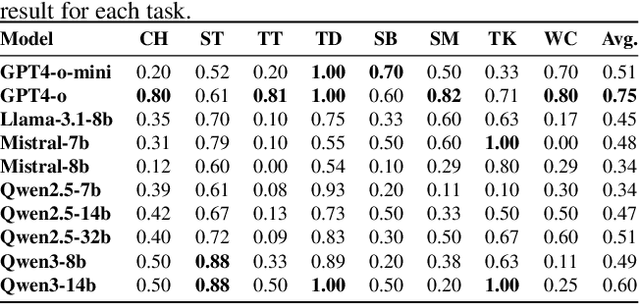
Large language models (LLMs) have shown impressive capabilities across tasks such as mathematics, coding, and reasoning, yet their learning ability, which is crucial for adapting to dynamic environments and acquiring new knowledge, remains underexplored. In this work, we address this gap by introducing a framework inspired by cognitive psychology and education. Specifically, we decompose general learning ability into three distinct, complementary dimensions: Learning from Instructor (acquiring knowledge via explicit guidance), Learning from Concept (internalizing abstract structures and generalizing to new contexts), and Learning from Experience (adapting through accumulated exploration and feedback). We conduct a comprehensive empirical study across the three learning dimensions and identify several insightful findings, such as (i) interaction improves learning; (ii) conceptual understanding is scale-emergent and benefits larger models; and (iii) LLMs are effective few-shot learners but not many-shot learners. Based on our framework and empirical findings, we introduce a benchmark that provides a unified and realistic evaluation of LLMs' general learning abilities across three learning cognition dimensions. It enables diagnostic insights and supports evaluation and development of more adaptive and human-like models.
Avoid Recommending Out-of-Domain Items: Constrained Generative Recommendation with LLMs
May 06, 2025Large Language Models (LLMs) have shown promise for generative recommender systems due to their transformative capabilities in user interaction. However, ensuring they do not recommend out-of-domain (OOD) items remains a challenge. We study two distinct methods to address this issue: RecLM-ret, a retrieval-based method, and RecLM-cgen, a constrained generation method. Both methods integrate seamlessly with existing LLMs to ensure in-domain recommendations. Comprehensive experiments on three recommendation datasets demonstrate that RecLM-cgen consistently outperforms RecLM-ret and existing LLM-based recommender models in accuracy while eliminating OOD recommendations, making it the preferred method for adoption. Additionally, RecLM-cgen maintains strong generalist capabilities and is a lightweight plug-and-play module for easy integration into LLMs, offering valuable practical benefits for the community. Source code is available at https://github.com/microsoft/RecAI
LLM-powered Multi-agent Framework for Goal-oriented Learning in Intelligent Tutoring System
Jan 27, 2025



Intelligent Tutoring Systems (ITSs) have revolutionized education by offering personalized learning experiences. However, as goal-oriented learning, which emphasizes efficiently achieving specific objectives, becomes increasingly important in professional contexts, existing ITSs often struggle to deliver this type of targeted learning experience. In this paper, we propose GenMentor, an LLM-powered multi-agent framework designed to deliver goal-oriented, personalized learning within ITS. GenMentor begins by accurately mapping learners' goals to required skills using a fine-tuned LLM trained on a custom goal-to-skill dataset. After identifying the skill gap, it schedules an efficient learning path using an evolving optimization approach, driven by a comprehensive and dynamic profile of learners' multifaceted status. Additionally, GenMentor tailors learning content with an exploration-drafting-integration mechanism to align with individual learner needs. Extensive automated and human evaluations demonstrate GenMentor's effectiveness in learning guidance and content quality. Furthermore, we have deployed it in practice and also implemented it as an application. Practical human study with professional learners further highlights its effectiveness in goal alignment and resource targeting, leading to enhanced personalization. Supplementary resources are available at https://github.com/GeminiLight/gen-mentor.
The Road to Artificial SuperIntelligence: A Comprehensive Survey of Superalignment
Dec 24, 2024



The emergence of large language models (LLMs) has sparked the possibility of about Artificial Superintelligence (ASI), a hypothetical AI system surpassing human intelligence. However, existing alignment paradigms struggle to guide such advanced AI systems. Superalignment, the alignment of AI systems with human values and safety requirements at superhuman levels of capability aims to addresses two primary goals -- scalability in supervision to provide high-quality guidance signals and robust governance to ensure alignment with human values. In this survey, we examine scalable oversight methods and potential solutions for superalignment. Specifically, we explore the concept of ASI, the challenges it poses, and the limitations of current alignment paradigms in addressing the superalignment problem. Then we review scalable oversight methods for superalignment. Finally, we discuss the key challenges and propose pathways for the safe and continual improvement of ASI systems. By comprehensively reviewing the current literature, our goal is provide a systematical introduction of existing methods, analyze their strengths and limitations, and discuss potential future directions.
TrendSim: Simulating Trending Topics in Social Media Under Poisoning Attacks with LLM-based Multi-agent System
Dec 14, 2024



Trending topics have become a significant part of modern social media, attracting users to participate in discussions of breaking events. However, they also bring in a new channel for poisoning attacks, resulting in negative impacts on society. Therefore, it is urgent to study this critical problem and develop effective strategies for defense. In this paper, we propose TrendSim, an LLM-based multi-agent system to simulate trending topics in social media under poisoning attacks. Specifically, we create a simulation environment for trending topics that incorporates a time-aware interaction mechanism, centralized message dissemination, and an interactive system. Moreover, we develop LLM-based human-like agents to simulate users in social media, and propose prototype-based attackers to replicate poisoning attacks. Besides, we evaluate TrendSim from multiple aspects to validate its effectiveness. Based on TrendSim, we conduct simulation experiments to study four critical problems about poisoning attacks on trending topics for social benefit.