 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvoid Recommending Out-of-Domain Items: Constrained Generative Recommendation with LLMs
May 06, 2025Large Language Models (LLMs) have shown promise for generative recommender systems due to their transformative capabilities in user interaction. However, ensuring they do not recommend out-of-domain (OOD) items remains a challenge. We study two distinct methods to address this issue: RecLM-ret, a retrieval-based method, and RecLM-cgen, a constrained generation method. Both methods integrate seamlessly with existing LLMs to ensure in-domain recommendations. Comprehensive experiments on three recommendation datasets demonstrate that RecLM-cgen consistently outperforms RecLM-ret and existing LLM-based recommender models in accuracy while eliminating OOD recommendations, making it the preferred method for adoption. Additionally, RecLM-cgen maintains strong generalist capabilities and is a lightweight plug-and-play module for easy integration into LLMs, offering valuable practical benefits for the community. Source code is available at https://github.com/microsoft/RecAI
Re-Search for The Truth: Multi-round Retrieval-augmented Large Language Models are Strong Fake News Detectors
Mar 14, 2024
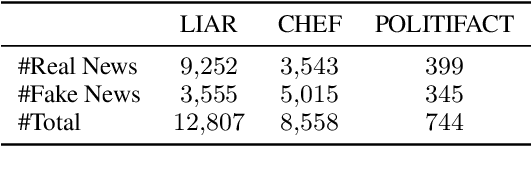
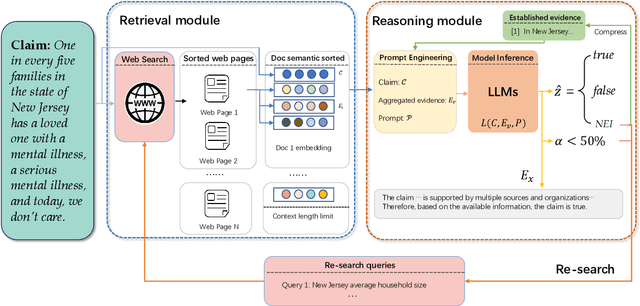
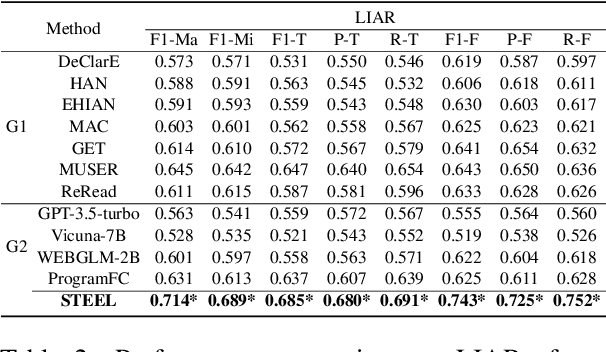
The proliferation of fake news has had far-reaching implications on politics, the economy, and society at large. While Fake news detection methods have been employed to mitigate this issue, they primarily depend on two essential elements: the quality and relevance of the evidence, and the effectiveness of the verdict prediction mechanism. Traditional methods, which often source information from static repositories like Wikipedia, are limited by outdated or incomplete data, particularly for emerging or rare claims. Large Language Models (LLMs), known for their remarkable reasoning and generative capabilities, introduce a new frontier for fake news detection. However, like traditional methods, LLM-based solutions also grapple with the limitations of stale and long-tail knowledge. Additionally, retrieval-enhanced LLMs frequently struggle with issues such as low-quality evidence retrieval and context length constraints. To address these challenges, we introduce a novel, retrieval-augmented LLMs framework--the first of its kind to automatically and strategically extract key evidence from web sources for claim verification. Employing a multi-round retrieval strategy, our framework ensures the acquisition of sufficient, relevant evidence, thereby enhancing performance. Comprehensive experiments across three real-world datasets validate the framework's superiority over existing methods. Importantly, our model not only delivers accurate verdicts but also offers human-readable explanations to improve result interpretability.
Aligning Large Language Models for Controllable Recommendations
Mar 08, 2024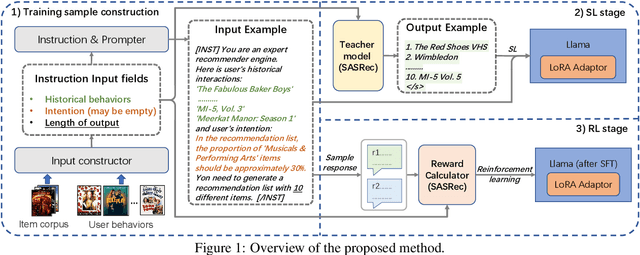
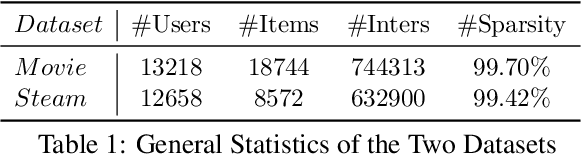
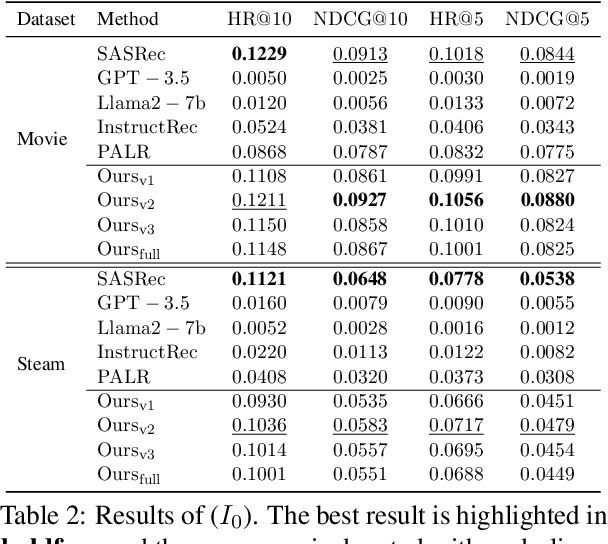
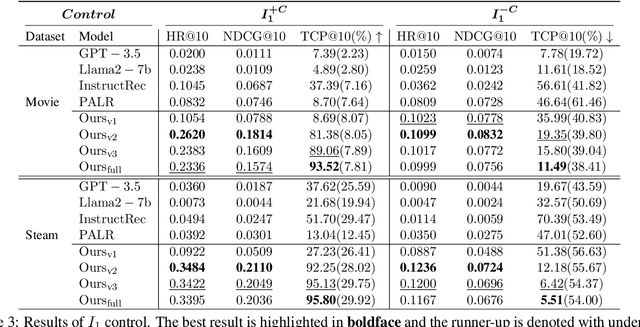
Inspired by the exceptional general intelligence of Large Language Models (LLMs), researchers have begun to explore their application in pioneering the next generation of recommender systems - systems that are conversational, explainable, and controllable. However, existing literature primarily concentrates on integrating domain-specific knowledge into LLMs to enhance accuracy, often neglecting the ability to follow instructions. To address this gap, we initially introduce a collection of supervised learning tasks, augmented with labels derived from a conventional recommender model, aimed at explicitly improving LLMs' proficiency in adhering to recommendation-specific instructions. Subsequently, we develop a reinforcement learning-based alignment procedure to further strengthen LLMs' aptitude in responding to users' intentions and mitigating formatting errors. Through extensive experiments on two real-world datasets, our method markedly advances the capability of LLMs to comply with instructions within recommender systems, while sustaining a high level of accuracy performance.