 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposing the Delta: What Do Models Actually Learn from Preference Pairs?
Apr 09, 2026Preference optimization methods such as DPO and KTO are widely used for aligning language models, yet little is understood about what properties of preference data drive downstream reasoning gains. We ask: what aspects of a preference pair improve a reasoning model's performance on general reasoning tasks? We investigate two distinct notions of quality delta in preference data: generator-level delta, arising from the differences in capability between models that generate chosen and rejected reasoning traces, and sample-level delta, arising from differences in judged quality differences within an individual preference pair. To study generator-level delta, we vary the generator's scale and model family, and to study sample-level delta, we employ an LLM-as-a-judge to rate the quality of generated traces along multiple reasoning-quality dimensions. We find that increasing generator-level delta steadily improves performance on out-of-domain reasoning tasks and filtering data by sample-level delta can enable more data-efficient training. Our results suggest a twofold recipe for improving reasoning performance through preference optimization: maximize generator-level delta when constructing preference pairs and exploit sample-level delta to select the most informative training examples.
Toward Consistent World Models with Multi-Token Prediction and Latent Semantic Enhancement
Apr 07, 2026Whether Large Language Models (LLMs) develop coherent internal world models remains a core debate. While conventional Next-Token Prediction (NTP) focuses on one-step-ahead supervision, Multi-Token Prediction (MTP) has shown promise in learning more structured representations. In this work, we provide a theoretical perspective analyzing the gradient inductive bias of MTP, supported by empirical evidence, showing that MTP promotes the convergence toward internal belief states by inducing representational contractivity via gradient coupling. However, we reveal that standard MTP often suffers from structural hallucinations, where discrete token supervision encourages illegal shortcuts in latent space that violate environmental constraints. To address this, we propose a novel method Latent Semantic Enhancement MTP (LSE-MTP), which anchors predictions to ground-truth hidden state trajectories. Experiments on synthetic graphs and real-world Manhattan Taxi Ride show that LSE-MTP effectively bridges the gap between discrete tokens and continuous state representations, enhancing representation alignment, reducing structural hallucinations, and improving robustness to perturbations.
DIAL-SUMMER: A Structured Evaluation Framework of Hierarchical Errors in Dialogue Summaries
Feb 08, 2026Dialogues are a predominant mode of communication for humans, and it is immensely helpful to have automatically generated summaries of them (e.g., to revise key points discussed in a meeting, to review conversations between customer agents and product users). Prior works on dialogue summary evaluation largely ignore the complexities specific to this task: (i) shift in structure, from multiple speakers discussing information in a scattered fashion across several turns, to a summary's sentences, and (ii) shift in narration viewpoint, from speakers' first/second-person narration, standardized third-person narration in the summary. In this work, we introduce our framework DIALSUMMER to address the above. We propose DIAL-SUMMER's taxonomy of errors to comprehensively evaluate dialogue summaries at two hierarchical levels: DIALOGUE-LEVEL that focuses on the broader speakers/turns, and WITHIN-TURN-LEVEL that focuses on the information talked about inside a turn. We then present DIAL-SUMMER's dataset composed of dialogue summaries manually annotated with our taxonomy's fine-grained errors. We conduct empirical analyses of these annotated errors, and observe interesting trends (e.g., turns occurring in middle of the dialogue are the most frequently missed in the summary, extrinsic hallucinations largely occur at the end of the summary). We also conduct experiments on LLM-Judges' capability at detecting these errors, through which we demonstrate the challenging nature of our dataset, the robustness of our taxonomy, and the need for future work in this field to enhance LLMs' performance in the same. Code and inference dataset coming soon.
Avoid Recommending Out-of-Domain Items: Constrained Generative Recommendation with LLMs
May 06, 2025Large Language Models (LLMs) have shown promise for generative recommender systems due to their transformative capabilities in user interaction. However, ensuring they do not recommend out-of-domain (OOD) items remains a challenge. We study two distinct methods to address this issue: RecLM-ret, a retrieval-based method, and RecLM-cgen, a constrained generation method. Both methods integrate seamlessly with existing LLMs to ensure in-domain recommendations. Comprehensive experiments on three recommendation datasets demonstrate that RecLM-cgen consistently outperforms RecLM-ret and existing LLM-based recommender models in accuracy while eliminating OOD recommendations, making it the preferred method for adoption. Additionally, RecLM-cgen maintains strong generalist capabilities and is a lightweight plug-and-play module for easy integration into LLMs, offering valuable practical benefits for the community. Source code is available at https://github.com/microsoft/RecAI
Benchmarking Graph Learning for Drug-Drug Interaction Prediction
Oct 24, 2024Predicting drug-drug interaction (DDI) plays an important role in pharmacology and healthcare for identifying potential adverse interactions and beneficial combination therapies between drug pairs. Recently, a flurry of graph learning methods have been introduced to predict drug-drug interactions. However, evaluating existing methods has several limitations, such as the absence of a unified comparison framework for DDI prediction methods, lack of assessments in meaningful real-world scenarios, and insufficient exploration of side information usage. In order to address these unresolved limitations in the literature, we propose a DDI prediction benchmark on graph learning. We first conduct unified evaluation comparison among existing methods. To meet realistic scenarios, we further evaluate the performance of different methods in settings with new drugs involved and examine the performance across different DDI types. Component analysis is conducted on the biomedical network to better utilize side information. Through this work, we hope to provide more insights for the problem of DDI prediction. Our implementation and data is open-sourced at https://anonymous.4open.science/r/DDI-Benchmark-ACD9/.
Exploring Loss Landscapes through the Lens of Spin Glass Theory
Jul 30, 2024



In the past decade, significant strides in deep learning have led to numerous groundbreaking applications. Despite these advancements, the understanding of the high generalizability of deep learning, especially in such an over-parametrized space, remains limited. Successful applications are often considered as empirical rather than scientific achievements. For instance, deep neural networks' (DNNs) internal representations, decision-making mechanism, absence of overfitting in an over-parametrized space, high generalizability, etc., remain less understood. This paper delves into the loss landscape of DNNs through the lens of spin glass in statistical physics, i.e. a system characterized by a complex energy landscape with numerous metastable states, to better understand how DNNs work. We investigated a single hidden layer Rectified Linear Unit (ReLU) neural network model, and introduced several protocols to examine the analogy between DNNs (trained with datasets including MNIST and CIFAR10) and spin glass. Specifically, we used (1) random walk in the parameter space of DNNs to unravel the structures in their loss landscape; (2) a permutation-interpolation protocol to study the connection between copies of identical regions in the loss landscape due to the permutation symmetry in the hidden layers; (3) hierarchical clustering to reveal the hierarchy among trained solutions of DNNs, reminiscent of the so-called Replica Symmetry Breaking (RSB) phenomenon (i.e. the Parisi solution) in analogy to spin glass; (4) finally, we examine the relationship between the degree of the ruggedness of the loss landscape of the DNN and its generalizability, showing an improvement of flattened minima.
From Pixels to Insights: A Survey on Automatic Chart Understanding in the Era of Large Foundation Models
Mar 25, 2024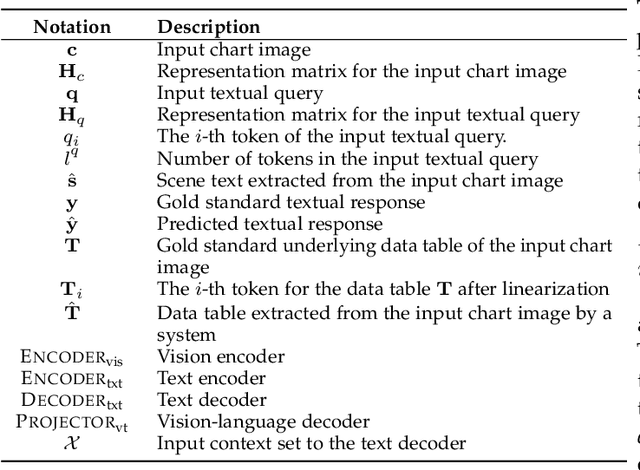
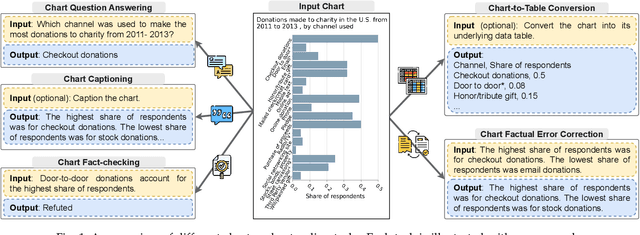
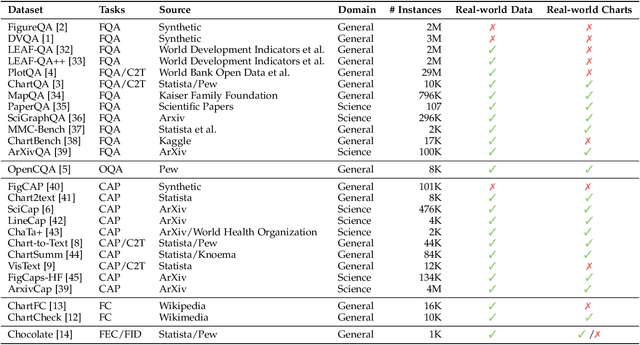
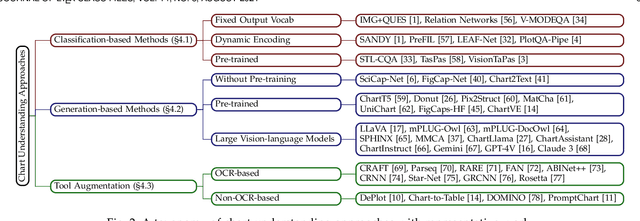
Data visualization in the form of charts plays a pivotal role in data analysis, offering critical insights and aiding in informed decision-making. Automatic chart understanding has witnessed significant advancements with the rise of large foundation models in recent years. Foundation models, such as large language models, have revolutionized various natural language processing tasks and are increasingly being applied to chart understanding tasks. This survey paper provides a comprehensive overview of the recent developments, challenges, and future directions in chart understanding within the context of these foundation models. We review fundamental building blocks crucial for studying chart understanding tasks. Additionally, we explore various tasks and their evaluation metrics and sources of both charts and textual inputs. Various modeling strategies are then examined, encompassing both classification-based and generation-based approaches, along with tool augmentation techniques that enhance chart understanding performance. Furthermore, we discuss the state-of-the-art performance of each task and discuss how we can improve the performance. Challenges and future directions are addressed, highlighting the importance of several topics, such as domain-specific charts, lack of efforts in developing evaluation metrics, and agent-oriented settings. This survey paper serves as a comprehensive resource for researchers and practitioners in the fields of natural language processing, computer vision, and data analysis, providing valuable insights and directions for future research in chart understanding leveraging large foundation models. The studies mentioned in this paper, along with emerging new research, will be continually updated at: https://github.com/khuangaf/Awesome-Chart-Understanding.
Aligning Large Language Models for Controllable Recommendations
Mar 08, 2024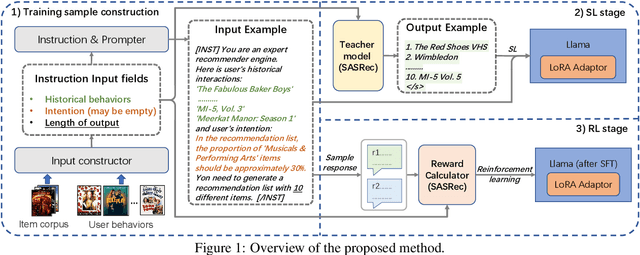
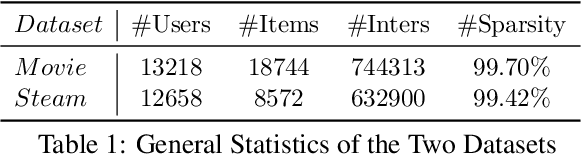
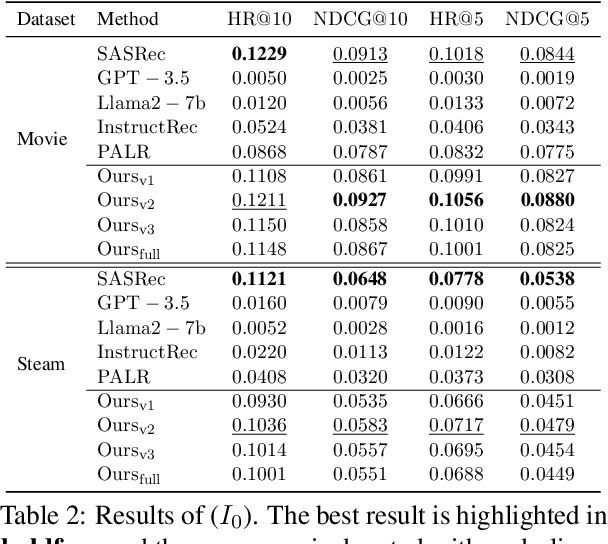
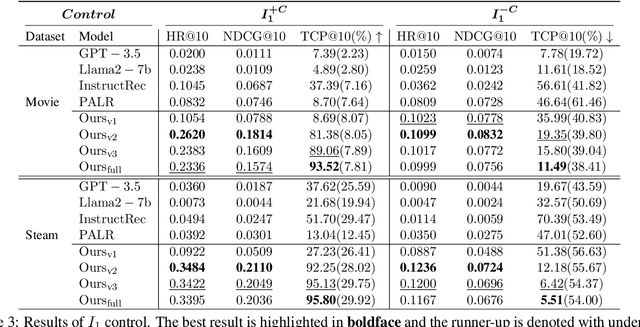
Inspired by the exceptional general intelligence of Large Language Models (LLMs), researchers have begun to explore their application in pioneering the next generation of recommender systems - systems that are conversational, explainable, and controllable. However, existing literature primarily concentrates on integrating domain-specific knowledge into LLMs to enhance accuracy, often neglecting the ability to follow instructions. To address this gap, we initially introduce a collection of supervised learning tasks, augmented with labels derived from a conventional recommender model, aimed at explicitly improving LLMs' proficiency in adhering to recommendation-specific instructions. Subsequently, we develop a reinforcement learning-based alignment procedure to further strengthen LLMs' aptitude in responding to users' intentions and mitigating formatting errors. Through extensive experiments on two real-world datasets, our method markedly advances the capability of LLMs to comply with instructions within recommender systems, while sustaining a high level of accuracy performance.
Do LVLMs Understand Charts? Analyzing and Correcting Factual Errors in Chart Captioning
Dec 15, 2023



Recent advancements in large vision-language models (LVLMs) have led to significant progress in generating natural language descriptions for visual content and thus enhancing various applications. One issue with these powerful models is that they sometimes produce texts that are factually inconsistent with the visual input. While there has been some effort to mitigate such inconsistencies in natural image captioning, the factuality of generated captions for structured document images, such as charts, has not received as much scrutiny, posing a potential threat to information reliability in critical applications. This work delves into the factuality aspect by introducing a comprehensive typology of factual errors in generated chart captions. A large-scale human annotation effort provides insight into the error patterns and frequencies in captions crafted by various chart captioning models, ultimately forming the foundation of a novel dataset, CHOCOLATE. Our analysis reveals that even state-of-the-art models, including GPT-4V, frequently produce captions laced with factual inaccuracies. In response to this challenge, we establish the new task of Chart Caption Factual Error Correction and introduce CHARTVE, a model for visual entailment that outperforms proprietary and open-source LVLMs in evaluating factual consistency. Furthermore, we propose C2TFEC, an interpretable two-stage framework that excels at correcting factual errors. This work inaugurates a new domain in factual error correction for chart captions, presenting a novel evaluation mechanism, and demonstrating an effective approach to ensuring the factuality of generated chart captions.
PhyloGFN: Phylogenetic inference with generative flow networks
Oct 12, 2023Phylogenetics is a branch of computational biology that studies the evolutionary relationships among biological entities. Its long history and numerous applications notwithstanding, inference of phylogenetic trees from sequence data remains challenging: the high complexity of tree space poses a significant obstacle for the current combinatorial and probabilistic techniques. In this paper, we adopt the framework of generative flow networks (GFlowNets) to tackle two core problems in phylogenetics: parsimony-based and Bayesian phylogenetic inference. Because GFlowNets are well-suited for sampling complex combinatorial structures, they are a natural choice for exploring and sampling from the multimodal posterior distribution over tree topologies and evolutionary distances. We demonstrate that our amortized posterior sampler, PhyloGFN, produces diverse and high-quality evolutionary hypotheses on real benchmark datasets. PhyloGFN is competitive with prior works in marginal likelihood estimation and achieves a closer fit to the target distribution than state-of-the-art variational inference methods.