 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
REFA: Real-time Egocentric Facial Animations for Virtual Reality
Jan 07, 2026We present a novel system for real-time tracking of facial expressions using egocentric views captured from a set of infrared cameras embedded in a virtual reality (VR) headset. Our technology facilitates any user to accurately drive the facial expressions of virtual characters in a non-intrusive manner and without the need of a lengthy calibration step. At the core of our system is a distillation based approach to train a machine learning model on heterogeneous data and labels coming form multiple sources, \eg synthetic and real images. As part of our dataset, we collected 18k diverse subjects using a lightweight capture setup consisting of a mobile phone and a custom VR headset with extra cameras. To process this data, we developed a robust differentiable rendering pipeline enabling us to automatically extract facial expression labels. Our system opens up new avenues for communication and expression in virtual environments, with applications in video conferencing, gaming, entertainment, and remote collaboration.
A Novel Discrete Memristor-Coupled Heterogeneous Dual-Neuron Model and Its Application in Multi-Scenario Image Encryption
May 30, 2025Simulating brain functions using neural networks is an important area of research. Recently, discrete memristor-coupled neurons have attracted significant attention, as memristors effectively mimic synaptic behavior, which is essential for learning and memory. This highlights the biological relevance of such models. This study introduces a discrete memristive heterogeneous dual-neuron network (MHDNN). The stability of the MHDNN is analyzed with respect to initial conditions and a range of neuronal parameters. Numerical simulations demonstrate complex dynamical behaviors. Various neuronal firing patterns are investigated under different coupling strengths, and synchronization phenomena between neurons are explored. The MHDNN is implemented and validated on the STM32 hardware platform. An image encryption algorithm based on the MHDNN is proposed, along with two hardware platforms tailored for multi-scenario police image encryption. These solutions enable real-time and secure transmission of police data in complex environments, reducing hacking risks and enhancing system security.
PVUW 2025 Challenge Report: Advances in Pixel-level Understanding of Complex Videos in the Wild
Apr 15, 2025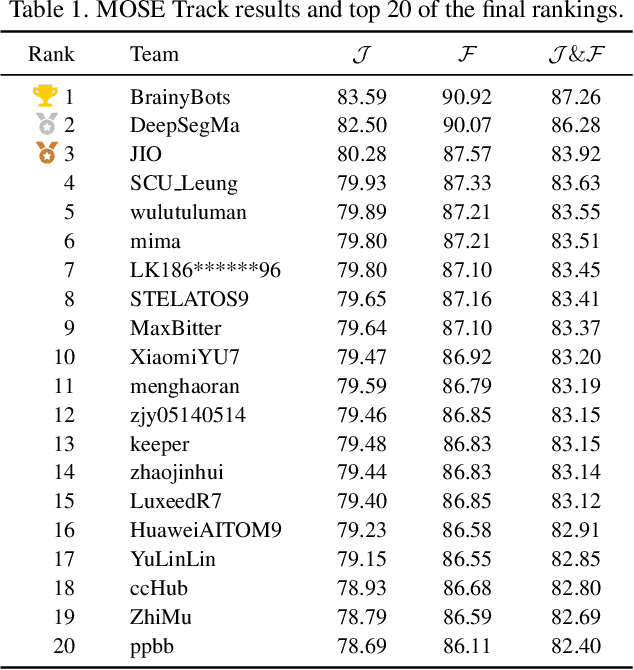
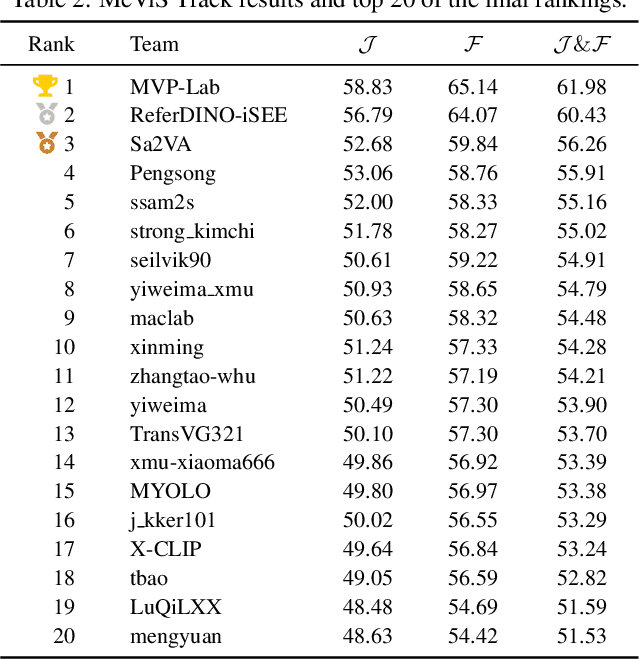
This report provides a comprehensive overview of the 4th Pixel-level Video Understanding in the Wild (PVUW) Challenge, held in conjunction with CVPR 2025. It summarizes the challenge outcomes, participating methodologies, and future research directions. The challenge features two tracks: MOSE, which focuses on complex scene video object segmentation, and MeViS, which targets motion-guided, language-based video segmentation. Both tracks introduce new, more challenging datasets designed to better reflect real-world scenarios. Through detailed evaluation and analysis, the challenge offers valuable insights into the current state-of-the-art and emerging trends in complex video segmentation. More information can be found on the workshop website: https://pvuw.github.io/.
FVOS for MOSE Track of 4th PVUW Challenge: 3rd Place Solution
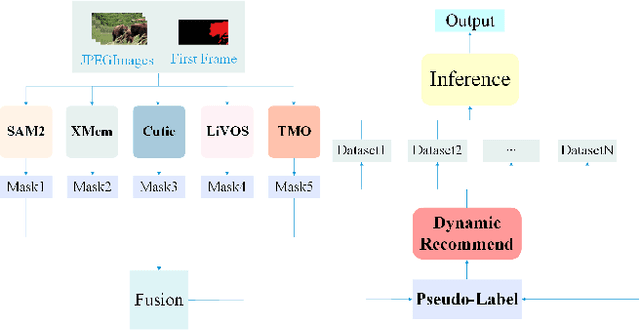
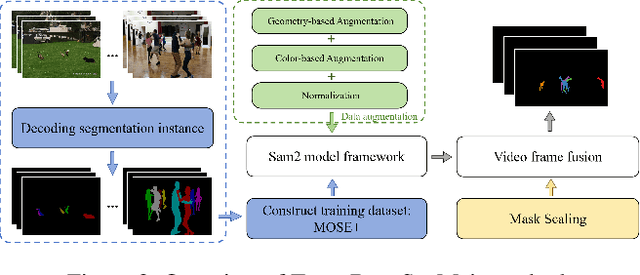
Apr 13, 2025Video Object Segmentation (VOS) is one of the most fundamental and challenging tasks in computer vision and has a wide range of applications. Most existing methods rely on spatiotemporal memory networks to extract frame-level features and have achieved promising results on commonly used datasets. However, these methods often struggle in more complex real-world scenarios. This paper addresses this issue, aiming to achieve accurate segmentation of video objects in challenging scenes. We propose fine-tuning VOS (FVOS), optimizing existing methods for specific datasets through tailored training. Additionally, we introduce a morphological post-processing strategy to address the issue of excessively large gaps between adjacent objects in single-model predictions. Finally, we apply a voting-based fusion method on multi-scale segmentation results to generate the final output. Our approach achieves J&F scores of 76.81% and 83.92% during the validation and testing stages, respectively, securing third place overall in the MOSE Track of the 4th PVUW challenge 2025.
Coarse-to-Fine Contrastive Learning in Image-Text-Graph Space for Improved Vision-Language Compositionality
May 23, 2023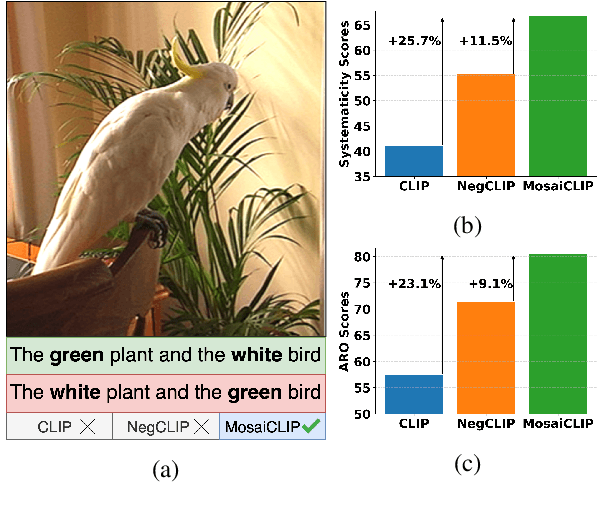



Contrastively trained vision-language models have achieved remarkable progress in vision and language representation learning, leading to state-of-the-art models for various downstream multimodal tasks. However, recent research has highlighted severe limitations of these models in their ability to perform compositional reasoning over objects, attributes, and relations. Scene graphs have emerged as an effective way to understand images compositionally. These are graph-structured semantic representations of images that contain objects, their attributes, and relations with other objects in a scene. In this work, we consider the scene graph parsed from text as a proxy for the image scene graph and propose a graph decomposition and augmentation framework along with a coarse-to-fine contrastive learning objective between images and text that aligns sentences of various complexities to the same image. Along with this, we propose novel negative mining techniques in the scene graph space for improving attribute binding and relation understanding. Through extensive experiments, we demonstrate the effectiveness of our approach that significantly improves attribute binding, relation understanding, systematic generalization, and productivity on multiple recently proposed benchmarks (For example, improvements upto $18\%$ for systematic generalization, $16.5\%$ for relation understanding over a strong baseline), while achieving similar or better performance than CLIP on various general multimodal tasks.
Que2Engage: Embedding-based Retrieval for Relevant and Engaging Products at Facebook Marketplace
Feb 21, 2023Embedding-based Retrieval (EBR) in e-commerce search is a powerful search retrieval technique to address semantic matches between search queries and products. However, commercial search engines like Facebook Marketplace Search are complex multi-stage systems optimized for multiple business objectives. At Facebook Marketplace, search retrieval focuses on matching search queries with relevant products, while search ranking puts more emphasis on contextual signals to up-rank the more engaging products. As a result, the end-to-end searcher experience is a function of both relevance and engagement, and the interaction between different stages of the system. This presents challenges to EBR systems in order to optimize for better searcher experiences. In this paper we presents Que2Engage, a search EBR system built towards bridging the gap between retrieval and ranking for end-to-end optimizations. Que2Engage takes a multimodal & multitask approach to infuse contextual information into the retrieval stage and to balance different business objectives. We show the effectiveness of our approach via a multitask evaluation framework and thorough baseline comparisons and ablation studies. Que2Engage is deployed on Facebook Marketplace Search and shows significant improvements in searcher engagement in two weeks of A/B testing.
FaD-VLP: Fashion Vision-and-Language Pre-training towards Unified Retrieval and Captioning
Oct 26, 2022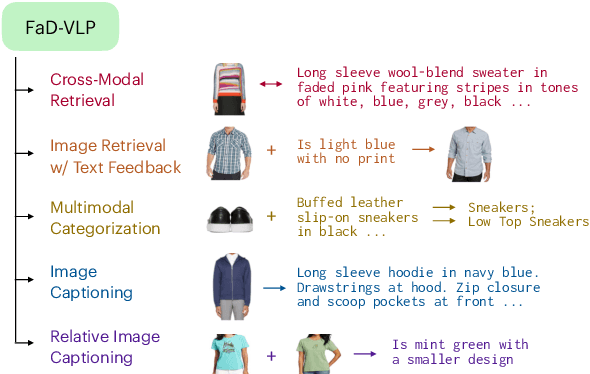

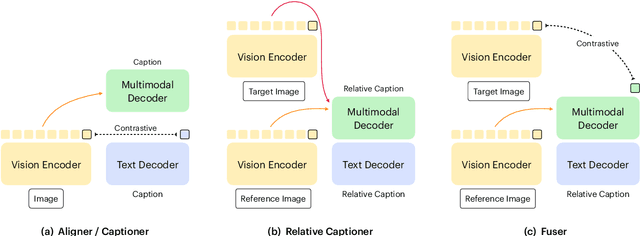
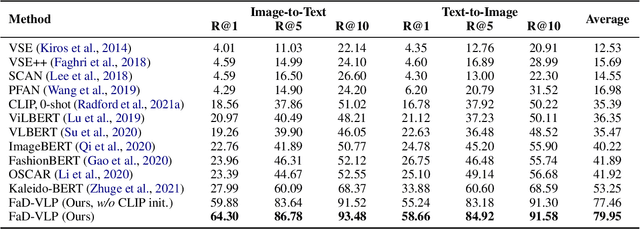
Multimodal tasks in the fashion domain have significant potential for e-commerce, but involve challenging vision-and-language learning problems - e.g., retrieving a fashion item given a reference image plus text feedback from a user. Prior works on multimodal fashion tasks have either been limited by the data in individual benchmarks, or have leveraged generic vision-and-language pre-training but have not taken advantage of the characteristics of fashion data. Additionally, these works have mainly been restricted to multimodal understanding tasks. To address these gaps, we make two key contributions. First, we propose a novel fashion-specific pre-training framework based on weakly-supervised triplets constructed from fashion image-text pairs. We show the triplet-based tasks are an effective addition to standard multimodal pre-training tasks. Second, we propose a flexible decoder-based model architecture capable of both fashion retrieval and captioning tasks. Together, our model design and pre-training approach are competitive on a diverse set of fashion tasks, including cross-modal retrieval, image retrieval with text feedback, image captioning, relative image captioning, and multimodal categorization.
LoopITR: Combining Dual and Cross Encoder Architectures for Image-Text Retrieval
Mar 10, 2022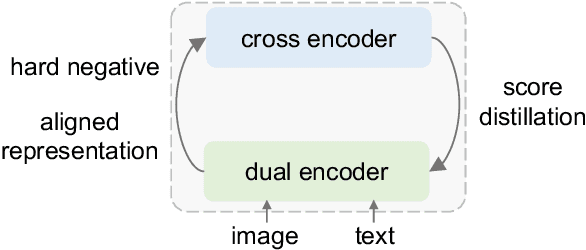
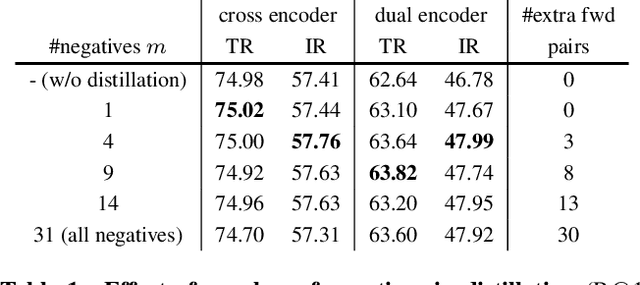

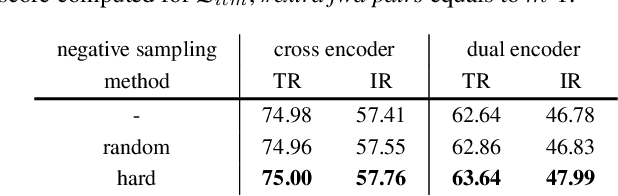
Dual encoders and cross encoders have been widely used for image-text retrieval. Between the two, the dual encoder encodes the image and text independently followed by a dot product, while the cross encoder jointly feeds image and text as the input and performs dense multi-modal fusion. These two architectures are typically modeled separately without interaction. In this work, we propose LoopITR, which combines them in the same network for joint learning. Specifically, we let the dual encoder provide hard negatives to the cross encoder, and use the more discriminative cross encoder to distill its predictions back to the dual encoder. Both steps are efficiently performed together in the same model. Our work centers on empirical analyses of this combined architecture, putting the main focus on the design of the distillation objective. Our experimental results highlight the benefits of training the two encoders in the same network, and demonstrate that distillation can be quite effective with just a few hard negative examples. Experiments on two standard datasets (Flickr30K and COCO) show our approach achieves state-of-the-art dual encoder performance when compared with approaches using a similar amount of data.
Unsupervised Vision-and-Language Pre-training via Retrieval-based Multi-Granular Alignment
Mar 01, 2022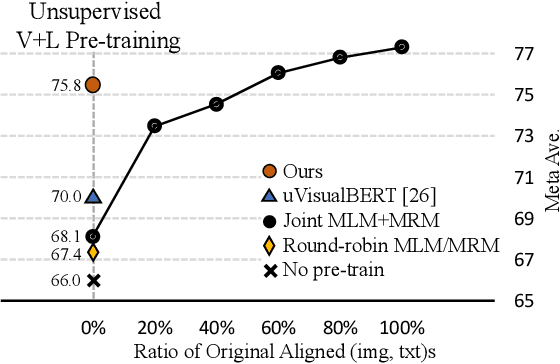
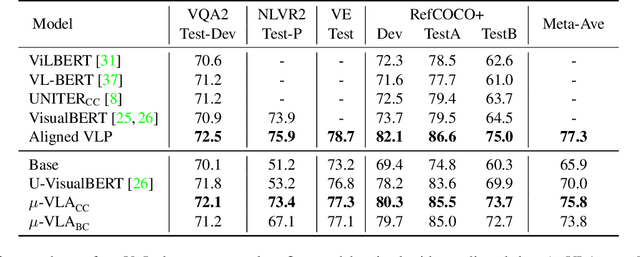
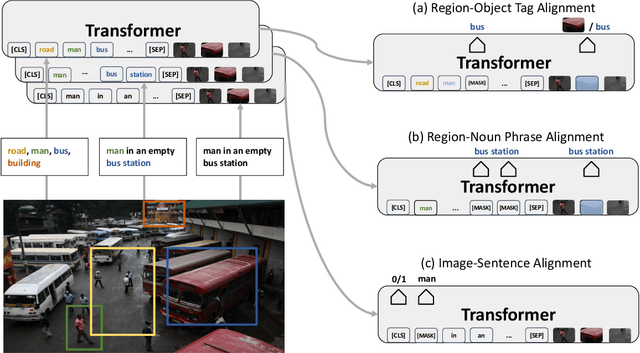
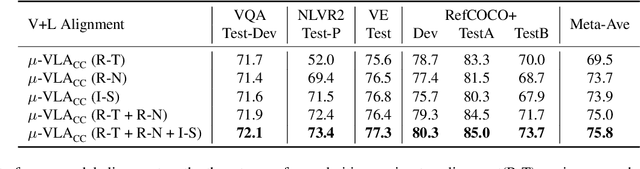
Vision-and-Language (V+L) pre-training models have achieved tremendous success in recent years on various multi-modal benchmarks. However, the majority of existing models require pre-training on a large set of parallel image-text data, which is costly to collect, compared to image-only or text-only data. In this paper, we explore unsupervised Vision-and-Language pre-training (UVLP) to learn the cross-modal representation from non-parallel image and text datasets. We found two key factors that lead to good unsupervised V+L pre-training without parallel data: (i) joint image-and-text input (ii) overall image-text alignment (even for non-parallel data). Accordingly, we propose a novel unsupervised V+L pre-training curriculum for non-parallel texts and images. We first construct a weakly aligned image-text corpus via a retrieval-based approach, then apply a set of multi-granular alignment pre-training tasks, including region-to-tag, region-to-phrase, and image-to-sentence alignment, to bridge the gap between the two modalities. A comprehensive ablation study shows each granularity is helpful to learn a stronger pre-trained model. We adapt our pre-trained model to a set of V+L downstream tasks, including VQA, NLVR2, Visual Entailment, and RefCOCO+. Our model achieves the state-of-art performance in all these tasks under the unsupervised setting.