 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Model-in-the-Loop (MILO): Accelerating Multimodal AI Data Annotation with LLMs
Sep 16, 2024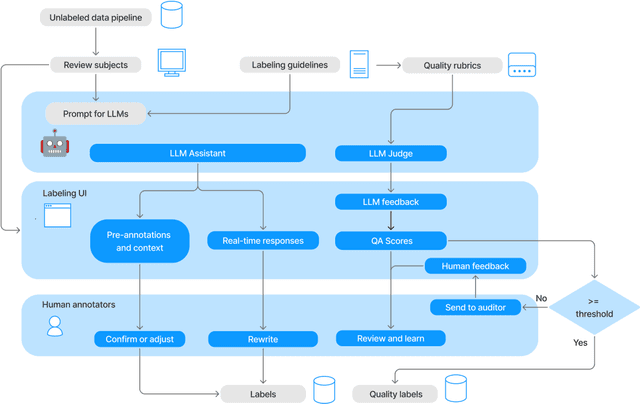

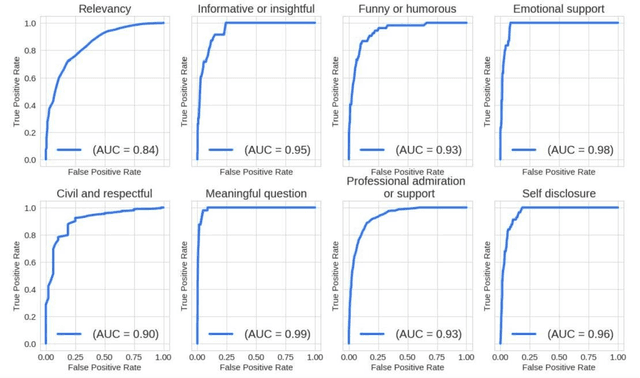
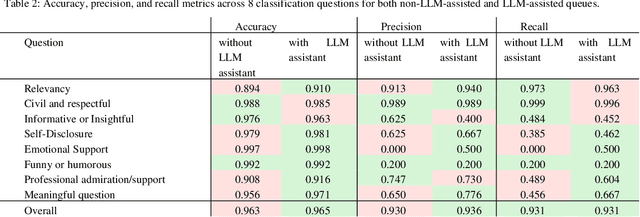
The growing demand for AI training data has transformed data annotation into a global industry, but traditional approaches relying on human annotators are often time-consuming, labor-intensive, and prone to inconsistent quality. We propose the Model-in-the-Loop (MILO) framework, which integrates AI/ML models into the annotation process. Our research introduces a collaborative paradigm that leverages the strengths of both professional human annotators and large language models (LLMs). By employing LLMs as pre-annotation and real-time assistants, and judges on annotator responses, MILO enables effective interaction patterns between human annotators and LLMs. Three empirical studies on multimodal data annotation demonstrate MILO's efficacy in reducing handling time, improving data quality, and enhancing annotator experiences. We also introduce quality rubrics for flexible evaluation and fine-grained feedback on open-ended annotations. The MILO framework has implications for accelerating AI/ML development, reducing reliance on human annotation alone, and promoting better alignment between human and machine values.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
FaD-VLP: Fashion Vision-and-Language Pre-training towards Unified Retrieval and Captioning
Oct 26, 2022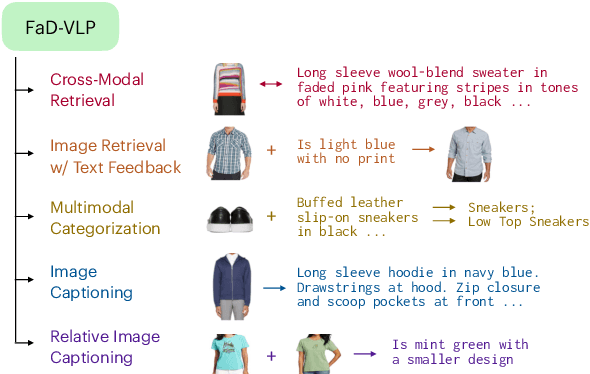

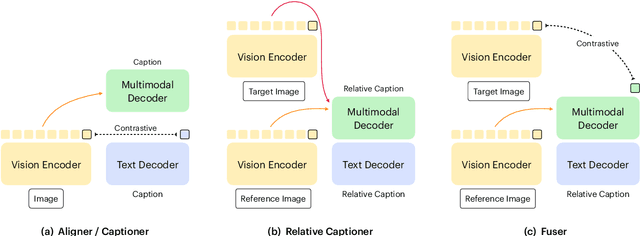
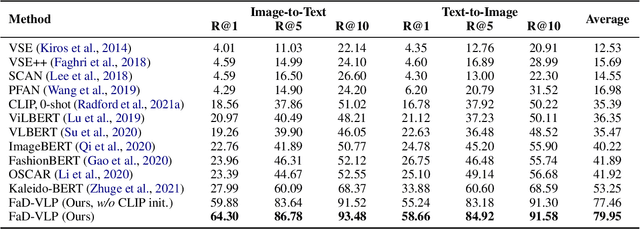
Multimodal tasks in the fashion domain have significant potential for e-commerce, but involve challenging vision-and-language learning problems - e.g., retrieving a fashion item given a reference image plus text feedback from a user. Prior works on multimodal fashion tasks have either been limited by the data in individual benchmarks, or have leveraged generic vision-and-language pre-training but have not taken advantage of the characteristics of fashion data. Additionally, these works have mainly been restricted to multimodal understanding tasks. To address these gaps, we make two key contributions. First, we propose a novel fashion-specific pre-training framework based on weakly-supervised triplets constructed from fashion image-text pairs. We show the triplet-based tasks are an effective addition to standard multimodal pre-training tasks. Second, we propose a flexible decoder-based model architecture capable of both fashion retrieval and captioning tasks. Together, our model design and pre-training approach are competitive on a diverse set of fashion tasks, including cross-modal retrieval, image retrieval with text feedback, image captioning, relative image captioning, and multimodal categorization.