 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Model-in-the-Loop (MILO): Accelerating Multimodal AI Data Annotation with LLMs
Sep 16, 2024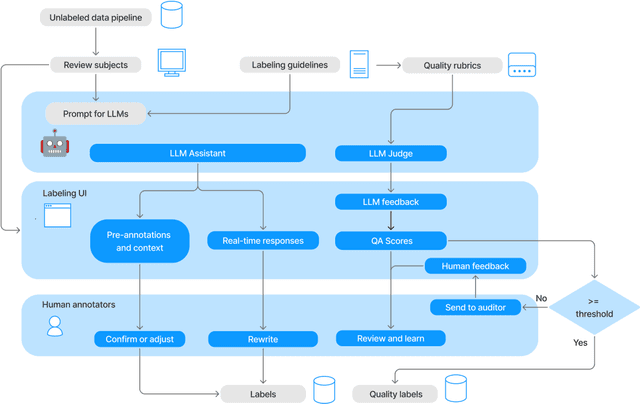

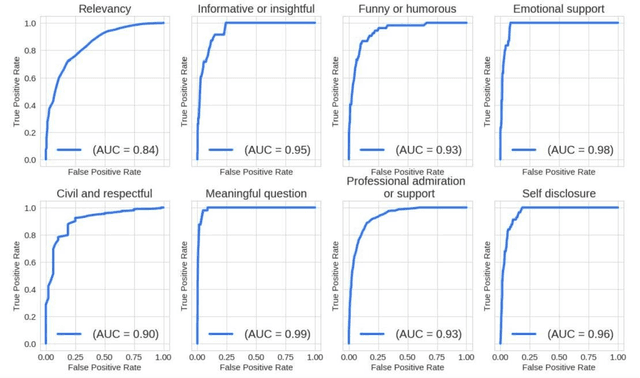
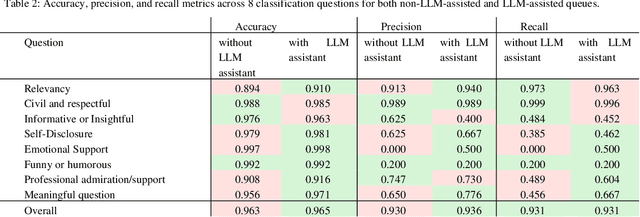
The growing demand for AI training data has transformed data annotation into a global industry, but traditional approaches relying on human annotators are often time-consuming, labor-intensive, and prone to inconsistent quality. We propose the Model-in-the-Loop (MILO) framework, which integrates AI/ML models into the annotation process. Our research introduces a collaborative paradigm that leverages the strengths of both professional human annotators and large language models (LLMs). By employing LLMs as pre-annotation and real-time assistants, and judges on annotator responses, MILO enables effective interaction patterns between human annotators and LLMs. Three empirical studies on multimodal data annotation demonstrate MILO's efficacy in reducing handling time, improving data quality, and enhancing annotator experiences. We also introduce quality rubrics for flexible evaluation and fine-grained feedback on open-ended annotations. The MILO framework has implications for accelerating AI/ML development, reducing reliance on human annotation alone, and promoting better alignment between human and machine values.
Propagating Variational Model Uncertainty for Bioacoustic Call Label Smoothing
Oct 19, 2022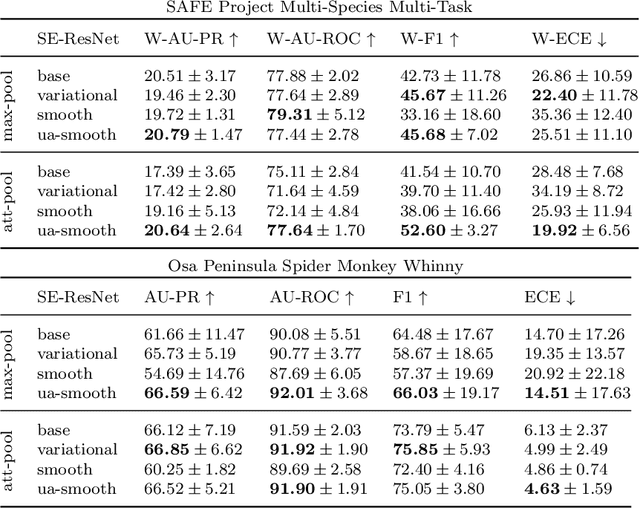


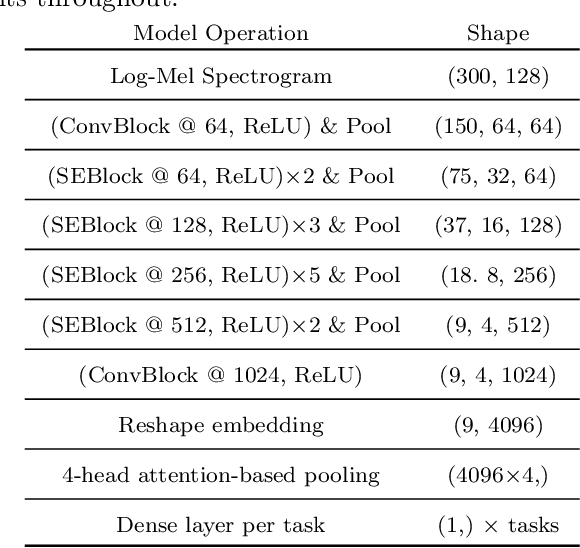
We focus on using the predictive uncertainty signal calculated by Bayesian neural networks to guide learning in the self-same task the model is being trained on. Not opting for costly Monte Carlo sampling of weights, we propagate the approximate hidden variance in an end-to-end manner, throughout a variational Bayesian adaptation of a ResNet with attention and squeeze-and-excitation blocks, in order to identify data samples that should contribute less into the loss value calculation. We, thus, propose uncertainty-aware, data-specific label smoothing, where the smoothing probability is dependent on this epistemic uncertainty. We show that, through the explicit usage of the epistemic uncertainty in the loss calculation, the variational model is led to improved predictive and calibration performance. This core machine learning methodology is exemplified at wildlife call detection, from audio recordings made via passive acoustic monitoring equipment in the animals' natural habitats, with the future goal of automating large scale annotation in a trustworthy manner.