 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReading Smiles: Proxy Bias in Foundation Models for Facial Emotion Recognition
Jun 23, 2025Foundation Models (FMs) are rapidly transforming Affective Computing (AC), with Vision Language Models (VLMs) now capable of recognising emotions in zero shot settings. This paper probes a critical but underexplored question: what visual cues do these models rely on to infer affect, and are these cues psychologically grounded or superficially learnt? We benchmark varying scale VLMs on a teeth annotated subset of AffectNet dataset and find consistent performance shifts depending on the presence of visible teeth. Through structured introspection of, the best-performing model, i.e., GPT-4o, we show that facial attributes like eyebrow position drive much of its affective reasoning, revealing a high degree of internal consistency in its valence-arousal predictions. These patterns highlight the emergent nature of FMs behaviour, but also reveal risks: shortcut learning, bias, and fairness issues especially in sensitive domains like mental health and education.
U-DiT TTS: U-Diffusion Vision Transformer for Text-to-Speech
May 22, 2023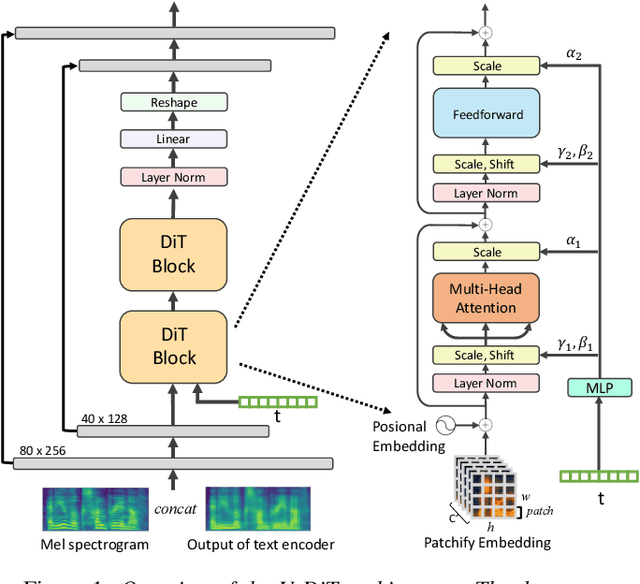

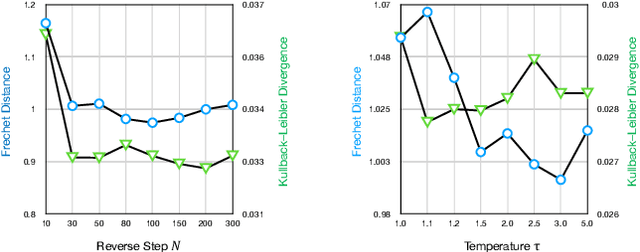
Deep learning has led to considerable advances in text-to-speech synthesis. Most recently, the adoption of Score-based Generative Models (SGMs), also known as Diffusion Probabilistic Models (DPMs), has gained traction due to their ability to produce high-quality synthesized neural speech in neural speech synthesis systems. In SGMs, the U-Net architecture and its variants have long dominated as the backbone since its first successful adoption. In this research, we mainly focus on the neural network in diffusion-model-based Text-to-Speech (TTS) systems and propose the U-DiT architecture, exploring the potential of vision transformer architecture as the core component of the diffusion models in a TTS system. The modular design of the U-DiT architecture, inherited from the best parts of U-Net and ViT, allows for great scalability and versatility across different data scales. The proposed U-DiT TTS system is a mel spectrogram-based acoustic model and utilizes a pretrained HiFi-GAN as the vocoder. The objective (ie Frechet distance) and MOS results show that our DiT-TTS system achieves state-of-art performance on the single speaker dataset LJSpeech. Our demos are publicly available at: https://eihw.github.io/u-dit-tts/
Propagating Variational Model Uncertainty for Bioacoustic Call Label Smoothing
Oct 19, 2022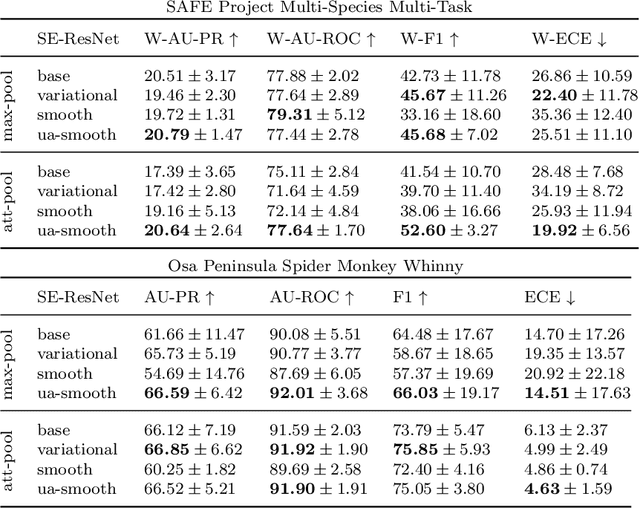


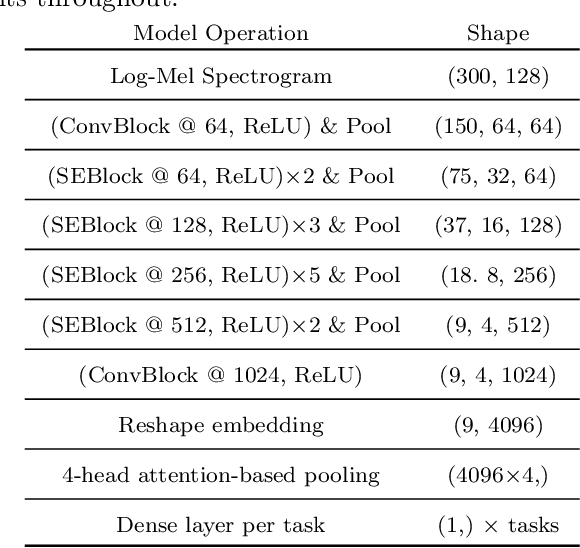
We focus on using the predictive uncertainty signal calculated by Bayesian neural networks to guide learning in the self-same task the model is being trained on. Not opting for costly Monte Carlo sampling of weights, we propagate the approximate hidden variance in an end-to-end manner, throughout a variational Bayesian adaptation of a ResNet with attention and squeeze-and-excitation blocks, in order to identify data samples that should contribute less into the loss value calculation. We, thus, propose uncertainty-aware, data-specific label smoothing, where the smoothing probability is dependent on this epistemic uncertainty. We show that, through the explicit usage of the epistemic uncertainty in the loss calculation, the variational model is led to improved predictive and calibration performance. This core machine learning methodology is exemplified at wildlife call detection, from audio recordings made via passive acoustic monitoring equipment in the animals' natural habitats, with the future goal of automating large scale annotation in a trustworthy manner.
Dynamic Restrained Uncertainty Weighting Loss for Multitask Learning of Vocal Expression
Jun 27, 2022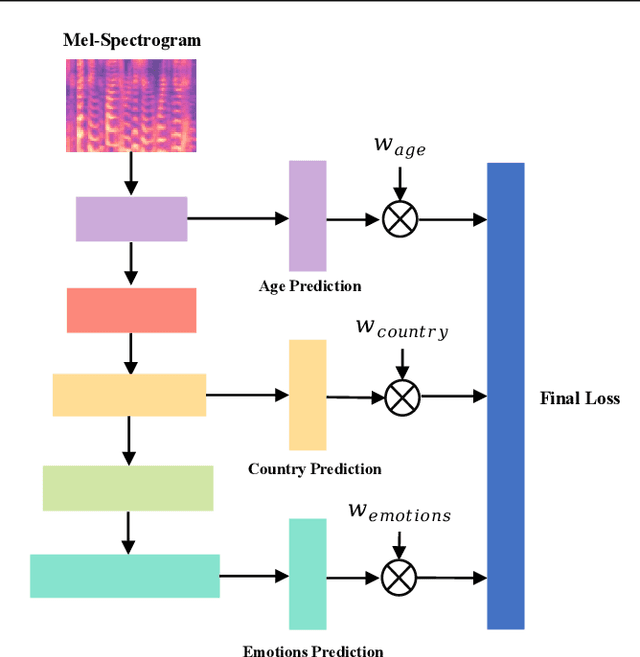
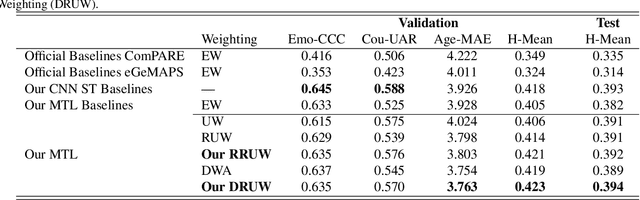
We propose a novel Dynamic Restrained Uncertainty Weighting Loss to experimentally handle the problem of balancing the contributions of multiple tasks on the ICML ExVo 2022 Challenge. The multitask aims to recognize expressed emotions and demographic traits from vocal bursts jointly. Our strategy combines the advantages of Uncertainty Weight and Dynamic Weight Average, by extending weights with a restraint term to make the learning process more explainable. We use a lightweight multi-exit CNN architecture to implement our proposed loss approach. The experimental H-Mean score (0.394) shows a substantial improvement over the baseline H-Mean score (0.335).
Audio Self-supervised Learning: A Survey
Mar 02, 2022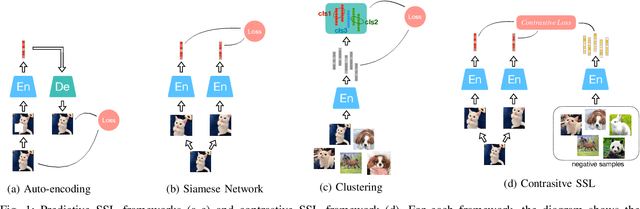
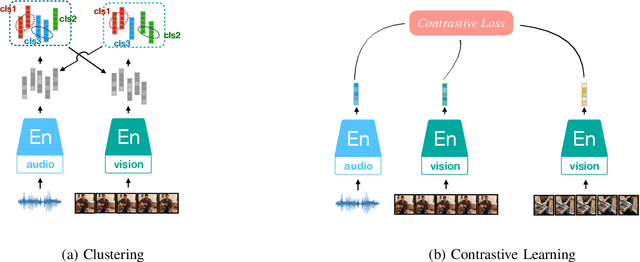
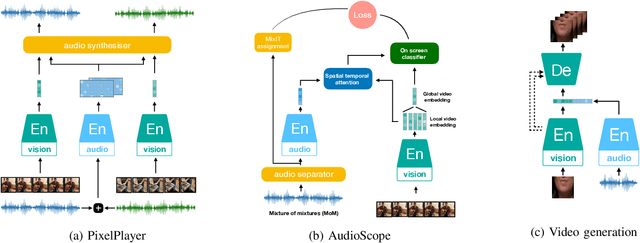
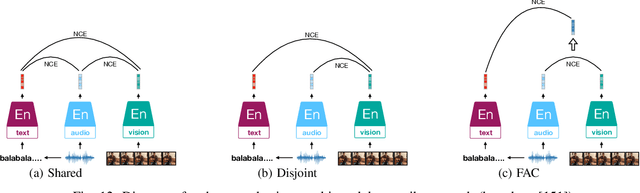
Inspired by the humans' cognitive ability to generalise knowledge and skills, Self-Supervised Learning (SSL) targets at discovering general representations from large-scale data without requiring human annotations, which is an expensive and time consuming task. Its success in the fields of computer vision and natural language processing have prompted its recent adoption into the field of audio and speech processing. Comprehensive reviews summarising the knowledge in audio SSL are currently missing. To fill this gap, in the present work, we provide an overview of the SSL methods used for audio and speech processing applications. Herein, we also summarise the empirical works that exploit the audio modality in multi-modal SSL frameworks, and the existing suitable benchmarks to evaluate the power of SSL in the computer audition domain. Finally, we discuss some open problems and point out the future directions on the development of audio SSL.
Evaluating Deep Music Generation Methods Using Data Augmentation
Dec 31, 2021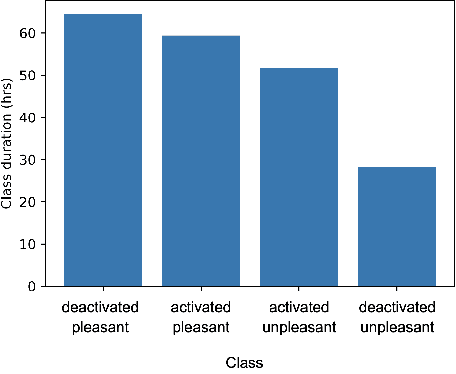
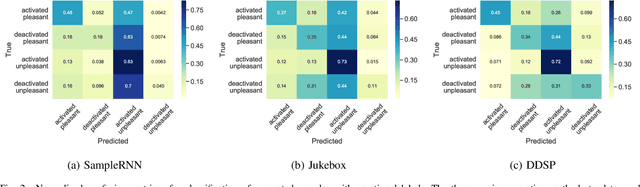
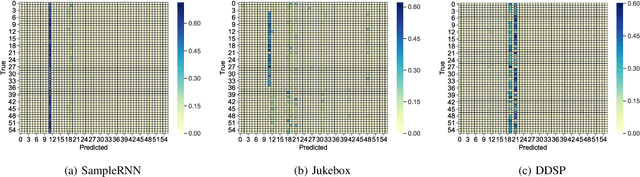
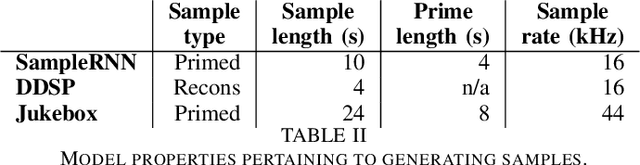
Despite advances in deep algorithmic music generation, evaluation of generated samples often relies on human evaluation, which is subjective and costly. We focus on designing a homogeneous, objective framework for evaluating samples of algorithmically generated music. Any engineered measures to evaluate generated music typically attempt to define the samples' musicality, but do not capture qualities of music such as theme or mood. We do not seek to assess the musical merit of generated music, but instead explore whether generated samples contain meaningful information pertaining to emotion or mood/theme. We achieve this by measuring the change in predictive performance of a music mood/theme classifier after augmenting its training data with generated samples. We analyse music samples generated by three models -- SampleRNN, Jukebox, and DDSP -- and employ a homogeneous framework across all methods to allow for objective comparison. This is the first attempt at augmenting a music genre classification dataset with conditionally generated music. We investigate the classification performance improvement using deep music generation and the ability of the generators to make emotional music by using an additional, emotion annotation of the dataset. Finally, we use a classifier trained on real data to evaluate the label validity of class-conditionally generated samples.
A deep matrix factorization method for learning attribute representations
Sep 10, 2015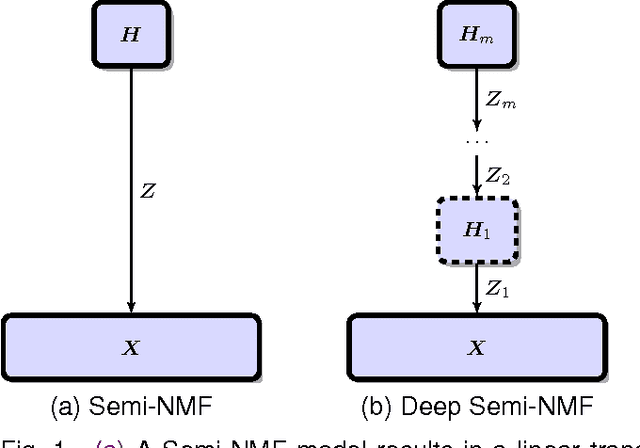
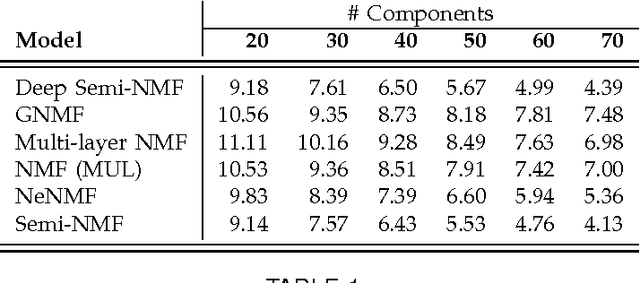
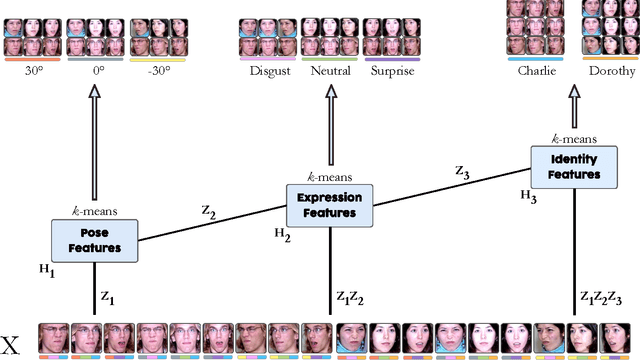

Semi-Non-negative Matrix Factorization is a technique that learns a low-dimensional representation of a dataset that lends itself to a clustering interpretation. It is possible that the mapping between this new representation and our original data matrix contains rather complex hierarchical information with implicit lower-level hidden attributes, that classical one level clustering methodologies can not interpret. In this work we propose a novel model, Deep Semi-NMF, that is able to learn such hidden representations that allow themselves to an interpretation of clustering according to different, unknown attributes of a given dataset. We also present a semi-supervised version of the algorithm, named Deep WSF, that allows the use of (partial) prior information for each of the known attributes of a dataset, that allows the model to be used on datasets with mixed attribute knowledge. Finally, we show that our models are able to learn low-dimensional representations that are better suited for clustering, but also classification, outperforming Semi-Non-negative Matrix Factorization, but also other state-of-the-art methodologies variants.