 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-DiT TTS: U-Diffusion Vision Transformer for Text-to-Speech
Paper and Code
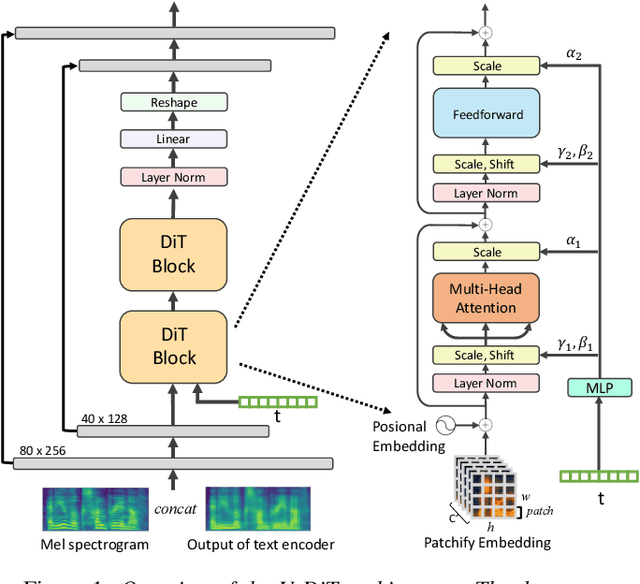

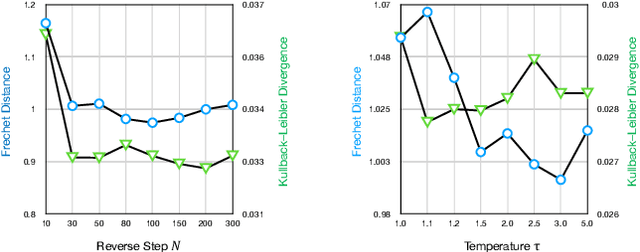
Deep learning has led to considerable advances in text-to-speech synthesis. Most recently, the adoption of Score-based Generative Models (SGMs), also known as Diffusion Probabilistic Models (DPMs), has gained traction due to their ability to produce high-quality synthesized neural speech in neural speech synthesis systems. In SGMs, the U-Net architecture and its variants have long dominated as the backbone since its first successful adoption. In this research, we mainly focus on the neural network in diffusion-model-based Text-to-Speech (TTS) systems and propose the U-DiT architecture, exploring the potential of vision transformer architecture as the core component of the diffusion models in a TTS system. The modular design of the U-DiT architecture, inherited from the best parts of U-Net and ViT, allows for great scalability and versatility across different data scales. The proposed U-DiT TTS system is a mel spectrogram-based acoustic model and utilizes a pretrained HiFi-GAN as the vocoder. The objective (ie Frechet distance) and MOS results show that our DiT-TTS system achieves state-of-art performance on the single speaker dataset LJSpeech. Our demos are publicly available at: https://eihw.github.io/u-dit-tts/