 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPiRi: Channel Permutation-Invariant Relational Interaction for Multivariate Time Series Forecasting
Jan 28, 2026Current methods for multivariate time series forecasting can be classified into channel-dependent and channel-independent models. Channel-dependent models learn cross-channel features but often overfit the channel ordering, which hampers adaptation when channels are added or reordered. Channel-independent models treat each channel in isolation to increase flexibility, yet this neglects inter-channel dependencies and limits performance. To address these limitations, we propose \textbf{CPiRi}, a \textbf{channel permutation invariant (CPI)} framework that infers cross-channel structure from data rather than memorizing a fixed ordering, enabling deployment in settings with structural and distributional co-drift without retraining. CPiRi couples \textbf{spatio-temporal decoupling architecture} with \textbf{permutation-invariant regularization training strategy}: a frozen pretrained temporal encoder extracts high-quality temporal features, a lightweight spatial module learns content-driven inter-channel relations, while a channel shuffling strategy enforces CPI during training. We further \textbf{ground CPiRi in theory} by analyzing permutation equivariance in multivariate time series forecasting. Experiments on multiple benchmarks show state-of-the-art results. CPiRi remains stable when channel orders are shuffled and exhibits strong \textbf{inductive generalization} to unseen channels even when trained on \textbf{only half} of the channels, while maintaining \textbf{practical efficiency} on large-scale datasets. The source code is released at https://github.com/JasonStraka/CPiRi.
SmoothCLAP: Soft-Target Enhanced Contrastive Language\--Audio Pretraining for Affective Computing
Jan 18, 2026The ambiguity of human emotions poses several challenges for machine learning models, as they often overlap and lack clear delineating boundaries. Contrastive language-audio pretraining (CLAP) has emerged as a key technique for generalisable emotion recognition. However, as conventional CLAP enforces a strict one-to-one alignment between paired audio-text samples, it overlooks intra-modal similarity and treats all non-matching pairs as equally negative. This conflicts with the fuzzy boundaries between different emotions. To address this limitation, we propose SmoothCLAP, which introduces softened targets derived from intra-modal similarity and paralinguistic features. By combining these softened targets with conventional contrastive supervision, SmoothCLAP learns embeddings that respect graded emotional relationships, while retaining the same inference pipeline as CLAP. Experiments on eight affective computing tasks across English and German demonstrate that SmoothCLAP is consistently achieving superior performance. Our results highlight that leveraging soft supervision is a promising strategy for building emotion-aware audio-text models.
MELT: Towards Automated Multimodal Emotion Data Annotation by Leveraging LLM Embedded Knowledge
May 30, 2025Although speech emotion recognition (SER) has advanced significantly with deep learning, annotation remains a major hurdle. Human annotation is not only costly but also subject to inconsistencies annotators often have different preferences and may lack the necessary contextual knowledge, which can lead to varied and inaccurate labels. Meanwhile, Large Language Models (LLMs) have emerged as a scalable alternative for annotating text data. However, the potential of LLMs to perform emotional speech data annotation without human supervision has yet to be thoroughly investigated. To address these problems, we apply GPT-4o to annotate a multimodal dataset collected from the sitcom Friends, using only textual cues as inputs. By crafting structured text prompts, our methodology capitalizes on the knowledge GPT-4o has accumulated during its training, showcasing that it can generate accurate and contextually relevant annotations without direct access to multimodal inputs. Therefore, we propose MELT, a multimodal emotion dataset fully annotated by GPT-4o. We demonstrate the effectiveness of MELT by fine-tuning four self-supervised learning (SSL) backbones and assessing speech emotion recognition performance across emotion datasets. Additionally, our subjective experiments\' results demonstrate a consistence performance improvement on SER.
MAD-UV: The 1st INTERSPEECH Mice Autism Detection via Ultrasound Vocalization Challenge
Jan 08, 2025


The Mice Autism Detection via Ultrasound Vocalization (MAD-UV) Challenge introduces the first INTERSPEECH challenge focused on detecting autism spectrum disorder (ASD) in mice through their vocalizations. Participants are tasked with developing models to automatically classify mice as either wild-type or ASD models based on recordings with a high sampling rate. Our baseline system employs a simple CNN-based classification using three different spectrogram features. Results demonstrate the feasibility of automated ASD detection, with the considered audible-range features achieving the best performance (UAR of 0.600 for segment-level and 0.625 for subject-level classification). This challenge bridges speech technology and biomedical research, offering opportunities to advance our understanding of ASD models through machine learning approaches. The findings suggest promising directions for vocalization analysis and highlight the potential value of audible and ultrasound vocalizations in ASD detection.
Audio-based Kinship Verification Using Age Domain Conversion
Oct 14, 2024


Audio-based kinship verification (AKV) is important in many domains, such as home security monitoring, forensic identification, and social network analysis. A key challenge in the task arises from differences in age across samples from different individuals, which can be interpreted as a domain bias in a cross-domain verification task. To address this issue, we design the notion of an "age-standardised domain" wherein we utilise the optimised CycleGAN-VC3 network to perform age-audio conversion to generate the in-domain audio. The generated audio dataset is employed to extract a range of features, which are then fed into a metric learning architecture to verify kinship. Experiments are conducted on the KAN_AV audio dataset, which contains age and kinship labels. The results demonstrate that the method markedly enhances the accuracy of kinship verification, while also offering novel insights for future kinship verification research.
CasFT: Future Trend Modeling for Information Popularity Prediction with Dynamic Cues-Driven Diffusion Models
Sep 25, 2024



The rapid spread of diverse information on online social platforms has prompted both academia and industry to realize the importance of predicting content popularity, which could benefit a wide range of applications, such as recommendation systems and strategic decision-making. Recent works mainly focused on extracting spatiotemporal patterns inherent in the information diffusion process within a given observation period so as to predict its popularity over a future period of time. However, these works often overlook the future popularity trend, as future popularity could either increase exponentially or stagnate, introducing uncertainties to the prediction performance. Additionally, how to transfer the preceding-term dynamics learned from the observed diffusion process into future-term trends remains an unexplored challenge. Against this background, we propose CasFT, which leverages observed information Cascades and dynamic cues extracted via neural ODEs as conditions to guide the generation of Future popularity-increasing Trends through a diffusion model. These generated trends are then combined with the spatiotemporal patterns in the observed information cascade to make the final popularity prediction. Extensive experiments conducted on three real-world datasets demonstrate that CasFT significantly improves the prediction accuracy, compared to state-of-the-art approaches, yielding 2.2%-19.3% improvement across different datasets.
On Your Mark, Get Set, Predict! Modeling Continuous-Time Dynamics of Cascades for Information Popularity Prediction
Sep 25, 2024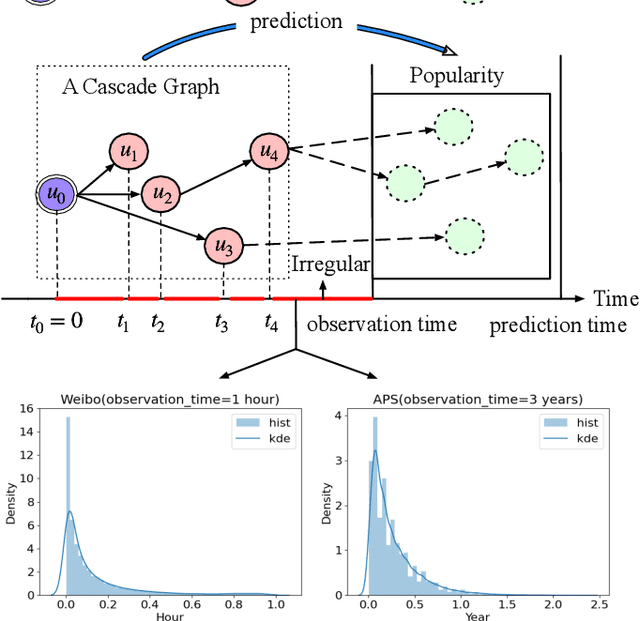
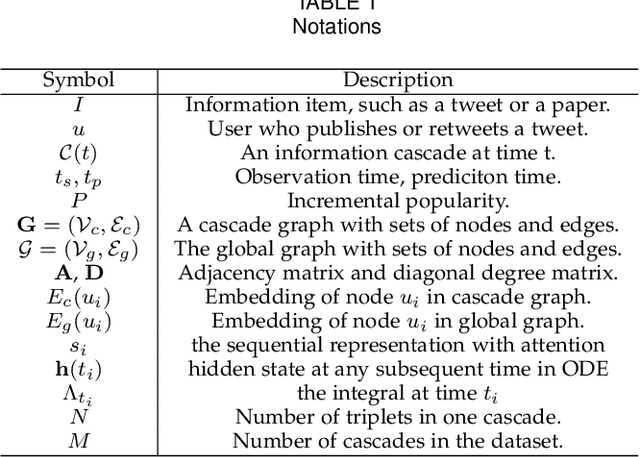
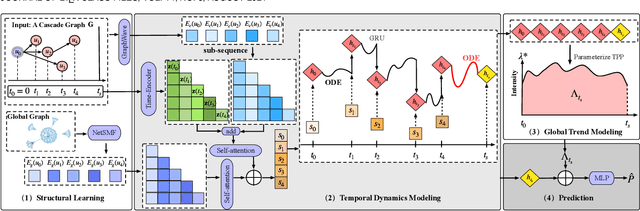

Information popularity prediction is important yet challenging in various domains, including viral marketing and news recommendations. The key to accurately predicting information popularity lies in subtly modeling the underlying temporal information diffusion process behind observed events of an information cascade, such as the retweets of a tweet. To this end, most existing methods either adopt recurrent networks to capture the temporal dynamics from the first to the last observed event or develop a statistical model based on self-exciting point processes to make predictions. However, information diffusion is intrinsically a complex continuous-time process with irregularly observed discrete events, which is oversimplified using recurrent networks as they fail to capture the irregular time intervals between events, or using self-exciting point processes as they lack flexibility to capture the complex diffusion process. Against this background, we propose ConCat, modeling the Continuous-time dynamics of Cascades for information popularity prediction. On the one hand, it leverages neural Ordinary Differential Equations (ODEs) to model irregular events of a cascade in continuous time based on the cascade graph and sequential event information. On the other hand, it considers cascade events as neural temporal point processes (TPPs) parameterized by a conditional intensity function which can also benefit the popularity prediction task. We conduct extensive experiments to evaluate ConCat on three real-world datasets. Results show that ConCat achieves superior performance compared to state-of-the-art baselines, yielding a 2.3%-33.2% improvement over the best-performing baselines across the three datasets.
Enhancing Emotional Text-to-Speech Controllability with Natural Language Guidance through Contrastive Learning and Diffusion Models
Sep 10, 2024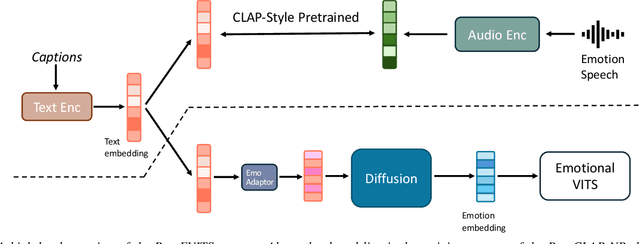
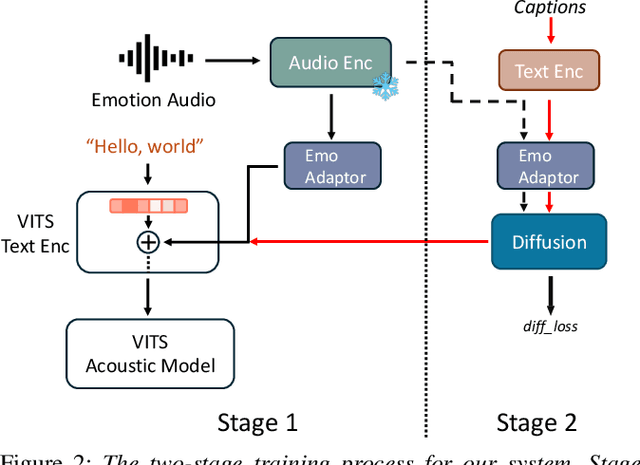

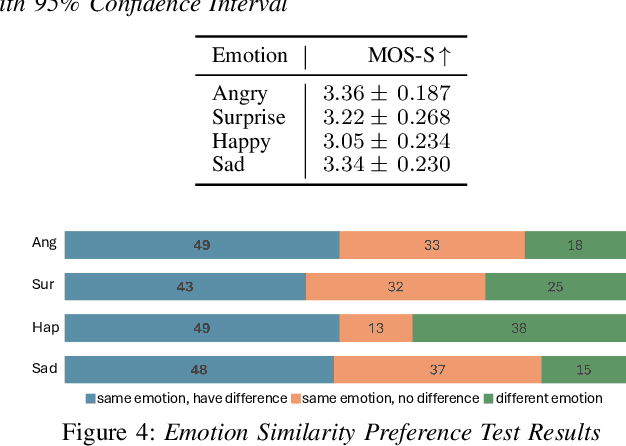
While current emotional text-to-speech (TTS) systems can generate highly intelligible emotional speech, achieving fine control over emotion rendering of the output speech still remains a significant challenge. In this paper, we introduce ParaEVITS, a novel emotional TTS framework that leverages the compositionality of natural language to enhance control over emotional rendering. By incorporating a text-audio encoder inspired by ParaCLAP, a contrastive language-audio pretraining (CLAP) model for computational paralinguistics, the diffusion model is trained to generate emotional embeddings based on textual emotional style descriptions. Our framework first trains on reference audio using the audio encoder, then fine-tunes a diffusion model to process textual inputs from ParaCLAP's text encoder. During inference, speech attributes such as pitch, jitter, and loudness are manipulated using only textual conditioning. Our experiments demonstrate that ParaEVITS effectively control emotion rendering without compromising speech quality. Speech demos are publicly available.
DB3V: A Dialect Dominated Dataset of Bird Vocalisation for Cross-corpus Bird Species Recognition
Jun 11, 2024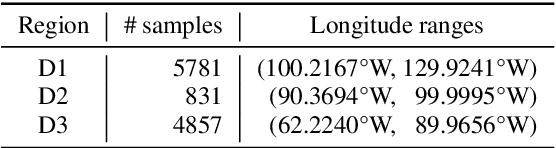
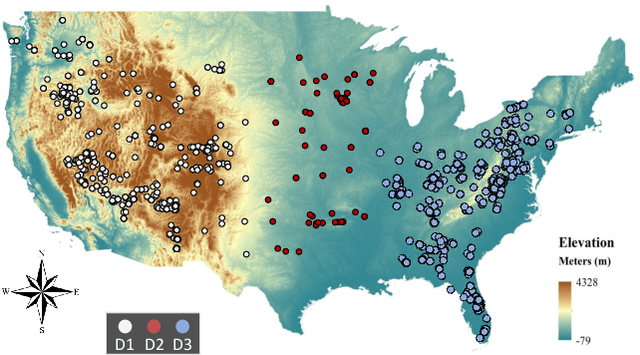
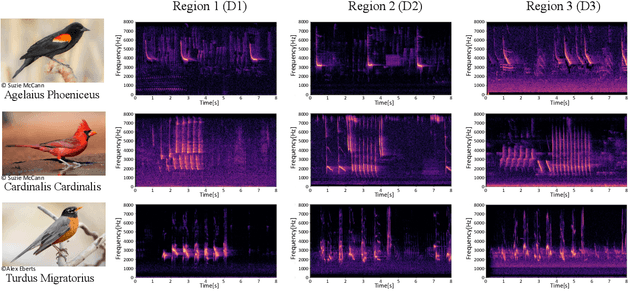
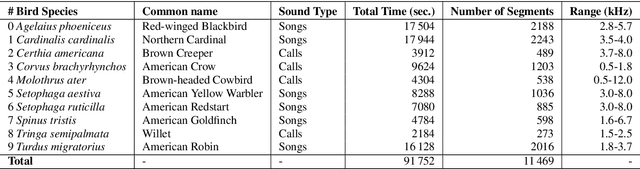
In ornithology, bird species are known to have variedit's widely acknowledged that bird species display diverse dialects in their calls across different regions. Consequently, computational methods to identify bird species onsolely through their calls face critsignificalnt challenges. There is growing interest in understanding the impact of species-specific dialects on the effectiveness of bird species recognition methods. Despite potential mitigation through the expansion of dialect datasets, the absence of publicly available testing data currently impedes robust benchmarking efforts. This paper presents the Dialect Dominated Dataset of Bird Vocalisation, the first cross-corpus dataset that focuses on dialects in bird vocalisations. The DB3V comprises more than 25 hours of audio recordings from 10 bird species distributed across three distinct regions in the contiguous United States (CONUS). In addition to presenting the dataset, we conduct analyses and establish baseline models for cross-corpus bird recognition. The data and code are publicly available online: https://zenodo.org/records/11544734
ParaCLAP -- Towards a general language-audio model for computational paralinguistic tasks
Jun 11, 2024Contrastive language-audio pretraining (CLAP) has recently emerged as a method for making audio analysis more generalisable. Specifically, CLAP-style models are able to `answer' a diverse set of language queries, extending the capabilities of audio models beyond a closed set of labels. However, CLAP relies on a large set of (audio, query) pairs for pretraining. While such sets are available for general audio tasks, like captioning or sound event detection, there are no datasets with matched audio and text queries for computational paralinguistic (CP) tasks. As a result, the community relies on generic CLAP models trained for general audio with limited success. In the present study, we explore training considerations for ParaCLAP, a CLAP-style model suited to CP, including a novel process for creating audio-language queries. We demonstrate its effectiveness on a set of computational paralinguistic tasks, where it is shown to surpass the performance of open-source state-of-the-art models.