 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAA-Net: A Sparse and Transferable Adversarial Attack for Speech Emotion Recognition
Paper and Code
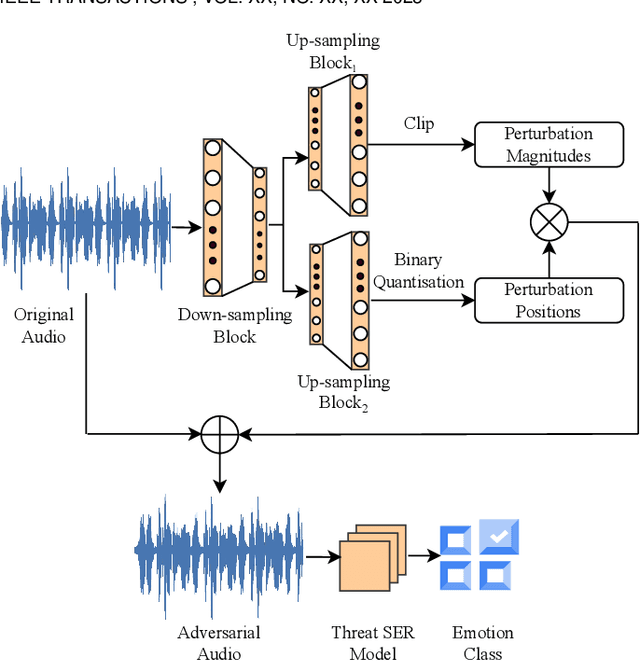
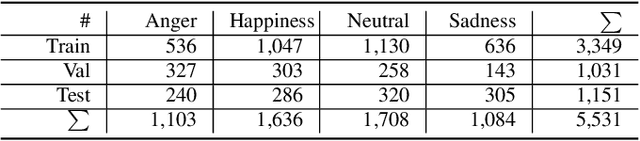
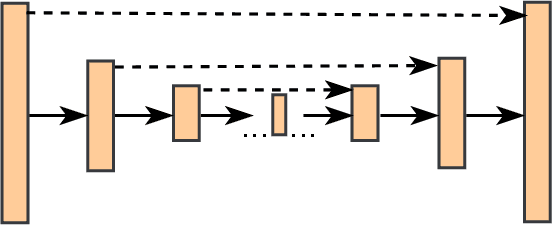
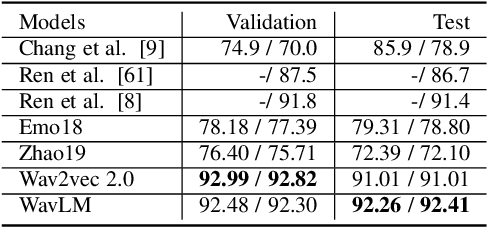
Speech contains rich information on the emotions of humans, and Speech Emotion Recognition (SER) has been an important topic in the area of human-computer interaction. The robustness of SER models is crucial, particularly in privacy-sensitive and reliability-demanding domains like private healthcare. Recently, the vulnerability of deep neural networks in the audio domain to adversarial attacks has become a popular area of research. However, prior works on adversarial attacks in the audio domain primarily rely on iterative gradient-based techniques, which are time-consuming and prone to overfitting the specific threat model. Furthermore, the exploration of sparse perturbations, which have the potential for better stealthiness, remains limited in the audio domain. To address these challenges, we propose a generator-based attack method to generate sparse and transferable adversarial examples to deceive SER models in an end-to-end and efficient manner. We evaluate our method on two widely-used SER datasets, Database of Elicited Mood in Speech (DEMoS) and Interactive Emotional dyadic MOtion CAPture (IEMOCAP), and demonstrate its ability to generate successful sparse adversarial examples in an efficient manner. Moreover, our generated adversarial examples exhibit model-agnostic transferability, enabling effective adversarial attacks on advanced victim models.