 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreathe with Me: Synchronizing Biosignals for User Embodiment in Robots
Dec 16, 2025Embodiment of users within robotic systems has been explored in human-robot interaction, most often in telepresence and teleoperation. In these applications, synchronized visuomotor feedback can evoke a sense of body ownership and agency, contributing to the experience of embodiment. We extend this work by employing embreathment, the representation of the user's own breath in real time, as a means for enhancing user embodiment experience in robots. In a within-subjects experiment, participants controlled a robotic arm, while its movements were either synchronized or non-synchronized with their own breath. Synchrony was shown to significantly increase body ownership, and was preferred by most participants. We propose the representation of physiological signals as a novel interoceptive pathway for human-robot interaction, and discuss implications for telepresence, prosthetics, collaboration with robots, and shared autonomy.
Machine Unlearning in Speech Emotion Recognition via Forget Set Alone
Oct 05, 2025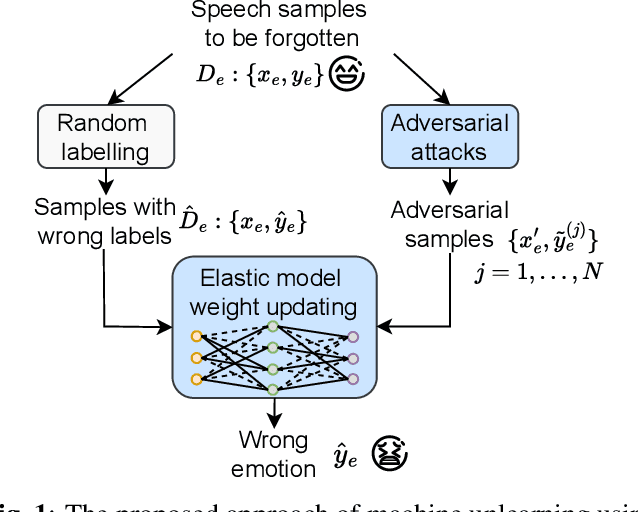
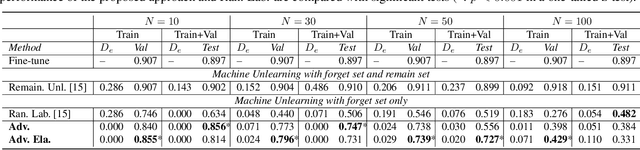

Speech emotion recognition aims to identify emotional states from speech signals and has been widely applied in human-computer interaction, education, healthcare, and many other fields. However, since speech data contain rich sensitive information, partial data can be required to be deleted by speakers due to privacy concerns. Current machine unlearning approaches largely depend on data beyond the samples to be forgotten. However, this reliance poses challenges when data redistribution is restricted and demands substantial computational resources in the context of big data. We propose a novel adversarial-attack-based approach that fine-tunes a pre-trained speech emotion recognition model using only the data to be forgotten. The experimental results demonstrate that the proposed approach can effectively remove the knowledge of the data to be forgotten from the model, while preserving high model performance on the test set for emotion recognition.
End-to-end Acoustic-linguistic Emotion and Intent Recognition Enhanced by Semi-supervised Learning
Jul 10, 2025Emotion and intent recognition from speech is essential and has been widely investigated in human-computer interaction. The rapid development of social media platforms, chatbots, and other technologies has led to a large volume of speech data streaming from users. Nevertheless, annotating such data manually is expensive, making it challenging to train machine learning models for recognition purposes. To this end, we propose applying semi-supervised learning to incorporate a large scale of unlabelled data alongside a relatively smaller set of labelled data. We train end-to-end acoustic and linguistic models, each employing multi-task learning for emotion and intent recognition. Two semi-supervised learning approaches, including fix-match learning and full-match learning, are compared. The experimental results demonstrate that the semi-supervised learning approaches improve model performance in speech emotion and intent recognition from both acoustic and text data. The late fusion of the best models outperforms the acoustic and text baselines by joint recognition balance metrics of 12.3% and 10.4%, respectively.
A Modular Pipeline for 3D Object Tracking Using RGB Cameras
Mar 06, 2025Object tracking is a key challenge of computer vision with various applications that all require different architectures. Most tracking systems have limitations such as constraining all movement to a 2D plane and they often track only one object. In this paper, we present a new modular pipeline that calculates 3D trajectories of multiple objects. It is adaptable to various settings where multiple time-synced and stationary cameras record moving objects, using off the shelf webcams. Our pipeline was tested on the Table Setting Dataset, where participants are recorded with various sensors as they set a table with tableware objects. We need to track these manipulated objects, using 6 rgb webcams. Challenges include: Detecting small objects in 9.874.699 camera frames, determining camera poses, discriminating between nearby and overlapping objects, temporary occlusions, and finally calculating a 3D trajectory using the right subset of an average of 11.12.456 pixel coordinates per 3-minute trial. We implement a robust pipeline that results in accurate trajectories with covariance of x,y,z-position as a confidence metric. It deals dynamically with appearing and disappearing objects, instantiating new Extended Kalman Filters. It scales to hundreds of table-setting trials with very little human annotation input, even with the camera poses of each trial unknown. The code is available at https://github.com/LarsBredereke/object_tracking
Deep Speech Synthesis from Multimodal Articulatory Representations
Dec 17, 2024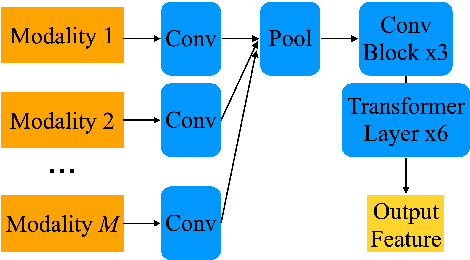
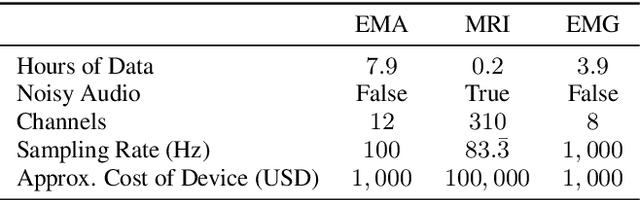
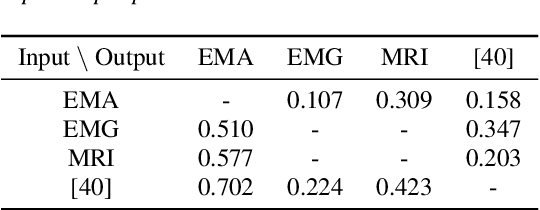

The amount of articulatory data available for training deep learning models is much less compared to acoustic speech data. In order to improve articulatory-to-acoustic synthesis performance in these low-resource settings, we propose a multimodal pre-training framework. On single-speaker speech synthesis tasks from real-time magnetic resonance imaging and surface electromyography inputs, the intelligibility of synthesized outputs improves noticeably. For example, compared to prior work, utilizing our proposed transfer learning methods improves the MRI-to-speech performance by 36% word error rate. In addition to these intelligibility results, our multimodal pre-trained models consistently outperform unimodal baselines on three objective and subjective synthesis quality metrics.
Investigating Effective Speaker Property Privacy Protection in Federated Learning for Speech Emotion Recognition
Oct 17, 2024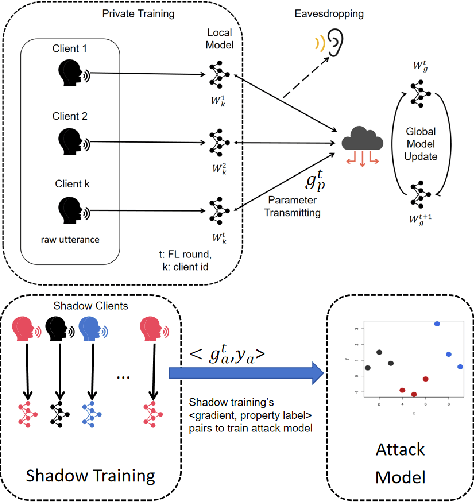

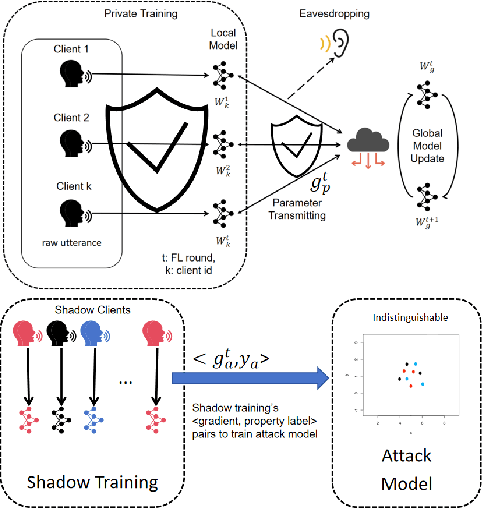
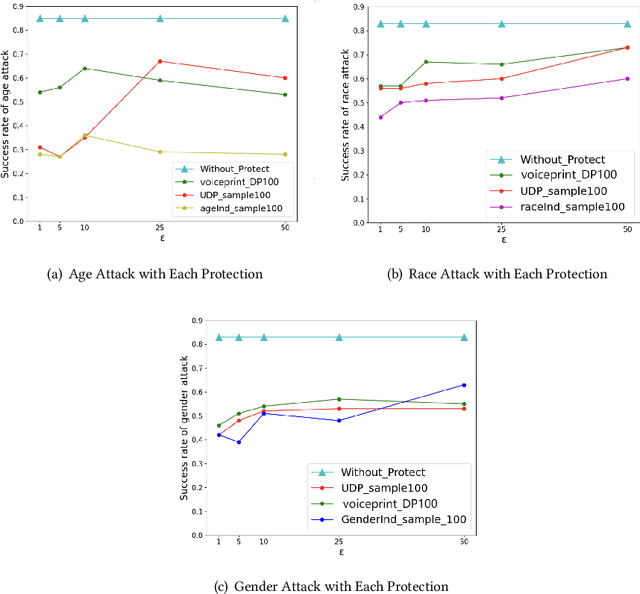
Federated Learning (FL) is a privacy-preserving approach that allows servers to aggregate distributed models transmitted from local clients rather than training on user data. More recently, FL has been applied to Speech Emotion Recognition (SER) for secure human-computer interaction applications. Recent research has found that FL is still vulnerable to inference attacks. To this end, this paper focuses on investigating the security of FL for SER concerning property inference attacks. We propose a novel method to protect the property information in speech data by decomposing various properties in the sound and adding perturbations to these properties. Our experiments show that the proposed method offers better privacy-utility trade-offs than existing methods. The trade-offs enable more effective attack prevention while maintaining similar FL utility levels. This work can guide future work on privacy protection methods in speech processing.
Speech as a Biomarker for Disease Detection
Sep 16, 2024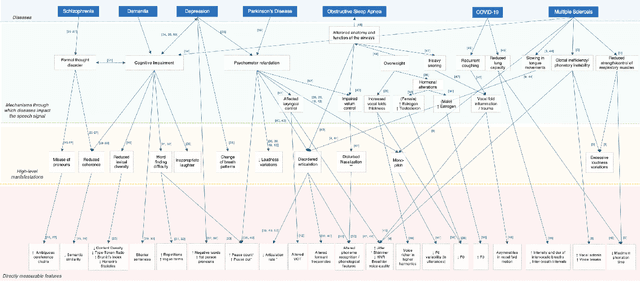
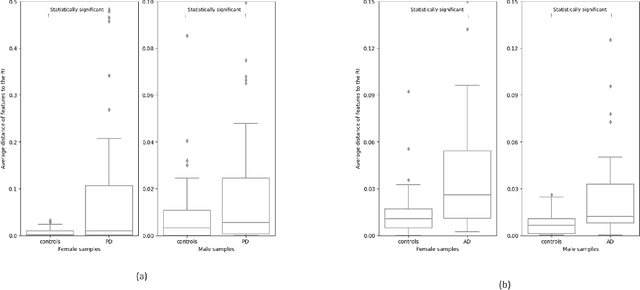

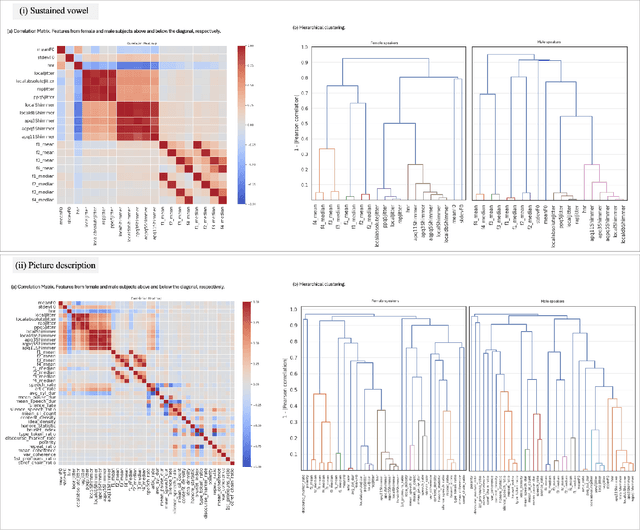
Speech is a rich biomarker that encodes substantial information about the health of a speaker, and thus it has been proposed for the detection of numerous diseases, achieving promising results. However, questions remain about what the models trained for the automatic detection of these diseases are actually learning and the basis for their predictions, which can significantly impact patients' lives. This work advocates for an interpretable health model, suitable for detecting several diseases, motivated by the observation that speech-affecting disorders often have overlapping effects on speech signals. A framework is presented that first defines "reference speech" and then leverages this definition for disease detection. Reference speech is characterized through reference intervals, i.e., the typical values of clinically meaningful acoustic and linguistic features derived from a reference population. This novel approach in the field of speech as a biomarker is inspired by the use of reference intervals in clinical laboratory science. Deviations of new speakers from this reference model are quantified and used as input to detect Alzheimer's and Parkinson's disease. The classification strategy explored is based on Neural Additive Models, a type of glass-box neural network, which enables interpretability. The proposed framework for reference speech characterization and disease detection is designed to support the medical community by providing clinically meaningful explanations that can serve as a valuable second opinion.
NeuroSpex: Neuro-Guided Speaker Extraction with Cross-Modal Attention
Sep 04, 2024
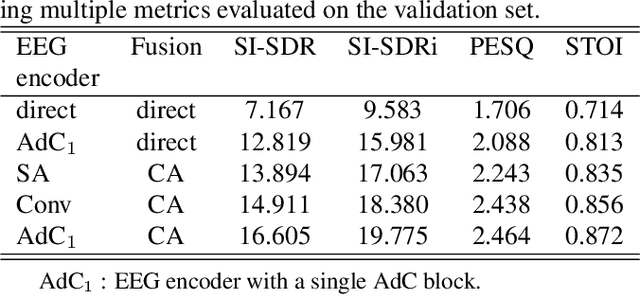
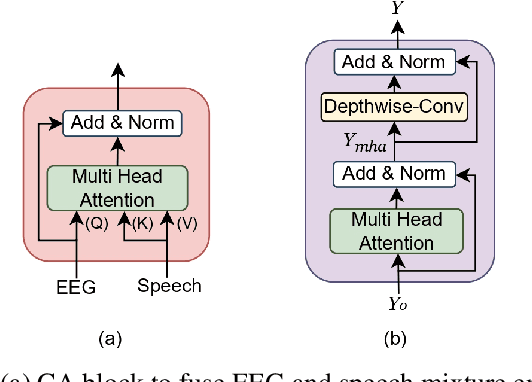
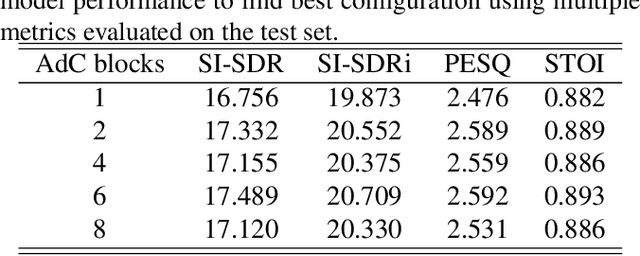
In the study of auditory attention, it has been revealed that there exists a robust correlation between attended speech and elicited neural responses, measurable through electroencephalography (EEG). Therefore, it is possible to use the attention information available within EEG signals to guide the extraction of the target speaker in a cocktail party computationally. In this paper, we present a neuro-guided speaker extraction model, i.e. NeuroSpex, using the EEG response of the listener as the sole auxiliary reference cue to extract attended speech from monaural speech mixtures. We propose a novel EEG signal encoder that captures the attention information. Additionally, we propose a cross-attention (CA) mechanism to enhance the speech feature representations, generating a speaker extraction mask. Experimental results on a publicly available dataset demonstrate that our proposed model outperforms two baseline models across various evaluation metrics.
On the Role of Visual Grounding in VQA
Jun 26, 2024



Visual Grounding (VG) in VQA refers to a model's proclivity to infer answers based on question-relevant image regions. Conceptually, VG identifies as an axiomatic requirement of the VQA task. In practice, however, DNN-based VQA models are notorious for bypassing VG by way of shortcut (SC) learning without suffering obvious performance losses in standard benchmarks. To uncover the impact of SC learning, Out-of-Distribution (OOD) tests have been proposed that expose a lack of VG with low accuracy. These tests have since been at the center of VG research and served as basis for various investigations into VG's impact on accuracy. However, the role of VG in VQA still remains not fully understood and has not yet been properly formalized. In this work, we seek to clarify VG's role in VQA by formalizing it on a conceptual level. We propose a novel theoretical framework called "Visually Grounded Reasoning" (VGR) that uses the concepts of VG and Reasoning to describe VQA inference in ideal OOD testing. By consolidating fundamental insights into VG's role in VQA, VGR helps to reveal rampant VG-related SC exploitation in OOD testing, which explains why the relationship between VG and OOD accuracy has been difficult to define. Finally, we propose an approach to create OOD tests that properly emphasize a requirement for VG, and show how to improve performance on them.
Speech Emotion Recognition under Resource Constraints with Data Distillation
Jun 21, 2024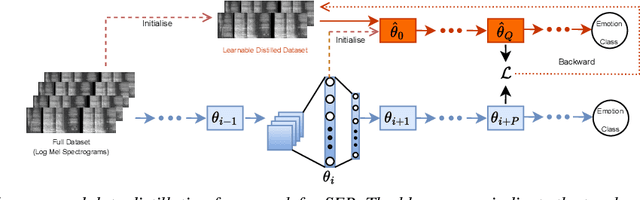
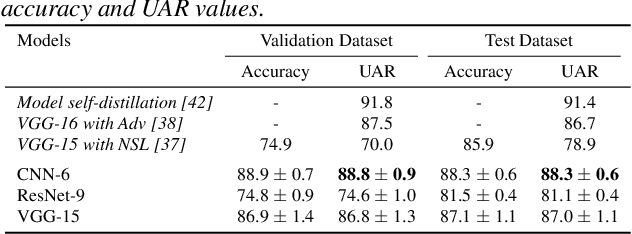
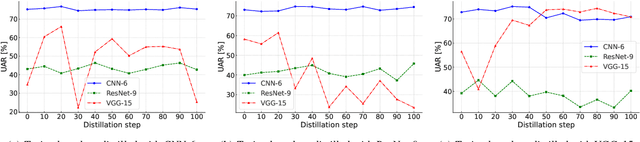
Speech emotion recognition (SER) plays a crucial role in human-computer interaction. The emergence of edge devices in the Internet of Things (IoT) presents challenges in constructing intricate deep learning models due to constraints in memory and computational resources. Moreover, emotional speech data often contains private information, raising concerns about privacy leakage during the deployment of SER models. To address these challenges, we propose a data distillation framework to facilitate efficient development of SER models in IoT applications using a synthesised, smaller, and distilled dataset. Our experiments demonstrate that the distilled dataset can be effectively utilised to train SER models with fixed initialisation, achieving performances comparable to those developed using the original full emotional speech dataset.