 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Effective Model Evaluation with Meta-Learning
May 22, 2026The rapid growth of machine learning has produced an ever-expanding ecosystem of models, making it increasingly challenging to verify the reliability of newly released models on unseen, unlabeled data. Conventional evaluation pipelines depend on expensive annotation, repeated fine-tuning, or narrow assumptions that fail to transfer across model families. We present MetaEvaluator, a cost-effective, model-agnostic framework for rapid, label-free assessment of unseen models spanning diverse architectures and modalities. MetaEvaluator leverages meta-learning over a pool of reference models to obtain a transferable initialization, enabling accurate evaluation of new models while amortizing cost across the pool and removing the need for per-model retraining. To the best of our knowledge, this is the first model-agnostic framework capable of evaluating new models on entirely unlabeled datasets. Extensive experiments show that MetaEvaluator produces stable and accurate performance estimates at substantially reduced cost compared to conventional approaches, making scalable benchmarking of emerging models on unlabeled data practical.
FINER-SQL: Boosting Small Language Models for Text-to-SQL
May 05, 2026Large language models have driven major advances in Text-to-SQL generation. However, they suffer from high computational cost, long latency, and data privacy concerns, which make them impractical for many real-world applications. A natural alternative is to use small language models (SLMs), which enable efficient and private on-premise deployment. Yet, SLMs often struggle with weak reasoning and poor instruction following. Conventional reinforcement learning methods based on sparse binary rewards (0/1) provide little learning signal when the generated SQLs are incorrect, leading to unstable or collapsed training. To overcome these issues, we propose FINER-SQL, a scalable and reusable reinforcement learning framework that enhances SLMs through fine-grained execution feedback. Built on group relative policy optimization, FINER-SQL replaces sparse supervision with dense and interpretable rewards that offer continuous feedback even for incorrect SQLs. It introduces two key reward functions: a memory reward, which aligns reasoning with verified traces for semantic stability, and an atomic reward, which measures operation-level overlap to grant partial credit for structurally correct but incomplete SQLs. This approach transforms discrete correctness into continuous learning, enabling stable, critic-free optimization. Experiments on the BIRD and Spider benchmarks show that FINER-SQL achieves up to 67.73\% and 85\% execution accuracy with a 3B model -- matching much larger LLMs while reducing inference latency to 5.57~s/sample. These results highlight a cost-efficient and privacy-preserving path toward high-performance Text-to-SQL generation. Our code is available at https://github.com/thanhdath/finer-sql.
AV-SQL: Decomposing Complex Text-to-SQL Queries with Agentic Views
Apr 08, 2026Text-to-SQL is the task of translating natural language queries into executable SQL for a given database, enabling non-expert users to access structured data without writing SQL manually. Despite rapid advances driven by large language models (LLMs), existing approaches still struggle with complex queries in real-world settings, where database schemas are large and questions require multi-step reasoning over many interrelated tables. In such cases, providing the full schema often exceeds the context window, while one-shot generation frequently produces non-executable SQL due to syntax errors and incorrect schema linking. To address these challenges, we introduce AV-SQL, a framework that decomposes complex Text-to-SQL into a pipeline of specialized LLM agents. Central to AV-SQL is the concept of agentic views: agent-generated Common Table Expressions (CTEs) that encapsulate intermediate query logic and filter relevant schema elements from large schemas. AV-SQL operates in three stages: (1) a rewriter agent compresses and clarifies the input query; (2) a view generator agent processes schema chunks to produce agentic views; and (3) a planner, generator, and revisor agent collaboratively compose these views into the final SQL query. Extensive experiments show that AV-SQL achieves 70.38% execution accuracy on the challenging Spider 2.0 benchmark, outperforming state-of-the-art baselines, while remaining competitive on standard datasets with 85.59% on Spider, 72.16% on BIRD and 63.78% on KaggleDBQA. Our source code is available at https://github.com/pminhtam/AV-SQL.
An Efficient and Effective Evaluator for Text2SQL Models on Unseen and Unlabeled Data
Mar 08, 2026Recent advances in large language models has strengthened Text2SQL systems that translate natural language questions into database queries. A persistent deployment challenge is to assess a newly trained Text2SQL system on an unseen and unlabeled dataset when no verified answers are available. This situation arises frequently because database content and structure evolve, privacy policies slow manual review, and carefully written SQL labels are costly and time-consuming. Without timely evaluation, organizations cannot approve releases or detect failures early. FusionSQL addresses this gap by working with any Text2SQL models and estimating accuracy without reference labels, allowing teams to measure quality on unseen and unlabeled datasets. It analyzes patterns in the system's own outputs to characterize how the target dataset differs from the material used during training. FusionSQL supports pre-release checks, continuous monitoring of new databases, and detection of quality decline. Experiments across diverse application settings and question types show that FusionSQL closely follows actual accuracy and reliably signals emerging issues. Our code is available at https://github.com/phkhanhtrinh23/FusionSQL.
A Multi-agent Text2SQL Framework using Small Language Models and Execution Feedback
Dec 21, 2025Text2SQL, the task of generating SQL queries from natural language text, is a critical challenge in data engineering. Recently, Large Language Models (LLMs) have demonstrated superior performance for this task due to their advanced comprehension and generation capabilities. However, privacy and cost considerations prevent companies from using Text2SQL solutions based on external LLMs offered as a service. Rather, small LLMs (SLMs) that are openly available and can hosted in-house are adopted. These SLMs, in turn, lack the generalization capabilities of larger LLMs, which impairs their effectiveness for complex tasks such as Text2SQL. To address these limitations, we propose MATS, a novel Text2SQL framework designed specifically for SLMs. MATS uses a multi-agent mechanism that assigns specialized roles to auxiliary agents, reducing individual workloads and fostering interaction. A training scheme based on reinforcement learning aligns these agents using feedback obtained during execution, thereby maintaining competitive performance despite a limited LLM size. Evaluation results using on benchmark datasets show that MATS, deployed on a single- GPU server, yields accuracy that are on-par with large-scale LLMs when using significantly fewer parameters. Our source code and data are available at https://github.com/thanhdath/mats-sql.
Scaling Text2SQL via LLM-efficient Schema Filtering with Functional Dependency Graph Rerankers
Dec 18, 2025Most modern Text2SQL systems prompt large language models (LLMs) with entire schemas -- mostly column information -- alongside the user's question. While effective on small databases, this approach fails on real-world schemas that exceed LLM context limits, even for commercial models. The recent Spider 2.0 benchmark exemplifies this with hundreds of tables and tens of thousands of columns, where existing systems often break. Current mitigations either rely on costly multi-step prompting pipelines or filter columns by ranking them against user's question independently, ignoring inter-column structure. To scale existing systems, we introduce \toolname, an open-source, LLM-efficient schema filtering framework that compacts Text2SQL prompts by (i) ranking columns with a query-aware LLM encoder enriched with values and metadata, (ii) reranking inter-connected columns via a lightweight graph transformer over functional dependencies, and (iii) selecting a connectivity-preserving sub-schema with a Steiner-tree heuristic. Experiments on real datasets show that \toolname achieves near-perfect recall and higher precision than CodeS, SchemaExP, Qwen rerankers, and embedding retrievers, while maintaining sub-second median latency and scaling to schemas with 23,000+ columns. Our source code is available at https://github.com/thanhdath/grast-sql.
Localizing Before Answering: A Hallucination Evaluation Benchmark for Grounded Medical Multimodal LLMs
May 05, 2025Medical Large Multi-modal Models (LMMs) have demonstrated remarkable capabilities in medical data interpretation. However, these models frequently generate hallucinations contradicting source evidence, particularly due to inadequate localization reasoning. This work reveals a critical limitation in current medical LMMs: instead of analyzing relevant pathological regions, they often rely on linguistic patterns or attend to irrelevant image areas when responding to disease-related queries. To address this, we introduce HEAL-MedVQA (Hallucination Evaluation via Localization MedVQA), a comprehensive benchmark designed to evaluate LMMs' localization abilities and hallucination robustness. HEAL-MedVQA features (i) two innovative evaluation protocols to assess visual and textual shortcut learning, and (ii) a dataset of 67K VQA pairs, with doctor-annotated anatomical segmentation masks for pathological regions. To improve visual reasoning, we propose the Localize-before-Answer (LobA) framework, which trains LMMs to localize target regions of interest and self-prompt to emphasize segmented pathological areas, generating grounded and reliable answers. Experimental results demonstrate that our approach significantly outperforms state-of-the-art biomedical LMMs on the challenging HEAL-MedVQA benchmark, advancing robustness in medical VQA.
Handling Heterophily in Recommender Systems with Wavelet Hypergraph Diffusion
Jan 24, 2025



Recommender systems are pivotal in delivering personalised user experiences across various domains. However, capturing the heterophily patterns and the multi-dimensional nature of user-item interactions poses significant challenges. To address this, we introduce FWHDNN (Fusion-based Wavelet Hypergraph Diffusion Neural Networks), an innovative framework aimed at advancing representation learning in hypergraph-based recommendation tasks. The model incorporates three key components: (1) a cross-difference relation encoder leveraging heterophily-aware hypergraph diffusion to adapt message-passing for diverse class labels, (2) a multi-level cluster-wise encoder employing wavelet transform-based hypergraph neural network layers to capture multi-scale topological relationships, and (3) an integrated multi-modal fusion mechanism that combines structural and textual information through intermediate and late-fusion strategies. Extensive experiments on real-world datasets demonstrate that FWHDNN surpasses state-of-the-art methods in accuracy, robustness, and scalability in capturing high-order interconnections between users and items.
Instruction-Guided Editing Controls for Images and Multimedia: A Survey in LLM era
Nov 15, 2024



The rapid advancement of large language models (LLMs) and multimodal learning has transformed digital content creation and manipulation. Traditional visual editing tools require significant expertise, limiting accessibility. Recent strides in instruction-based editing have enabled intuitive interaction with visual content, using natural language as a bridge between user intent and complex editing operations. This survey provides an overview of these techniques, focusing on how LLMs and multimodal models empower users to achieve precise visual modifications without deep technical knowledge. By synthesizing over 100 publications, we explore methods from generative adversarial networks to diffusion models, examining multimodal integration for fine-grained content control. We discuss practical applications across domains such as fashion, 3D scene manipulation, and video synthesis, highlighting increased accessibility and alignment with human intuition. Our survey compares existing literature, emphasizing LLM-empowered editing, and identifies key challenges to stimulate further research. We aim to democratize powerful visual editing across various industries, from entertainment to education. Interested readers are encouraged to access our repository at https://github.com/tamlhp/awesome-instruction-editing.
PDC-FRS: Privacy-preserving Data Contribution for Federated Recommender System
Sep 12, 2024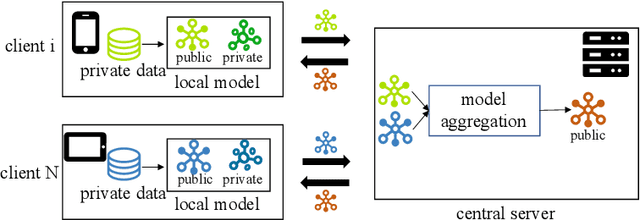
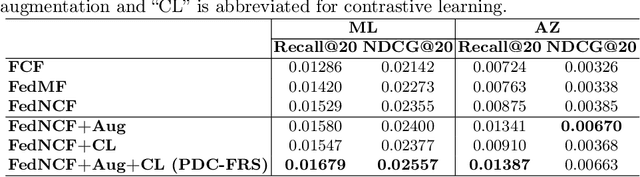
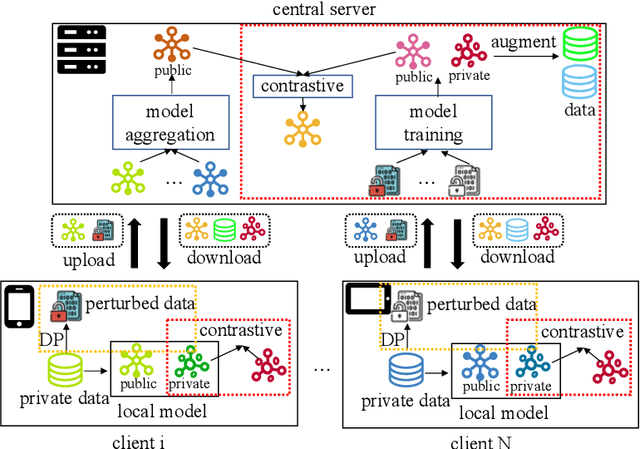
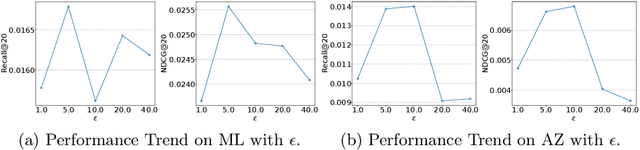
Federated recommender systems (FedRecs) have emerged as a popular research direction for protecting users' privacy in on-device recommendations. In FedRecs, users keep their data locally and only contribute their local collaborative information by uploading model parameters to a central server. While this rigid framework protects users' raw data during training, it severely compromises the recommendation model's performance due to the following reasons: (1) Due to the power law distribution nature of user behavior data, individual users have few data points to train a recommendation model, resulting in uploaded model updates that may be far from optimal; (2) As each user's uploaded parameters are learned from local data, which lacks global collaborative information, relying solely on parameter aggregation methods such as FedAvg to fuse global collaborative information may be suboptimal. To bridge this performance gap, we propose a novel federated recommendation framework, PDC-FRS. Specifically, we design a privacy-preserving data contribution mechanism that allows users to share their data with a differential privacy guarantee. Based on the shared but perturbed data, an auxiliary model is trained in parallel with the original federated recommendation process. This auxiliary model enhances FedRec by augmenting each user's local dataset and integrating global collaborative information. To demonstrate the effectiveness of PDC-FRS, we conduct extensive experiments on two widely used recommendation datasets. The empirical results showcase the superiority of PDC-FRS compared to baseline methods.