 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Effective Model Evaluation with Meta-Learning
May 22, 2026The rapid growth of machine learning has produced an ever-expanding ecosystem of models, making it increasingly challenging to verify the reliability of newly released models on unseen, unlabeled data. Conventional evaluation pipelines depend on expensive annotation, repeated fine-tuning, or narrow assumptions that fail to transfer across model families. We present MetaEvaluator, a cost-effective, model-agnostic framework for rapid, label-free assessment of unseen models spanning diverse architectures and modalities. MetaEvaluator leverages meta-learning over a pool of reference models to obtain a transferable initialization, enabling accurate evaluation of new models while amortizing cost across the pool and removing the need for per-model retraining. To the best of our knowledge, this is the first model-agnostic framework capable of evaluating new models on entirely unlabeled datasets. Extensive experiments show that MetaEvaluator produces stable and accurate performance estimates at substantially reduced cost compared to conventional approaches, making scalable benchmarking of emerging models on unlabeled data practical.
AV-SQL: Decomposing Complex Text-to-SQL Queries with Agentic Views
Apr 08, 2026Text-to-SQL is the task of translating natural language queries into executable SQL for a given database, enabling non-expert users to access structured data without writing SQL manually. Despite rapid advances driven by large language models (LLMs), existing approaches still struggle with complex queries in real-world settings, where database schemas are large and questions require multi-step reasoning over many interrelated tables. In such cases, providing the full schema often exceeds the context window, while one-shot generation frequently produces non-executable SQL due to syntax errors and incorrect schema linking. To address these challenges, we introduce AV-SQL, a framework that decomposes complex Text-to-SQL into a pipeline of specialized LLM agents. Central to AV-SQL is the concept of agentic views: agent-generated Common Table Expressions (CTEs) that encapsulate intermediate query logic and filter relevant schema elements from large schemas. AV-SQL operates in three stages: (1) a rewriter agent compresses and clarifies the input query; (2) a view generator agent processes schema chunks to produce agentic views; and (3) a planner, generator, and revisor agent collaboratively compose these views into the final SQL query. Extensive experiments show that AV-SQL achieves 70.38% execution accuracy on the challenging Spider 2.0 benchmark, outperforming state-of-the-art baselines, while remaining competitive on standard datasets with 85.59% on Spider, 72.16% on BIRD and 63.78% on KaggleDBQA. Our source code is available at https://github.com/pminhtam/AV-SQL.
An Efficient and Effective Evaluator for Text2SQL Models on Unseen and Unlabeled Data
Mar 08, 2026Recent advances in large language models has strengthened Text2SQL systems that translate natural language questions into database queries. A persistent deployment challenge is to assess a newly trained Text2SQL system on an unseen and unlabeled dataset when no verified answers are available. This situation arises frequently because database content and structure evolve, privacy policies slow manual review, and carefully written SQL labels are costly and time-consuming. Without timely evaluation, organizations cannot approve releases or detect failures early. FusionSQL addresses this gap by working with any Text2SQL models and estimating accuracy without reference labels, allowing teams to measure quality on unseen and unlabeled datasets. It analyzes patterns in the system's own outputs to characterize how the target dataset differs from the material used during training. FusionSQL supports pre-release checks, continuous monitoring of new databases, and detection of quality decline. Experiments across diverse application settings and question types show that FusionSQL closely follows actual accuracy and reliably signals emerging issues. Our code is available at https://github.com/phkhanhtrinh23/FusionSQL.
Instruction-Guided Editing Controls for Images and Multimedia: A Survey in LLM era
Nov 15, 2024



The rapid advancement of large language models (LLMs) and multimodal learning has transformed digital content creation and manipulation. Traditional visual editing tools require significant expertise, limiting accessibility. Recent strides in instruction-based editing have enabled intuitive interaction with visual content, using natural language as a bridge between user intent and complex editing operations. This survey provides an overview of these techniques, focusing on how LLMs and multimodal models empower users to achieve precise visual modifications without deep technical knowledge. By synthesizing over 100 publications, we explore methods from generative adversarial networks to diffusion models, examining multimodal integration for fine-grained content control. We discuss practical applications across domains such as fashion, 3D scene manipulation, and video synthesis, highlighting increased accessibility and alignment with human intuition. Our survey compares existing literature, emphasizing LLM-empowered editing, and identifies key challenges to stimulate further research. We aim to democratize powerful visual editing across various industries, from entertainment to education. Interested readers are encouraged to access our repository at https://github.com/tamlhp/awesome-instruction-editing.
UniBridge: A Unified Approach to Cross-Lingual Transfer Learning for Low-Resource Languages
Jun 17, 2024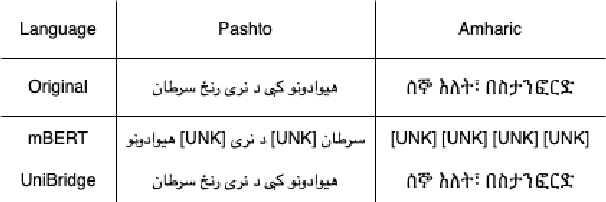

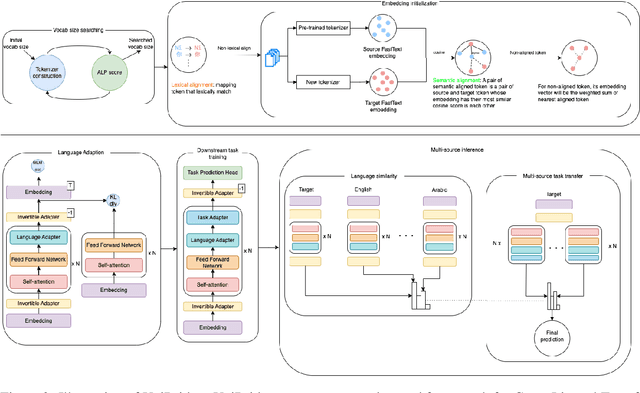

In this paper, we introduce UniBridge (Cross-Lingual Transfer Learning with Optimized Embeddings and Vocabulary), a comprehensive approach developed to improve the effectiveness of Cross-Lingual Transfer Learning, particularly in languages with limited resources. Our approach tackles two essential elements of a language model: the initialization of embeddings and the optimal vocabulary size. Specifically, we propose a novel embedding initialization method that leverages both lexical and semantic alignment for a language. In addition, we present a method for systematically searching for the optimal vocabulary size, ensuring a balance between model complexity and linguistic coverage. Our experiments across multilingual datasets show that our approach greatly improves the F1-Score in several languages. UniBridge is a robust and adaptable solution for cross-lingual systems in various languages, highlighting the significance of initializing embeddings and choosing the right vocabulary size in cross-lingual environments.
LAMPAT: Low-Rank Adaption for Multilingual Paraphrasing Using Adversarial Training
Jan 09, 2024Paraphrases are texts that convey the same meaning while using different words or sentence structures. It can be used as an automatic data augmentation tool for many Natural Language Processing tasks, especially when dealing with low-resource languages, where data shortage is a significant problem. To generate a paraphrase in multilingual settings, previous studies have leveraged the knowledge from the machine translation field, i.e., forming a paraphrase through zero-shot machine translation in the same language. Despite good performance on human evaluation, those methods still require parallel translation datasets, thus making them inapplicable to languages that do not have parallel corpora. To mitigate that problem, we proposed the first unsupervised multilingual paraphrasing model, LAMPAT ($\textbf{L}$ow-rank $\textbf{A}$daptation for $\textbf{M}$ultilingual $\textbf{P}$araphrasing using $\textbf{A}$dversarial $\textbf{T}$raining), by which monolingual dataset is sufficient enough to generate a human-like and diverse sentence. Throughout the experiments, we found out that our method not only works well for English but can generalize on unseen languages as well. Data and code are available at https://github.com/phkhanhtrinh23/LAMPAT.