 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric and Stochastic Analysis of Discontinuities in Sparse Mixture-of-Experts
Jun 17, 2026Sparse Mixture-of-Experts (SMoE) architectures are now widely deployed in state-of-the-art language and vision models, where conditional routing allows scaling to very large networks. However, this very Top-$k$ expert selection that enables conditional routing also renders the SMoE map inherently discontinuous. In the vicinity of these discontinuity surfaces, even inputs that are arbitrarily close may activate substantially different sets of experts resulting in significantly different outputs. In this work we give a rigorous geometric and stochastic analysis of these discontinuities. We first classify them by order, determined by the number of tied experts at a switching event. Using measure-theoretic slicing arguments, we establish asymptotic volume estimates for the thickened discontinuity surfaces, showing that lower-order discontinuity sets dominate, whereas higher-order ones occupy a vanishingly small relative volume. Next, modeling random perturbations in the input space via a diffusion process, we prove that the path eventually encounter a discontinuity, and moreover that the first hit almost surely occurs on an order-1 discontinuity with explicit finite-time probability bounds. We further derive occupation-time bounds that quantify the duration the random path spend in the neighborhoods of each discontinuity order. These theoretical results imply that inputs are more likely to lie near lower order discontinuities. Motivated by this insight, we propose a simple smoothing mechanism that can be directly applied to existing SMoEs, softly incorporating experts near discontinuities; our analysis guarantees that the added computational overhead remains small while providing localized smoothing near discontinuities, and experiments across language and vision tasks show that smoothing not only enforces continuity of the SMoE map but also enhances empirical performance.
WINDQuant: Weight-Informed Neural Decision-Making for Global Mixed-Precision LLM Quantization
May 26, 2026Quantization is an effective approach to reduce the memory footprint and inference cost of large language models (LLMs), yet maintaining performance in the ultra-low-bit regime remains challenging. Existing post-training methods often suffer from severe accuracy degradation, while quantization-aware training requires costly retraining and additional resources. Moreover, most mixed-precision strategies rely on coarse-grained or heuristic sensitivity analysis that overlooks fine-grained variations within weight matrices. We propose WINDQuant, a reinforcement-learning-based allocation controller for ultra-low-bit LLM quantization. Rather than introducing another low-level quantization operator, WINDQuant learns how to assign bit-widths and quantization treatments to fine-grained column chunks under a global storage budget. By operating at the column-chunk level, WINDQuant enables flexible and fine-grained precision assignment within layers under a global target bit-width. The implementation combines PPO with activation-aware calibration, lightweight per-unit quantizer fitting, and explicit effective-bit accounting of the learned mixed-precision plan. Experiments on LLaMA models demonstrate that WINDQuant achieves competitive performance in ultra-low-bit settings while reducing optimization overhead relative to retraining-based approaches, highlighting reinforcement learning as a practical controller for adaptive mixed-precision quantization.
Transformers Learn Robust In-Context Regression under Distributional Uncertainty
Mar 19, 2026Recent work has shown that Transformers can perform in-context learning for linear regression under restrictive assumptions, including i.i.d. data, Gaussian noise, and Gaussian regression coefficients. However, real-world data often violate these assumptions: the distributions of inputs, noise, and coefficients are typically unknown, non-Gaussian, and may exhibit dependency across the prompt. This raises a fundamental question: can Transformers learn effectively in-context under realistic distributional uncertainty? We study in-context learning for noisy linear regression under a broad range of distributional shifts, including non-Gaussian coefficients, heavy-tailed noise, and non-i.i.d. prompts. We compare Transformers against classical baselines that are optimal or suboptimal under the corresponding maximum-likelihood criteria. Across all settings, Transformers consistently match or outperform these baselines, demonstrating robust in-context adaptation beyond classical estimators.
Leveraging Sentence-oriented Augmentation and Transformer-Based Architecture for Vietnamese-Bahnaric Translation
Jan 27, 2026The Bahnar people, an ethnic minority in Vietnam with a rich ancestral heritage, possess a language of immense cultural and historical significance. The government places a strong emphasis on preserving and promoting the Bahnaric language by making it accessible online and encouraging communication across generations. Recent advancements in artificial intelligence, such as Neural Machine Translation (NMT), have brought about a transformation in translation by improving accuracy and fluency. This, in turn, contributes to the revival of the language through educational efforts, communication, and documentation. Specifically, NMT is pivotal in enhancing accessibility for Bahnaric speakers, making information and content more readily available. Nevertheless, the translation of Vietnamese into Bahnaric faces practical challenges due to resource constraints, especially given the limited resources available for the Bahnaric language. To address this, we employ state-of-the-art techniques in NMT along with two augmentation strategies for domain-specific Vietnamese-Bahnaric translation task. Importantly, both approaches are flexible and can be used with various neural machine translation models. Additionally, they do not require complex data preprocessing steps, the training of additional systems, or the acquisition of extra data beyond the existing training parallel corpora.
Low-Resource Heuristics for Bahnaric Optical Character Recognition Improvement
Jan 06, 2026Bahnar, a minority language spoken across Vietnam, Cambodia, and Laos, faces significant preservation challenges due to limited research and data availability. This study addresses the critical need for accurate digitization of Bahnar language documents through optical character recognition (OCR) technology. Digitizing scanned paper documents poses significant challenges, as degraded image quality from broken or blurred areas introduces considerable OCR errors that compromise information retrieval systems. We propose a comprehensive approach combining advanced table and non-table detection techniques with probability-based post-processing heuristics to enhance recognition accuracy. Our method first applies detection algorithms to improve input data quality, then employs probabilistic error correction on OCR output. Experimental results indicate a substantial improvement, with recognition accuracy increasing from 72.86% to 79.26%. This work contributes valuable resources for Bahnar language preservation and provides a framework applicable to other minority language digitization efforts.
Speaking in Words, Thinking in Logic: A Dual-Process Framework in QA Systems
Jul 28, 2025Recent advances in large language models (LLMs) have significantly enhanced question-answering (QA) capabilities, particularly in open-domain contexts. However, in closed-domain scenarios such as education, healthcare, and law, users demand not only accurate answers but also transparent reasoning and explainable decision-making processes. While neural-symbolic (NeSy) frameworks have emerged as a promising solution, leveraging LLMs for natural language understanding and symbolic systems for formal reasoning, existing approaches often rely on large-scale models and exhibit inefficiencies in translating natural language into formal logic representations. To address these limitations, we introduce Text-JEPA (Text-based Joint-Embedding Predictive Architecture), a lightweight yet effective framework for converting natural language into first-order logic (NL2FOL). Drawing inspiration from dual-system cognitive theory, Text-JEPA emulates System 1 by efficiently generating logic representations, while the Z3 solver operates as System 2, enabling robust logical inference. To rigorously evaluate the NL2FOL-to-reasoning pipeline, we propose a comprehensive evaluation framework comprising three custom metrics: conversion score, reasoning score, and Spearman rho score, which collectively capture the quality of logical translation and its downstream impact on reasoning accuracy. Empirical results on domain-specific datasets demonstrate that Text-JEPA achieves competitive performance with significantly lower computational overhead compared to larger LLM-based systems. Our findings highlight the potential of structured, interpretable reasoning frameworks for building efficient and explainable QA systems in specialized domains.
URAG: Implementing a Unified Hybrid RAG for Precise Answers in University Admission Chatbots -- A Case Study at HCMUT
Jan 27, 2025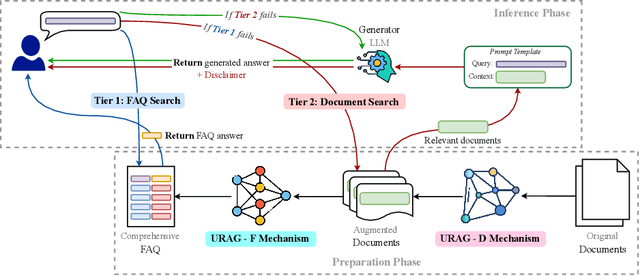

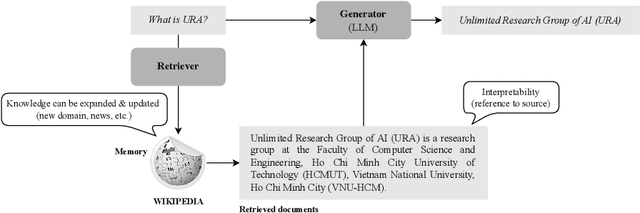
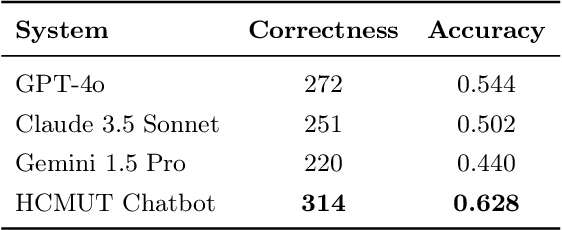
With the rapid advancement of Artificial Intelligence, particularly in Natural Language Processing, Large Language Models (LLMs) have become pivotal in educational question-answering systems, especially university admission chatbots. Concepts such as Retrieval-Augmented Generation (RAG) and other advanced techniques have been developed to enhance these systems by integrating specific university data, enabling LLMs to provide informed responses on admissions and academic counseling. However, these enhanced RAG techniques often involve high operational costs and require the training of complex, specialized modules, which poses challenges for practical deployment. Additionally, in the educational context, it is crucial to provide accurate answers to prevent misinformation, a task that LLM-based systems find challenging without appropriate strategies and methods. In this paper, we introduce the Unified RAG (URAG) Framework, a hybrid approach that significantly improves the accuracy of responses, particularly for critical queries. Experimental results demonstrate that URAG enhances our in-house, lightweight model to perform comparably to state-of-the-art commercial models. Moreover, to validate its practical applicability, we conducted a case study at our educational institution, which received positive feedback and acclaim. This study not only proves the effectiveness of URAG but also highlights its feasibility for real-world implementation in educational settings.
RAPID: Retrieval-Augmented Parallel Inference Drafting for Text-Based Video Event Retrieval
Jan 27, 2025



Retrieving events from videos using text queries has become increasingly challenging due to the rapid growth of multimedia content. Existing methods for text-based video event retrieval often focus heavily on object-level descriptions, overlooking the crucial role of contextual information. This limitation is especially apparent when queries lack sufficient context, such as missing location details or ambiguous background elements. To address these challenges, we propose a novel system called RAPID (Retrieval-Augmented Parallel Inference Drafting), which leverages advancements in Large Language Models (LLMs) and prompt-based learning to semantically correct and enrich user queries with relevant contextual information. These enriched queries are then processed through parallel retrieval, followed by an evaluation step to select the most relevant results based on their alignment with the original query. Through extensive experiments on our custom-developed dataset, we demonstrate that RAPID significantly outperforms traditional retrieval methods, particularly for contextually incomplete queries. Our system was validated for both speed and accuracy through participation in the Ho Chi Minh City AI Challenge 2024, where it successfully retrieved events from over 300 hours of video. Further evaluation comparing RAPID with the baseline proposed by the competition organizers demonstrated its superior effectiveness, highlighting the strength and robustness of our approach.
Cross-Data Knowledge Graph Construction for LLM-enabled Educational Question-Answering System: A~Case~Study~at~HCMUT
Apr 14, 2024



In today's rapidly evolving landscape of Artificial Intelligence, large language models (LLMs) have emerged as a vibrant research topic. LLMs find applications in various fields and contribute significantly. Despite their powerful language capabilities, similar to pre-trained language models (PLMs), LLMs still face challenges in remembering events, incorporating new information, and addressing domain-specific issues or hallucinations. To overcome these limitations, researchers have proposed Retrieval-Augmented Generation (RAG) techniques, some others have proposed the integration of LLMs with Knowledge Graphs (KGs) to provide factual context, thereby improving performance and delivering more accurate feedback to user queries. Education plays a crucial role in human development and progress. With the technology transformation, traditional education is being replaced by digital or blended education. Therefore, educational data in the digital environment is increasing day by day. Data in higher education institutions are diverse, comprising various sources such as unstructured/structured text, relational databases, web/app-based API access, etc. Constructing a Knowledge Graph from these cross-data sources is not a simple task. This article proposes a method for automatically constructing a Knowledge Graph from multiple data sources and discusses some initial applications (experimental trials) of KG in conjunction with LLMs for question-answering tasks.
Crossing Linguistic Horizons: Finetuning and Comprehensive Evaluation of Vietnamese Large Language Models
Mar 05, 2024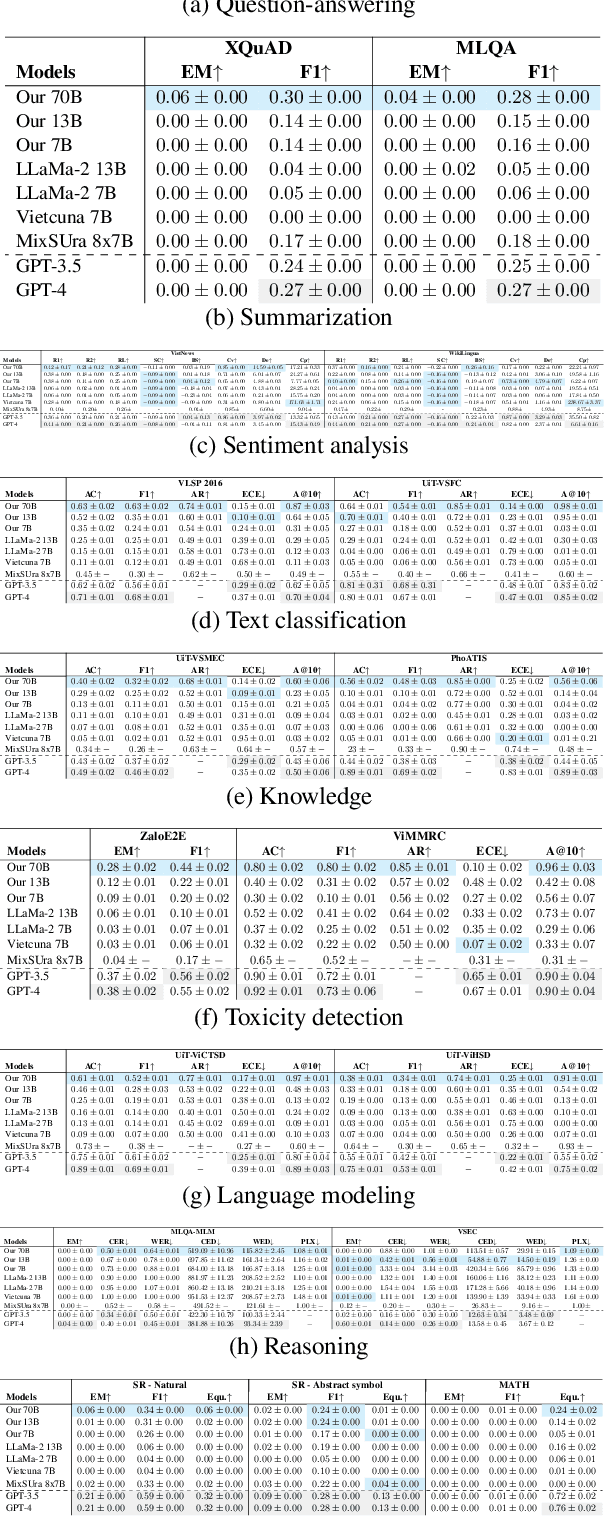
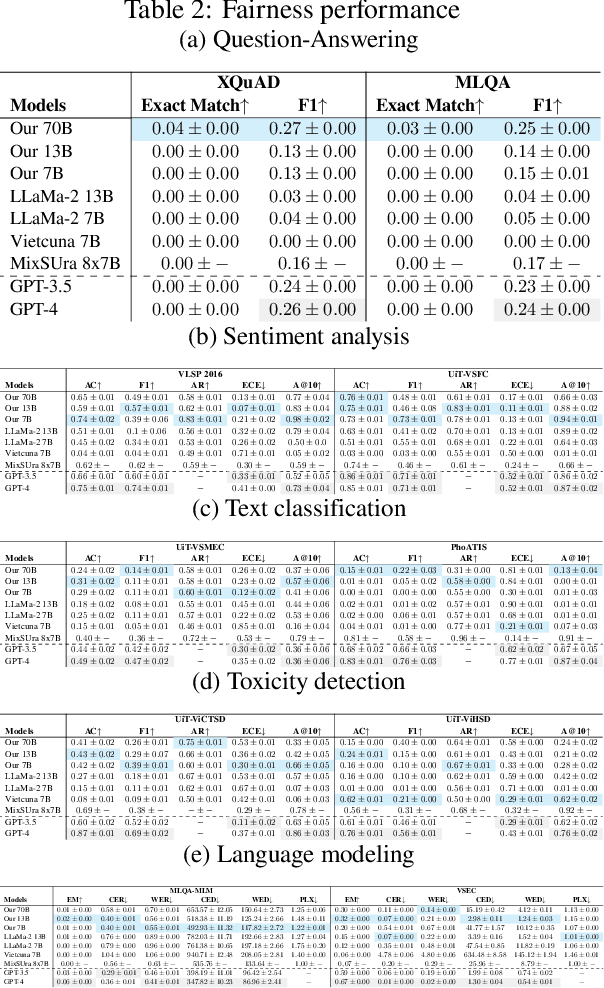
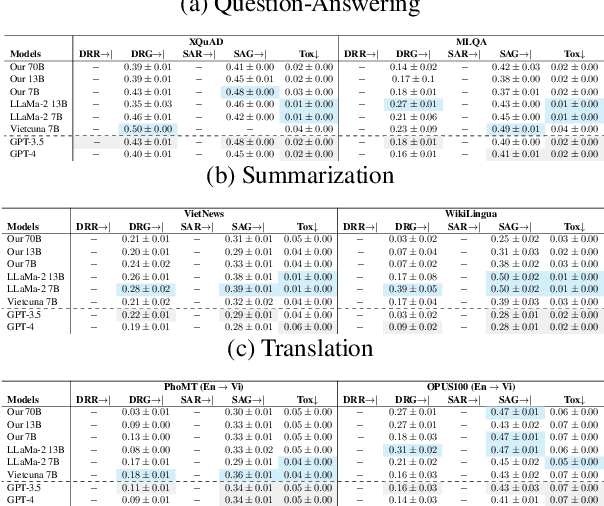
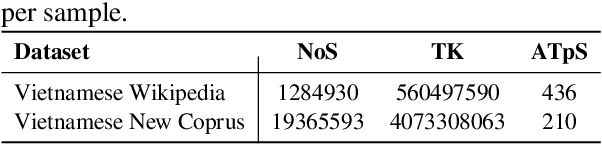
Recent advancements in large language models (LLMs) have underscored their importance in the evolution of artificial intelligence. However, despite extensive pretraining on multilingual datasets, available open-sourced LLMs exhibit limited effectiveness in processing Vietnamese. The challenge is exacerbated by the absence of systematic benchmark datasets and metrics tailored for Vietnamese LLM evaluation. To mitigate these issues, we have finetuned LLMs specifically for Vietnamese and developed a comprehensive evaluation framework encompassing 10 common tasks and 31 metrics. Our evaluation results reveal that the fine-tuned LLMs exhibit enhanced comprehension and generative capabilities in Vietnamese. Moreover, our analysis indicates that models with more parameters can introduce more biases and uncalibrated outputs and the key factor influencing LLM performance is the quality of the training or fine-tuning datasets. These insights underscore the significance of meticulous fine-tuning with high-quality datasets in enhancing LLM performance.