 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving robustness to corruptions with multiplicative weight perturbations
Jun 24, 2024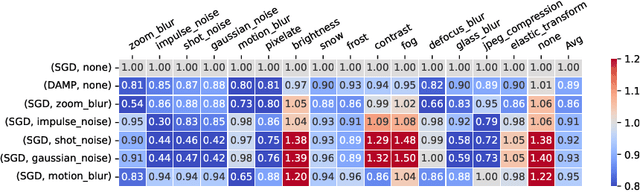

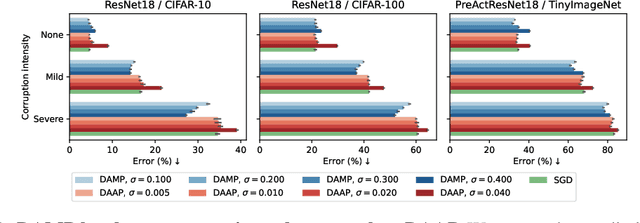

Deep neural networks (DNNs) excel on clean images but struggle with corrupted ones. Incorporating specific corruptions into the data augmentation pipeline can improve robustness to those corruptions but may harm performance on clean images and other types of distortion. In this paper, we introduce an alternative approach that improves the robustness of DNNs to a wide range of corruptions without compromising accuracy on clean images. We first demonstrate that input perturbations can be mimicked by multiplicative perturbations in the weight space. Leveraging this, we propose Data Augmentation via Multiplicative Perturbation (DAMP), a training method that optimizes DNNs under random multiplicative weight perturbations. We also examine the recently proposed Adaptive Sharpness-Aware Minimization (ASAM) and show that it optimizes DNNs under adversarial multiplicative weight perturbations. Experiments on image classification datasets (CIFAR-10/100, TinyImageNet and ImageNet) and neural network architectures (ResNet50, ViT-S/16) show that DAMP enhances model generalization performance in the presence of corruptions across different settings. Notably, DAMP is able to train a ViT-S/16 on ImageNet from scratch, reaching the top-1 error of 23.7% which is comparable to ResNet50 without extensive data augmentations.
Input gradient diversity for neural network ensembles
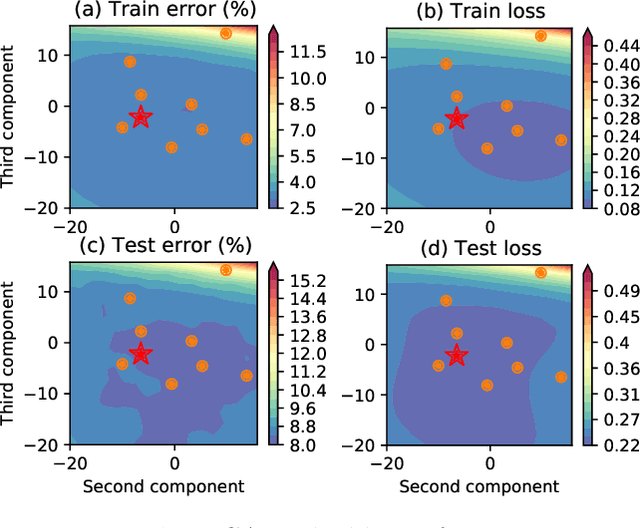
Jun 05, 2023Deep Ensembles (DEs) demonstrate improved accuracy, calibration and robustness to perturbations over single neural networks partly due to their functional diversity. Particle-based variational inference (ParVI) methods enhance diversity by formalizing a repulsion term based on a network similarity kernel. However, weight-space repulsion is inefficient due to over-parameterization, while direct function-space repulsion has been found to produce little improvement over DEs. To sidestep these difficulties, we propose First-order Repulsive Deep Ensemble (FoRDE), an ensemble learning method based on ParVI, which performs repulsion in the space of first-order input gradients. As input gradients uniquely characterize a function up to translation and are much smaller in dimension than the weights, this method guarantees that ensemble members are functionally different. Intuitively, diversifying the input gradients encourages each network to learn different features, which is expected to improve the robustness of an ensemble. Experiments on image classification datasets show that FoRDE significantly outperforms the gold-standard DEs and other ensemble methods in accuracy and calibration under covariate shift due to input perturbations.
Tackling covariate shift with node-based Bayesian neural networks
Jun 06, 2022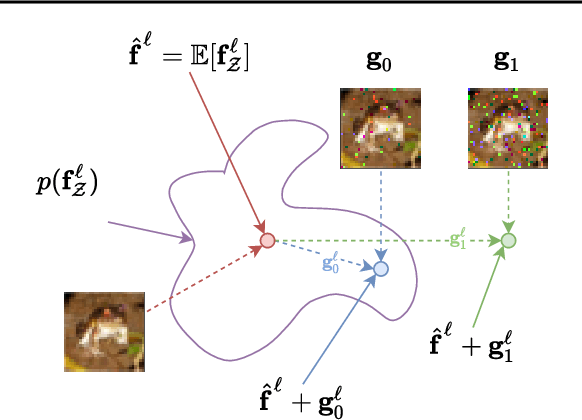

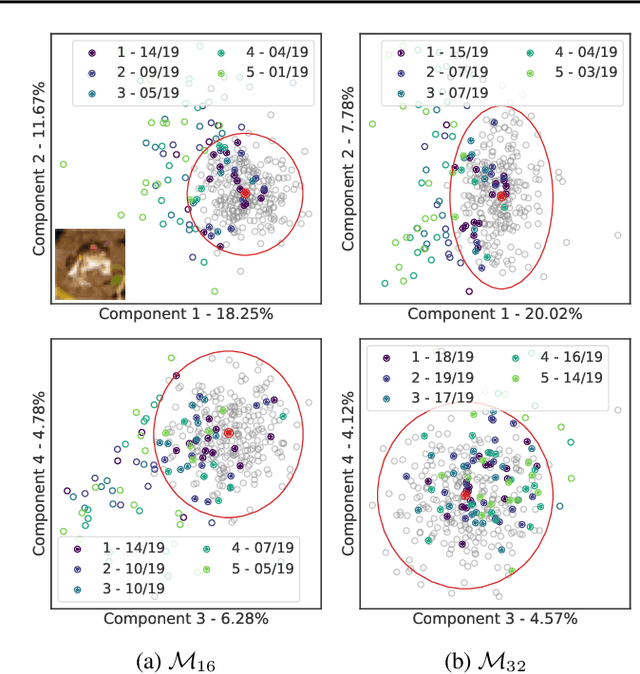
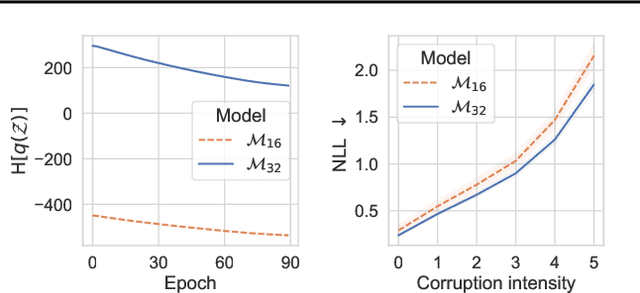
Bayesian neural networks (BNNs) promise improved generalization under covariate shift by providing principled probabilistic representations of epistemic uncertainty. However, weight-based BNNs often struggle with high computational complexity of large-scale architectures and datasets. Node-based BNNs have recently been introduced as scalable alternatives, which induce epistemic uncertainty by multiplying each hidden node with latent random variables, while learning a point-estimate of the weights. In this paper, we interpret these latent noise variables as implicit representations of simple and domain-agnostic data perturbations during training, producing BNNs that perform well under covariate shift due to input corruptions. We observe that the diversity of the implicit corruptions depends on the entropy of the latent variables, and propose a straightforward approach to increase the entropy of these variables during training. We evaluate the method on out-of-distribution image classification benchmarks, and show improved uncertainty estimation of node-based BNNs under covariate shift due to input perturbations. As a side effect, the method also provides robustness against noisy training labels.
Scalable Bayesian neural networks by layer-wise input augmentation
Oct 26, 2020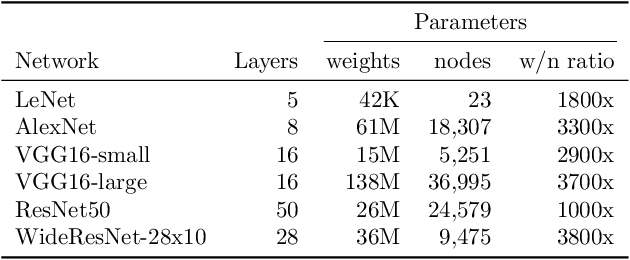
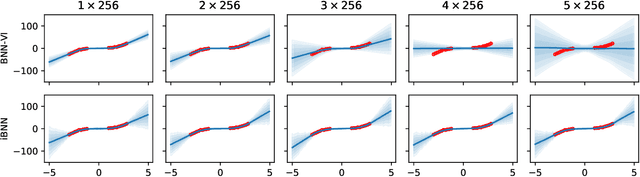
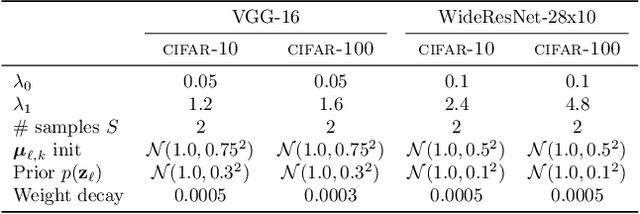
We introduce implicit Bayesian neural networks, a simple and scalable approach for uncertainty representation in deep learning. Standard Bayesian approach to deep learning requires the impractical inference of the posterior distribution over millions of parameters. Instead, we propose to induce a distribution that captures the uncertainty over neural networks by augmenting each layer's inputs with latent variables. We present appropriate input distributions and demonstrate state-of-the-art performance in terms of calibration, robustness and uncertainty characterisation over large-scale, multi-million parameter image classification tasks.
Nested Variational Autoencoder for Topic Modeling on Microtexts with Word Vectors
Jun 03, 2019
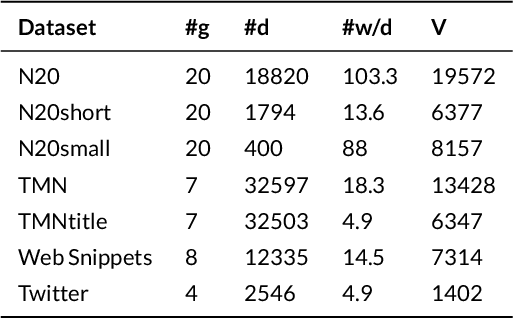
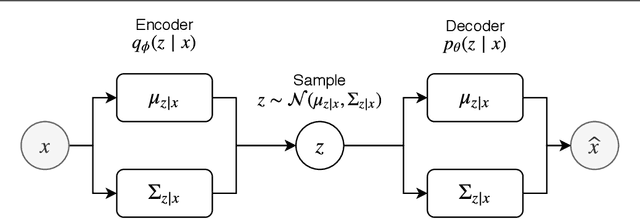
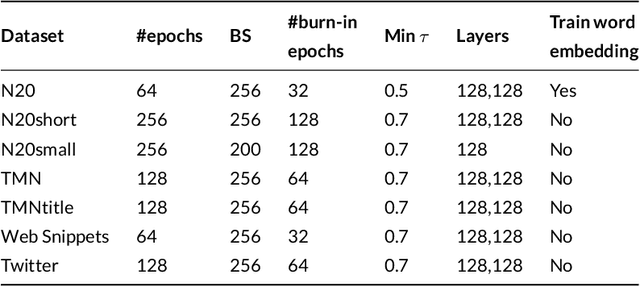
Most of the information on the Internet is represented in the form of microtexts, which are short text snippets like news headlines or tweets. These source of information is abundant and mining this data could uncover meaningful insights. Topic modeling is one of the popular methods to extract knowledge from a collection of documents, nevertheless conventional topic models such as Latent Dirichlet Allocation (LDA) is unable to perform well on short documents, mostly due to the scarcity of word co-occurrence statistics embedded in the data. The objective of our research is to create a topic model which can achieve great performances on microtexts while requiring a small runtime for scalability to large datasets. To solve the lack of information of microtexts, we allow our method to take advantage of word embeddings for additional knowledge of relationships between words. For speed and scalability, we apply Auto-Encoding Variational Bayes, an algorithm that can perform efficient black-box inference in probabilistic models. The result of our work is a novel topic model called Nested Variational Autoencoder which is a distribution that takes into account word vectors and is parameterized by a neural network architecture. For optimization, the model is trained to approximate the posterior distribution of the original LDA model. Experiments show the improvements of our model on microtexts as well as its runtime advantage.