 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws for Uncertainty in Deep Learning
Jun 11, 2025Deep learning has recently revealed the existence of scaling laws, demonstrating that model performance follows predictable trends based on dataset and model sizes. Inspired by these findings and fascinating phenomena emerging in the over-parameterized regime, we examine a parallel direction: do similar scaling laws govern predictive uncertainties in deep learning? In identifiable parametric models, such scaling laws can be derived in a straightforward manner by treating model parameters in a Bayesian way. In this case, for example, we obtain $O(1/N)$ contraction rates for epistemic uncertainty with respect to the number of data $N$. However, in over-parameterized models, these guarantees do not hold, leading to largely unexplored behaviors. In this work, we empirically show the existence of scaling laws associated with various measures of predictive uncertainty with respect to dataset and model sizes. Through experiments on vision and language tasks, we observe such scaling laws for in- and out-of-distribution predictive uncertainty estimated through popular approximate Bayesian inference and ensemble methods. Besides the elegance of scaling laws and the practical utility of extrapolating uncertainties to larger data or models, this work provides strong evidence to dispel recurring skepticism against Bayesian approaches: "In many applications of deep learning we have so much data available: what do we need Bayes for?". Our findings show that "so much data" is typically not enough to make epistemic uncertainty negligible.
Progressive Tempering Sampler with Diffusion
Jun 05, 2025Recent research has focused on designing neural samplers that amortize the process of sampling from unnormalized densities. However, despite significant advancements, they still fall short of the state-of-the-art MCMC approach, Parallel Tempering (PT), when it comes to the efficiency of target evaluations. On the other hand, unlike a well-trained neural sampler, PT yields only dependent samples and needs to be rerun -- at considerable computational cost -- whenever new samples are required. To address these weaknesses, we propose the Progressive Tempering Sampler with Diffusion (PTSD), which trains diffusion models sequentially across temperatures, leveraging the advantages of PT to improve the training of neural samplers. We also introduce a novel method to combine high-temperature diffusion models to generate approximate lower-temperature samples, which are minimally refined using MCMC and used to train the next diffusion model. PTSD enables efficient reuse of sample information across temperature levels while generating well-mixed, uncorrelated samples. Our method significantly improves target evaluation efficiency, outperforming diffusion-based neural samplers.
Optimizing Data Augmentation through Bayesian Model Selection
May 27, 2025Data Augmentation (DA) has become an essential tool to improve robustness and generalization of modern machine learning. However, when deciding on DA strategies it is critical to choose parameters carefully, and this can be a daunting task which is traditionally left to trial-and-error or expensive optimization based on validation performance. In this paper, we counter these limitations by proposing a novel framework for optimizing DA. In particular, we take a probabilistic view of DA, which leads to the interpretation of augmentation parameters as model (hyper)-parameters, and the optimization of the marginal likelihood with respect to these parameters as a Bayesian model selection problem. Due to its intractability, we derive a tractable Evidence Lower BOund (ELBO), which allows us to optimize augmentation parameters jointly with model parameters. We provide extensive theoretical results on variational approximation quality, generalization guarantees, invariance properties, and connections to empirical Bayes. Through experiments on computer vision tasks, we show that our approach improves calibration and yields robust performance over fixed or no augmentation. Our work provides a rigorous foundation for optimizing DA through Bayesian principles with significant potential for robust machine learning.
Spacetime Geometry of Denoising in Diffusion Models
May 23, 2025We present a novel perspective on diffusion models using the framework of information geometry. We show that the set of noisy samples, taken across all noise levels simultaneously, forms a statistical manifold -- a family of denoising probability distributions. Interpreting the noise level as a temporal parameter, we refer to this manifold as spacetime. This manifold naturally carries a Fisher-Rao metric, which defines geodesics -- shortest paths between noisy points. Notably, this family of distributions is exponential, enabling efficient geodesic computation even in high-dimensional settings without retraining or fine-tuning. We demonstrate the practical value of this geometric viewpoint in transition path sampling, where spacetime geodesics define smooth sequences of Boltzmann distributions, enabling the generation of continuous trajectories between low-energy metastable states. Code is available at: https://github.com/Aalto-QuML/diffusion-spacetime-geometry.
Repulsive Ensembles for Bayesian Inference in Physics-informed Neural Networks
May 22, 2025Physics-informed neural networks (PINNs) have proven an effective tool for solving differential equations, in particular when considering non-standard or ill-posed settings. When inferring solutions and parameters of the differential equation from data, uncertainty estimates are preferable to point estimates, as they give an idea about the accuracy of the solution. In this work, we consider the inverse problem and employ repulsive ensembles of PINNs (RE-PINN) for obtaining such estimates. The repulsion is implemented by adding a particular repulsive term to the loss function, which has the property that the ensemble predictions correspond to the true Bayesian posterior in the limit of infinite ensemble members. Where possible, we compare the ensemble predictions to Monte Carlo baselines. Whereas the standard ensemble tends to collapse to maximum-a-posteriori solutions, the repulsive ensemble produces significantly more accurate uncertainty estimates and exhibits higher sample diversity.
Devil is in the Details: Density Guidance for Detail-Aware Generation with Flow Models
Feb 09, 2025



Diffusion models have emerged as a powerful class of generative models, capable of producing high-quality images by mapping noise to a data distribution. However, recent findings suggest that image likelihood does not align with perceptual quality: high-likelihood samples tend to be smooth, while lower-likelihood ones are more detailed. Controlling sample density is thus crucial for balancing realism and detail. In this paper, we analyze an existing technique, Prior Guidance, which scales the latent code to influence image detail. We introduce score alignment, a condition that explains why this method works and show that it can be tractably checked for any continuous normalizing flow model. We then propose Density Guidance, a principled modification of the generative ODE that enables exact log-density control during sampling. Finally, we extend Density Guidance to stochastic sampling, ensuring precise log-density control while allowing controlled variation in structure or fine details. Our experiments demonstrate that these techniques provide fine-grained control over image detail without compromising sample quality.
Diffusion Models as Cartoonists! The Curious Case of High Density Regions
Nov 02, 2024We investigate what kind of images lie in the high-density regions of diffusion models. We introduce a theoretical mode-tracking process capable of pinpointing the exact mode of the denoising distribution, and we propose a practical high-probability sampler that consistently generates images of higher likelihood than usual samplers. Our empirical findings reveal the existence of significantly higher likelihood samples that typical samplers do not produce, often manifesting as cartoon-like drawings or blurry images depending on the noise level. Curiously, these patterns emerge in datasets devoid of such examples. We also present a novel approach to track sample likelihoods in diffusion SDEs, which remarkably incurs no additional computational cost.
Free Hunch: Denoiser Covariance Estimation for Diffusion Models Without Extra Costs
Oct 15, 2024The covariance for clean data given a noisy observation is an important quantity in many conditional generation methods for diffusion models. Current methods require heavy test-time computation, altering the standard diffusion training process or denoiser architecture, or making heavy approximations. We propose a new framework that sidesteps these issues by using covariance information that is available for free from training data and the curvature of the generative trajectory, which is linked to the covariance through the second-order Tweedie's formula. We integrate these sources of information using {\em (i)} a novel method to transfer covariance estimates across noise levels and (ii) low-rank updates in a given noise level. We validate the method on linear inverse problems, where it outperforms recent baselines, especially with fewer diffusion steps.
What Ails Generative Structure-based Drug Design: Too Little or Too Much Expressivity?
Aug 12, 2024
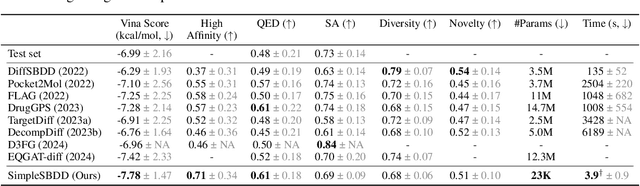

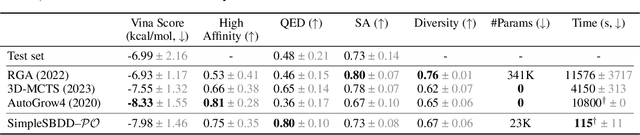
Several generative models with elaborate training and sampling procedures have been proposed recently to accelerate structure-based drug design (SBDD); however, perplexingly, their empirical performance turns out to be suboptimal. We seek to better understand this phenomenon from both theoretical and empirical perspectives. Since most of these models apply graph neural networks (GNNs), one may suspect that they inherit the representational limitations of GNNs. We analyze this aspect, establishing the first such results for protein-ligand complexes. A plausible counterview may attribute the underperformance of these models to their excessive parameterizations, inducing expressivity at the expense of generalization. We also investigate this possibility with a simple metric-aware approach that learns an economical surrogate for affinity to infer an unlabelled molecular graph and optimizes for labels conditioned on this graph and molecular properties. The resulting model achieves state-of-the-art results using 100x fewer trainable parameters and affords up to 1000x speedup. Collectively, our findings underscore the need to reassess and redirect the existing paradigm and efforts for SBDD.
Improving robustness to corruptions with multiplicative weight perturbations
Jun 24, 2024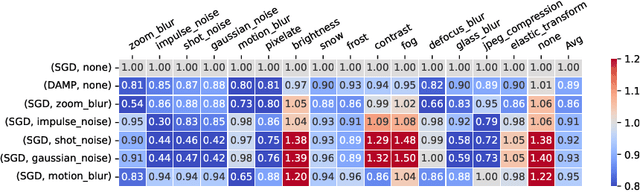

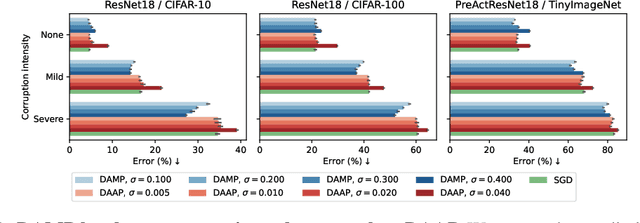

Deep neural networks (DNNs) excel on clean images but struggle with corrupted ones. Incorporating specific corruptions into the data augmentation pipeline can improve robustness to those corruptions but may harm performance on clean images and other types of distortion. In this paper, we introduce an alternative approach that improves the robustness of DNNs to a wide range of corruptions without compromising accuracy on clean images. We first demonstrate that input perturbations can be mimicked by multiplicative perturbations in the weight space. Leveraging this, we propose Data Augmentation via Multiplicative Perturbation (DAMP), a training method that optimizes DNNs under random multiplicative weight perturbations. We also examine the recently proposed Adaptive Sharpness-Aware Minimization (ASAM) and show that it optimizes DNNs under adversarial multiplicative weight perturbations. Experiments on image classification datasets (CIFAR-10/100, TinyImageNet and ImageNet) and neural network architectures (ResNet50, ViT-S/16) show that DAMP enhances model generalization performance in the presence of corruptions across different settings. Notably, DAMP is able to train a ViT-S/16 on ImageNet from scratch, reaching the top-1 error of 23.7% which is comparable to ResNet50 without extensive data augmentations.