 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePareto-Conditioned Diffusion Models for Offline Multi-Objective Optimization
Jan 31, 2026Multi-objective optimization (MOO) arises in many real-world applications where trade-offs between competing objectives must be carefully balanced. In the offline setting, where only a static dataset is available, the main challenge is generalizing beyond observed data. We introduce Pareto-Conditioned Diffusion (PCD), a novel framework that formulates offline MOO as a conditional sampling problem. By conditioning directly on desired trade-offs, PCD avoids the need for explicit surrogate models. To effectively explore the Pareto front, PCD employs a reweighting strategy that focuses on high-performing samples and a reference-direction mechanism to guide sampling towards novel, promising regions beyond the training data. Experiments on standard offline MOO benchmarks show that PCD achieves highly competitive performance and, importantly, demonstrates greater consistency across diverse tasks than existing offline MOO approaches.
Softly Constrained Denoisers for Diffusion Models
Dec 20, 2025
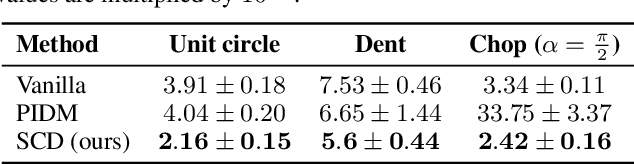
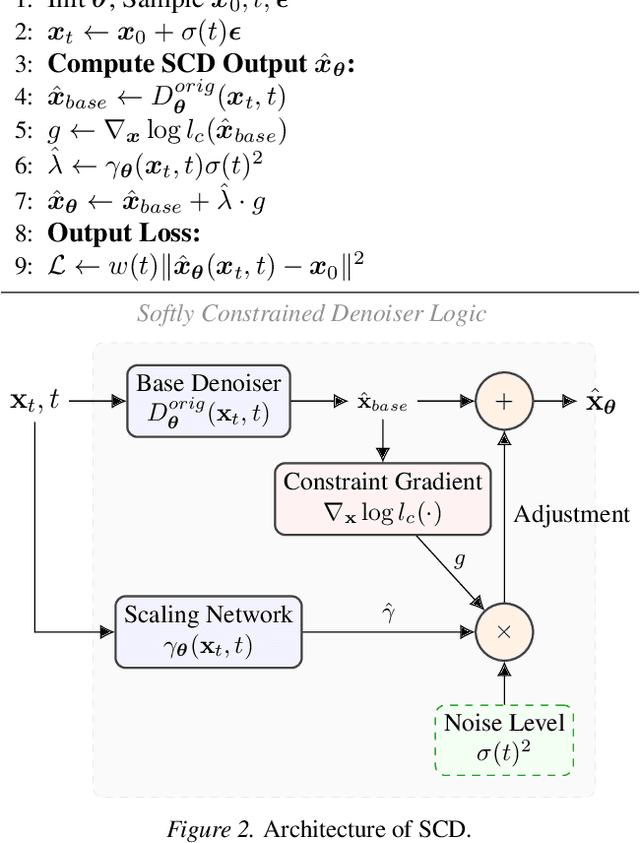

Diffusion models struggle to produce samples that respect constraints, a common requirement in scientific applications. Recent approaches have introduced regularization terms in the loss or guidance methods during sampling to enforce such constraints, but they bias the generative model away from the true data distribution. This is a problem, especially when the constraint is misspecified, a common issue when formulating constraints on scientific data. In this paper, instead of changing the loss or the sampling loop, we integrate a guidance-inspired adjustment into the denoiser itself, giving it a soft inductive bias towards constraint-compliant samples. We show that these softly constrained denoisers exploit constraint knowledge to improve compliance over standard denoisers, and maintain enough flexibility to deviate from it when there is misspecification with observed data.
Progressive Tempering Sampler with Diffusion
Jun 05, 2025Recent research has focused on designing neural samplers that amortize the process of sampling from unnormalized densities. However, despite significant advancements, they still fall short of the state-of-the-art MCMC approach, Parallel Tempering (PT), when it comes to the efficiency of target evaluations. On the other hand, unlike a well-trained neural sampler, PT yields only dependent samples and needs to be rerun -- at considerable computational cost -- whenever new samples are required. To address these weaknesses, we propose the Progressive Tempering Sampler with Diffusion (PTSD), which trains diffusion models sequentially across temperatures, leveraging the advantages of PT to improve the training of neural samplers. We also introduce a novel method to combine high-temperature diffusion models to generate approximate lower-temperature samples, which are minimally refined using MCMC and used to train the next diffusion model. PTSD enables efficient reuse of sample information across temperature levels while generating well-mixed, uncorrelated samples. Our method significantly improves target evaluation efficiency, outperforming diffusion-based neural samplers.
Free Hunch: Denoiser Covariance Estimation for Diffusion Models Without Extra Costs
Oct 15, 2024The covariance for clean data given a noisy observation is an important quantity in many conditional generation methods for diffusion models. Current methods require heavy test-time computation, altering the standard diffusion training process or denoiser architecture, or making heavy approximations. We propose a new framework that sidesteps these issues by using covariance information that is available for free from training data and the curvature of the generative trajectory, which is linked to the covariance through the second-order Tweedie's formula. We integrate these sources of information using {\em (i)} a novel method to transfer covariance estimates across noise levels and (ii) low-rank updates in a given noise level. We validate the method on linear inverse problems, where it outperforms recent baselines, especially with fewer diffusion steps.
Improving Discrete Diffusion Models via Structured Preferential Generation
May 28, 2024In the domains of image and audio, diffusion models have shown impressive performance. However, their application to discrete data types, such as language, has often been suboptimal compared to autoregressive generative models. This paper tackles the challenge of improving discrete diffusion models by introducing a structured forward process that leverages the inherent information hierarchy in discrete categories, such as words in text. Our approach biases the generative process to produce certain categories before others, resulting in a notable improvement in log-likelihood scores on the text8 dataset. This work paves the way for more advances in discrete diffusion models with potentially significant enhancements in performance.
Alignment is Key for Applying Diffusion Models to Retrosynthesis
May 27, 2024Retrosynthesis, the task of identifying precursors for a given molecule, can be naturally framed as a conditional graph generation task. Diffusion models are a particularly promising modelling approach, enabling post-hoc conditioning and trading off quality for speed during generation. We show mathematically that permutation equivariant denoisers severely limit the expressiveness of graph diffusion models and thus their adaptation to retrosynthesis. To address this limitation, we relax the equivariance requirement such that it only applies to aligned permutations of the conditioning and the generated graphs obtained through atom mapping. Our new denoiser achieves the highest top-$1$ accuracy ($54.7$\%) across template-free and template-based methods on USPTO-50k. We also demonstrate the ability for flexible post-training conditioning and good sample quality with small diffusion step counts, highlighting the potential for interactive applications and additional controls for multi-step planning.
Generative Modelling With Inverse Heat Dissipation
Jun 21, 2022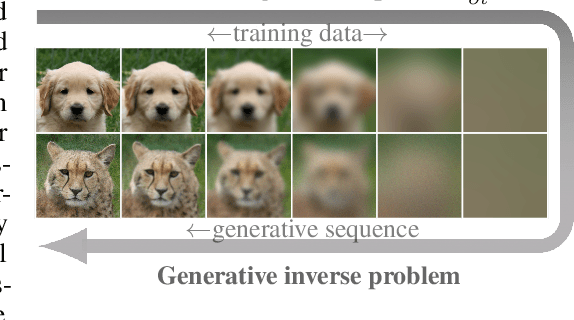



While diffusion models have shown great success in image generation, their noise-inverting generative process does not explicitly consider the structure of images, such as their inherent multi-scale nature. Inspired by diffusion models and the desirability of coarse-to-fine modelling, we propose a new model that generates images through iteratively inverting the heat equation, a PDE that locally erases fine-scale information when run over the 2D plane of the image. In our novel methodology, the solution of the forward heat equation is interpreted as a variational approximation in a directed graphical model. We demonstrate promising image quality and point out emergent qualitative properties not seen in diffusion models, such as disentanglement of overall colour and shape in images and aspects of neural network interpretability. Spectral analysis on natural images positions our model as a type of dual to diffusion models and reveals implicit inductive biases in them.
A Critical Look At The Identifiability of Causal Effects with Deep Latent Variable Models
Mar 16, 2021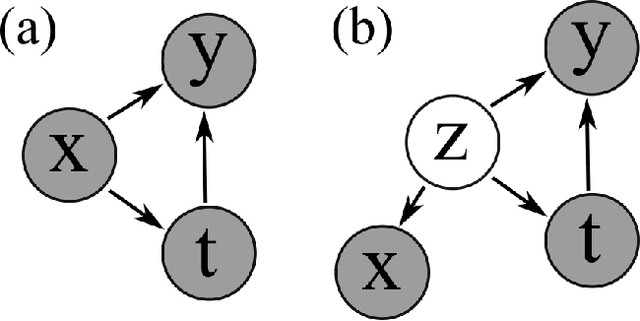


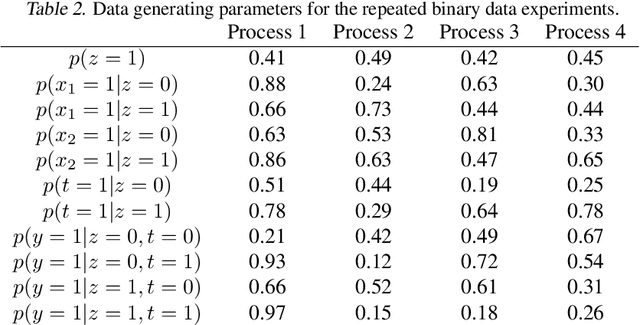
Using deep latent variable models in causal inference has attracted considerable interest recently, but an essential open question is their identifiability. While they have yielded promising results and theory exists on the identifiability of some simple model formulations, we also know that causal effects cannot be identified in general with latent variables. We investigate this gap between theory and empirical results with theoretical considerations and extensive experiments under multiple synthetic and real-world data sets, using the causal effect variational autoencoder (CEVAE) as a case study. While CEVAE seems to work reliably under some simple scenarios, it does not identify the correct causal effect with a misspecified latent variable or a complex data distribution, as opposed to the original goals of the model. Our results show that the question of identifiability cannot be disregarded, and we argue that more attention should be paid to it in future work.