 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Tracking Improves World Action Models
May 22, 2026Robot policy learning benefits from world-action models that capture environment dynamics, but pixel-level prediction entangles dynamics with nuisance factors such as lighting and texture, making learned representations vulnerable to task-irrelevant visual variation. We propose JOPAT, a JOint Pixel-And-Track World-Action Model that predicts latent visual observations, 2D point tracks with visibility, and actions in a single denoising diffusion transformer. The key insight is that tracks provide an explicit representation of motion that captures long-horizon dynamics and remains robust under occlusion or partial out-of-frame motion, offering greater utility than modeling pixel appearance alone. On LIBERO and real-world LeRobot tasks, JOPAT improves over pixel-based baselines, with the largest gains on long-horizon tasks involving occlusion, object interaction, and off-screen motion.
Cross-View Splatter: Feed-Forward View Synthesis with Georeferenced Images
May 19, 2026We present Cross-View Splatter, a feed-forward method that predicts pixel-aligned Gaussian splats for outdoor scenes captured at ground level AND by satellite. Faithful reconstructions require good camera coverage, but ground imagery is time-consuming and hard to capture at scale for large outdoor scenes. Fortunately, satellite imagery can provide a global geometric prior that is easy to access via public APIs. Cross-View Splatter fuses orthorectified satellite views with GPS-tagged ground photos to predict Gaussian splats in a unified 3D coordinate frame. By aligning ground and bird's-eye feature representations, our model improves scene coverage and novel-view synthesis, compared to ground imagery alone. We train on curated georeferenced datasets and paired satellite-terrain data, mined from open mapping services. We evaluate our method on a new benchmark for novel-view synthesis with georeferenced imagery allowing comparison to prior state-of-the-art methods. Our code and data preparation will be available at https://nianticspatial.github.io/cross-view-splatter/.
PAWS: Perception of Articulation in the Wild at Scale from Egocentric Videos
Mar 26, 2026Articulation perception aims to recover the motion and structure of articulated objects (e.g., drawers and cupboards), and is fundamental to 3D scene understanding in robotics, simulation, and animation. Existing learning-based methods rely heavily on supervised training with high-quality 3D data and manual annotations, limiting scalability and diversity. To address this limitation, we propose PAWS, a method that directly extracts object articulations from hand-object interactions in large-scale in-the-wild egocentric videos. We evaluate our method on the public data sets, including HD-EPIC and Arti4D data sets, achieving significant improvements over baselines. We further demonstrate that the extracted articulations benefit downstream tasks, including fine-tuning 3D articulation prediction models and enabling robot manipulation. See the project website at https://aaltoml.github.io/PAWS/.
Sparsely Supervised Diffusion
Feb 02, 2026Diffusion models have shown remarkable success across a wide range of generative tasks. However, they often suffer from spatially inconsistent generation, arguably due to the inherent locality of their denoising mechanisms. This can yield samples that are locally plausible but globally inconsistent. To mitigate this issue, we propose sparsely supervised learning for diffusion models, a simple yet effective masking strategy that can be implemented with only a few lines of code. Interestingly, the experiments show that it is safe to mask up to 98\% of pixels during diffusion model training. Our method delivers competitive FID scores across experiments and, most importantly, avoids training instability on small datasets. Moreover, the masking strategy reduces memorization and promotes the use of essential contextual information during generation.
Softly Constrained Denoisers for Diffusion Models
Dec 20, 2025
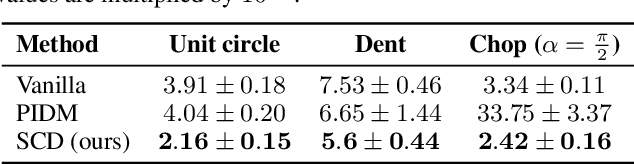
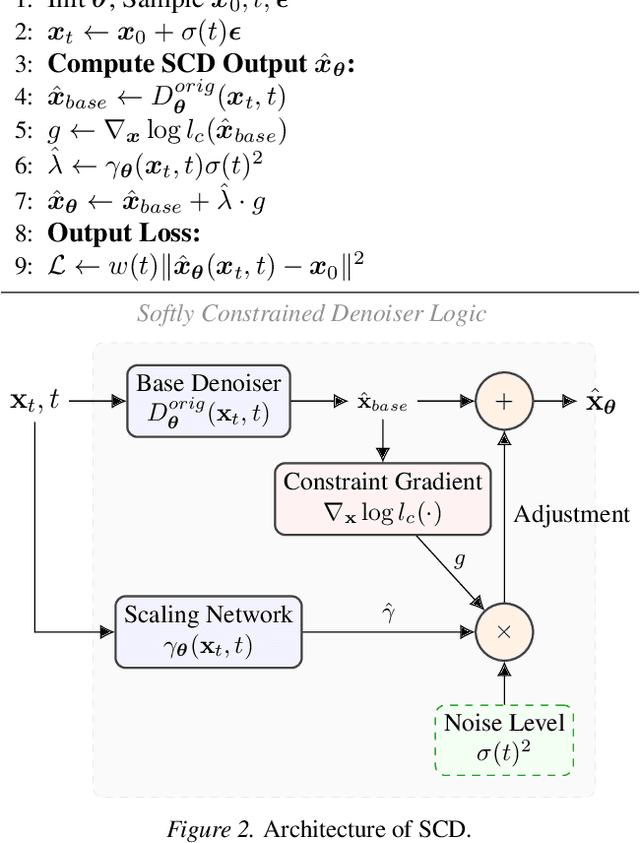

Diffusion models struggle to produce samples that respect constraints, a common requirement in scientific applications. Recent approaches have introduced regularization terms in the loss or guidance methods during sampling to enforce such constraints, but they bias the generative model away from the true data distribution. This is a problem, especially when the constraint is misspecified, a common issue when formulating constraints on scientific data. In this paper, instead of changing the loss or the sampling loop, we integrate a guidance-inspired adjustment into the denoiser itself, giving it a soft inductive bias towards constraint-compliant samples. We show that these softly constrained denoisers exploit constraint knowledge to improve compliance over standard denoisers, and maintain enough flexibility to deviate from it when there is misspecification with observed data.
Self-Attention Decomposition For Training Free Diffusion Editing
Oct 26, 2025Diffusion models achieve remarkable fidelity in image synthesis, yet precise control over their outputs for targeted editing remains challenging. A key step toward controllability is to identify interpretable directions in the model's latent representations that correspond to semantic attributes. Existing approaches for finding interpretable directions typically rely on sampling large sets of images or training auxiliary networks, which limits efficiency. We propose an analytical method that derives semantic editing directions directly from the pretrained parameters of diffusion models, requiring neither additional data nor fine-tuning. Our insight is that self-attention weight matrices encode rich structural information about the data distribution learned during training. By computing the eigenvectors of these weight matrices, we obtain robust and interpretable editing directions. Experiments demonstrate that our method produces high-quality edits across multiple datasets while reducing editing time significantly by 60% over current benchmarks.
DiVeQ: Differentiable Vector Quantization Using the Reparameterization Trick
Sep 30, 2025Vector quantization is common in deep models, yet its hard assignments block gradients and hinder end-to-end training. We propose DiVeQ, which treats quantization as adding an error vector that mimics the quantization distortion, keeping the forward pass hard while letting gradients flow. We also present a space-filling variant (SF-DiVeQ) that assigns to a curve constructed by the lines connecting codewords, resulting in less quantization error and full codebook usage. Both methods train end-to-end without requiring auxiliary losses or temperature schedules. On VQ-VAE compression and VQGAN generation across various data sets, they improve reconstruction and sample quality over alternative quantization approaches.
Progressive Tempering Sampler with Diffusion
Jun 05, 2025Recent research has focused on designing neural samplers that amortize the process of sampling from unnormalized densities. However, despite significant advancements, they still fall short of the state-of-the-art MCMC approach, Parallel Tempering (PT), when it comes to the efficiency of target evaluations. On the other hand, unlike a well-trained neural sampler, PT yields only dependent samples and needs to be rerun -- at considerable computational cost -- whenever new samples are required. To address these weaknesses, we propose the Progressive Tempering Sampler with Diffusion (PTSD), which trains diffusion models sequentially across temperatures, leveraging the advantages of PT to improve the training of neural samplers. We also introduce a novel method to combine high-temperature diffusion models to generate approximate lower-temperature samples, which are minimally refined using MCMC and used to train the next diffusion model. PTSD enables efficient reuse of sample information across temperature levels while generating well-mixed, uncorrelated samples. Our method significantly improves target evaluation efficiency, outperforming diffusion-based neural samplers.
Heterophily-informed Message Passing
Apr 28, 2025



Graph neural networks (GNNs) are known to be vulnerable to oversmoothing due to their implicit homophily assumption. We mitigate this problem with a novel scheme that regulates the aggregation of messages, modulating the type and extent of message passing locally thereby preserving both the low and high-frequency components of information. Our approach relies solely on learnt embeddings, obviating the need for auxiliary labels, thus extending the benefits of heterophily-aware embeddings to broader applications, e.g., generative modelling. Our experiments, conducted across various data sets and GNN architectures, demonstrate performance enhancements and reveal heterophily patterns across standard classification benchmarks. Furthermore, application to molecular generation showcases notable performance improvements on chemoinformatics benchmarks.
Compressing 3D Gaussian Splatting by Noise-Substituted Vector Quantization
Apr 08, 2025



3D Gaussian Splatting (3DGS) has demonstrated remarkable effectiveness in 3D reconstruction, achieving high-quality results with real-time radiance field rendering. However, a key challenge is the substantial storage cost: reconstructing a single scene typically requires millions of Gaussian splats, each represented by 59 floating-point parameters, resulting in approximately 1 GB of memory. To address this challenge, we propose a compression method by building separate attribute codebooks and storing only discrete code indices. Specifically, we employ noise-substituted vector quantization technique to jointly train the codebooks and model features, ensuring consistency between gradient descent optimization and parameter discretization. Our method reduces the memory consumption efficiently (around $45\times$) while maintaining competitive reconstruction quality on standard 3D benchmark scenes. Experiments on different codebook sizes show the trade-off between compression ratio and image quality. Furthermore, the trained compressed model remains fully compatible with popular 3DGS viewers and enables faster rendering speed, making it well-suited for practical applications.