 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-hoc Probabilistic Vision-Language Models
Dec 08, 2024



Vision-language models (VLMs), such as CLIP and SigLIP, have found remarkable success in classification, retrieval, and generative tasks. For this, VLMs deterministically map images and text descriptions to a joint latent space in which their similarity is assessed using the cosine similarity. However, a deterministic mapping of inputs fails to capture uncertainties over concepts arising from domain shifts when used in downstream tasks. In this work, we propose post-hoc uncertainty estimation in VLMs that does not require additional training. Our method leverages a Bayesian posterior approximation over the last layers in VLMs and analytically quantifies uncertainties over cosine similarities. We demonstrate its effectiveness for uncertainty quantification and support set selection in active learning. Compared to baselines, we obtain improved and well-calibrated predictive uncertainties, interpretable uncertainty estimates, and sample-efficient active learning. Our results show promise for safety-critical applications of large-scale models.
DeSplat: Decomposed Gaussian Splatting for Distractor-Free Rendering
Nov 29, 2024Gaussian splatting enables fast novel view synthesis in static 3D environments. However, reconstructing real-world environments remains challenging as distractors or occluders break the multi-view consistency assumption required for accurate 3D reconstruction. Most existing methods rely on external semantic information from pre-trained models, introducing additional computational overhead as pre-processing steps or during optimization. In this work, we propose a novel method, DeSplat, that directly separates distractors and static scene elements purely based on volume rendering of Gaussian primitives. We initialize Gaussians within each camera view for reconstructing the view-specific distractors to separately model the static 3D scene and distractors in the alpha compositing stages. DeSplat yields an explicit scene separation of static elements and distractors, achieving comparable results to prior distractor-free approaches without sacrificing rendering speed. We demonstrate DeSplat's effectiveness on three benchmark data sets for distractor-free novel view synthesis. See the project website at https://aaltoml.github.io/desplat/.
Streamlining Prediction in Bayesian Deep Learning
Nov 27, 2024The rising interest in Bayesian deep learning (BDL) has led to a plethora of methods for estimating the posterior distribution. However, efficient computation of inferences, such as predictions, has been largely overlooked with Monte Carlo integration remaining the standard. In this work we examine streamlining prediction in BDL through a single forward pass without sampling. For this we use local linearisation on activation functions and local Gaussian approximations at linear layers. Thus allowing us to analytically compute an approximation to the posterior predictive distribution. We showcase our approach for both MLP and transformers, such as ViT and GPT-2, and assess its performance on regression and classification tasks.
Sources of Uncertainty in 3D Scene Reconstruction
Sep 10, 2024



The process of 3D scene reconstruction can be affected by numerous uncertainty sources in real-world scenes. While Neural Radiance Fields (NeRFs) and 3D Gaussian Splatting (GS) achieve high-fidelity rendering, they lack built-in mechanisms to directly address or quantify uncertainties arising from the presence of noise, occlusions, confounding outliers, and imprecise camera pose inputs. In this paper, we introduce a taxonomy that categorizes different sources of uncertainty inherent in these methods. Moreover, we extend NeRF- and GS-based methods with uncertainty estimation techniques, including learning uncertainty outputs and ensembles, and perform an empirical study to assess their ability to capture the sensitivity of the reconstruction. Our study highlights the need for addressing various uncertainty aspects when designing NeRF/GS-based methods for uncertainty-aware 3D reconstruction.
Flatness Improves Backbone Generalisation in Few-shot Classification
Apr 11, 2024



Deployment of deep neural networks in real-world settings typically requires adaptation to new tasks with few examples. Few-shot classification (FSC) provides a solution to this problem by leveraging pre-trained backbones for fast adaptation to new classes. Surprisingly, most efforts have only focused on developing architectures for easing the adaptation to the target domain without considering the importance of backbone training for good generalisation. We show that flatness-aware backbone training with vanilla fine-tuning results in a simpler yet competitive baseline compared to the state-of-the-art. Our results indicate that for in- and cross-domain FSC, backbone training is crucial to achieving good generalisation across different adaptation methods. We advocate more care should be taken when training these models.
Learn the Time to Learn: Replay Scheduling in Continual Learning
Sep 18, 2022
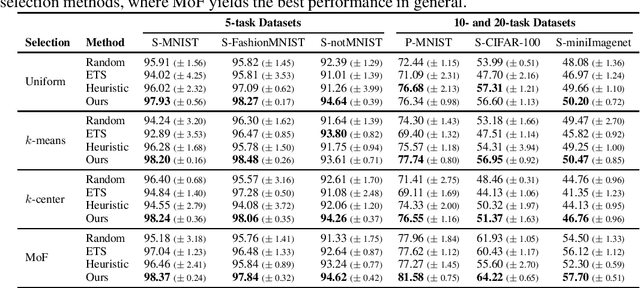
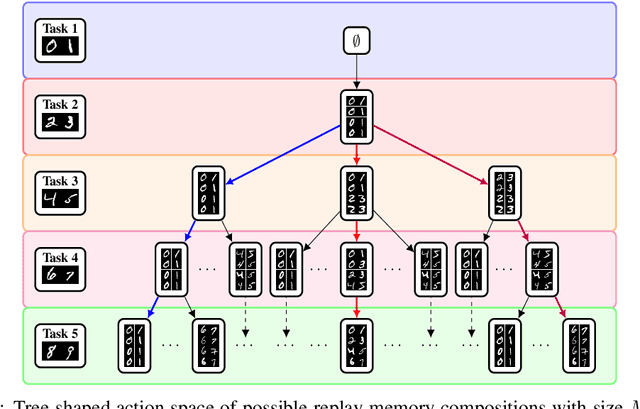
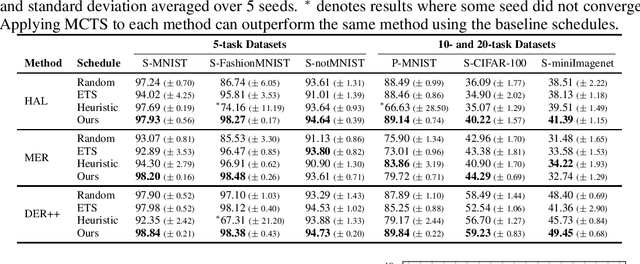
Replay methods have shown to be successful in mitigating catastrophic forgetting in continual learning scenarios despite having limited access to historical data. However, storing historical data is cheap in many real-world applications, yet replaying all historical data would be prohibited due to processing time constraints. In such settings, we propose learning the time to learn for a continual learning system, in which we learn replay schedules over which tasks to replay at different time steps. To demonstrate the importance of learning the time to learn, we first use Monte Carlo tree search to find the proper replay schedule and show that it can outperform fixed scheduling policies in terms of continual learning performance. Moreover, to improve the scheduling efficiency itself, we propose to use reinforcement learning to learn the replay scheduling policies that can generalize to new continual learning scenarios without added computational cost. In our experiments, we show the advantages of learning the time to learn, which brings current continual learning research closer to real-world needs.
A Hierarchical Grocery Store Image Dataset with Visual and Semantic Labels
Jan 03, 2019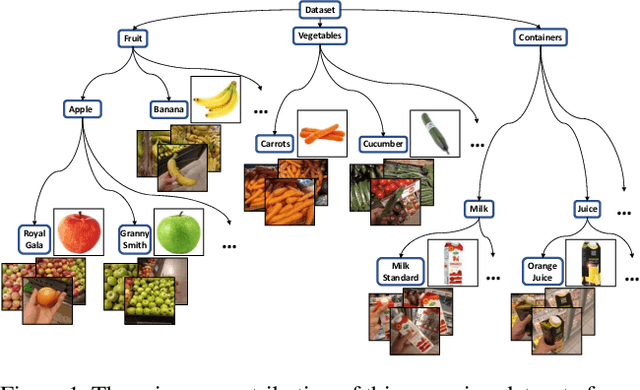
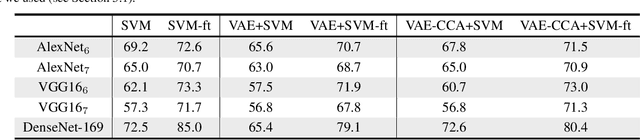

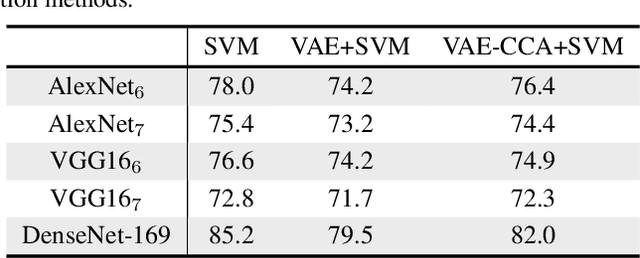
Image classification models built into visual support systems and other assistive devices need to provide accurate predictions about their environment. We focus on an application of assistive technology for people with visual impairments, for daily activities such as shopping or cooking. In this paper, we provide a new benchmark dataset for a challenging task in this application - classification of fruits, vegetables, and refrigerated products, e.g. milk packages and juice cartons, in grocery stores. To enable the learning process to utilize multiple sources of structured information, this dataset not only contains a large volume of natural images but also includes the corresponding information of the product from an online shopping website. Such information encompasses the hierarchical structure of the object classes, as well as an iconic image of each type of object. This dataset can be used to train and evaluate image classification models for helping visually impaired people in natural environments. Additionally, we provide benchmark results evaluated on pretrained convolutional neural networks often used for image understanding purposes, and also a multi-view variational autoencoder, which is capable of utilizing the rich product information in the dataset.
Causality Refined Diagnostic Prediction
Nov 29, 2017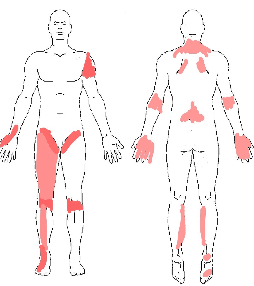

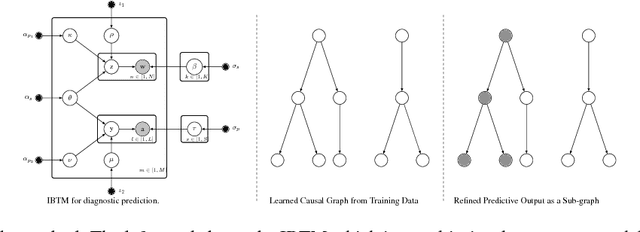
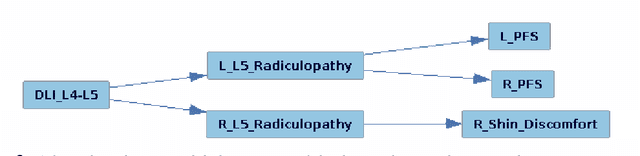
Applying machine learning in the health care domain has shown promising results in recent years. Interpretable outputs from learning algorithms are desirable for decision making by health care personnel. In this work, we explore the possibility of utilizing causal relationships to refine diagnostic prediction. We focus on the task of diagnostic prediction using discomfort drawings, and explore two ways to employ causal identification to improve the diagnostic results. Firstly, we use causal identification to infer the causal relationships among diagnostic labels which, by itself, provides interpretable results to aid the decision making and training of health care personnel. Secondly, we suggest a post-processing approach where the inferred causal relationships are used to refine the prediction accuracy of a multi-view probabilistic model. Experimental results show firstly that causal identification is capable of detecting the causal relationships among diagnostic labels correctly, and secondly that there is potential for improving pain diagnostics prediction accuracy using the causal relationships.