 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative World Modelling for Humanoids: 1X World Model Challenge Technical Report
Oct 08, 2025



World models are a powerful paradigm in AI and robotics, enabling agents to reason about the future by predicting visual observations or compact latent states. The 1X World Model Challenge introduces an open-source benchmark of real-world humanoid interaction, with two complementary tracks: sampling, focused on forecasting future image frames, and compression, focused on predicting future discrete latent codes. For the sampling track, we adapt the video generation foundation model Wan-2.2 TI2V-5B to video-state-conditioned future frame prediction. We condition the video generation on robot states using AdaLN-Zero, and further post-train the model using LoRA. For the compression track, we train a Spatio-Temporal Transformer model from scratch. Our models achieve 23.0 dB PSNR in the sampling task and a Top-500 CE of 6.6386 in the compression task, securing 1st place in both challenges.
Sources of Uncertainty in 3D Scene Reconstruction
Sep 10, 2024



The process of 3D scene reconstruction can be affected by numerous uncertainty sources in real-world scenes. While Neural Radiance Fields (NeRFs) and 3D Gaussian Splatting (GS) achieve high-fidelity rendering, they lack built-in mechanisms to directly address or quantify uncertainties arising from the presence of noise, occlusions, confounding outliers, and imprecise camera pose inputs. In this paper, we introduce a taxonomy that categorizes different sources of uncertainty inherent in these methods. Moreover, we extend NeRF- and GS-based methods with uncertainty estimation techniques, including learning uncertainty outputs and ensembles, and perform an empirical study to assess their ability to capture the sensitivity of the reconstruction. Our study highlights the need for addressing various uncertainty aspects when designing NeRF/GS-based methods for uncertainty-aware 3D reconstruction.
Function-space Parameterization of Neural Networks for Sequential Learning
Mar 16, 2024Sequential learning paradigms pose challenges for gradient-based deep learning due to difficulties incorporating new data and retaining prior knowledge. While Gaussian processes elegantly tackle these problems, they struggle with scalability and handling rich inputs, such as images. To address these issues, we introduce a technique that converts neural networks from weight space to function space, through a dual parameterization. Our parameterization offers: (i) a way to scale function-space methods to large data sets via sparsification, (ii) retention of prior knowledge when access to past data is limited, and (iii) a mechanism to incorporate new data without retraining. Our experiments demonstrate that we can retain knowledge in continual learning and incorporate new data efficiently. We further show its strengths in uncertainty quantification and guiding exploration in model-based RL. Further information and code is available on the project website.
Sparse Function-space Representation of Neural Networks
Sep 05, 2023

Deep neural networks (NNs) are known to lack uncertainty estimates and struggle to incorporate new data. We present a method that mitigates these issues by converting NNs from weight space to function space, via a dual parameterization. Importantly, the dual parameterization enables us to formulate a sparse representation that captures information from the entire data set. This offers a compact and principled way of capturing uncertainty and enables us to incorporate new data without retraining whilst retaining predictive performance. We provide proof-of-concept demonstrations with the proposed approach for quantifying uncertainty in supervised learning on UCI benchmark tasks.
Learning Sequential Descriptors for Sequence-based Visual Place Recognition
Jul 08, 2022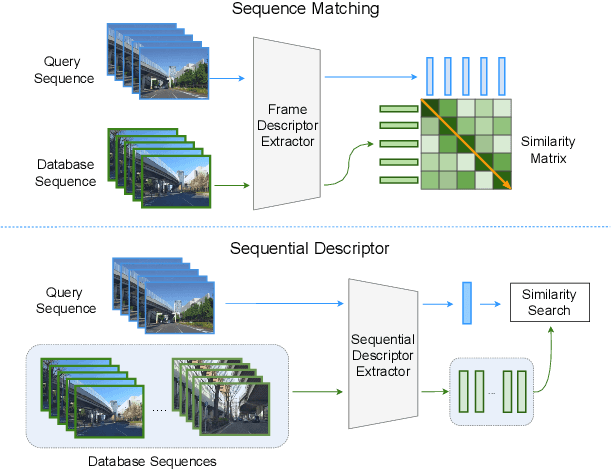

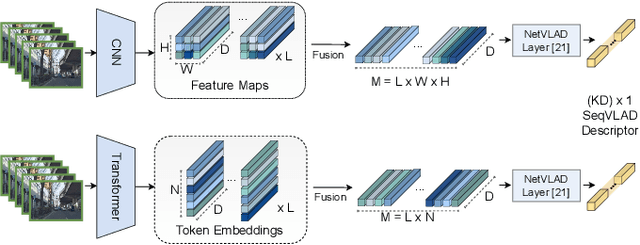
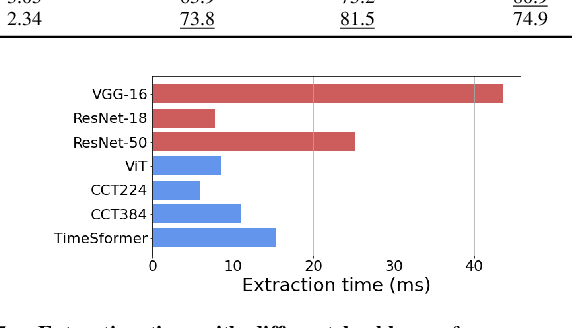
In robotics, Visual Place Recognition is a continuous process that receives as input a video stream to produce a hypothesis of the robot's current position within a map of known places. This task requires robust, scalable, and efficient techniques for real applications. This work proposes a detailed taxonomy of techniques using sequential descriptors, highlighting different mechanism to fuse the information from the individual images. This categorization is supported by a complete benchmark of experimental results that provides evidence on the strengths and weaknesses of these different architectural choices. In comparison to existing sequential descriptors methods, we further investigate the viability of Transformers instead of CNN backbones, and we propose a new ad-hoc sequence-level aggregator called SeqVLAD, which outperforms prior state of the art on different datasets. The code is available at https://github.com/vandal-vpr/vg-transformers.
Deep Visual Geo-localization Benchmark
Apr 07, 2022
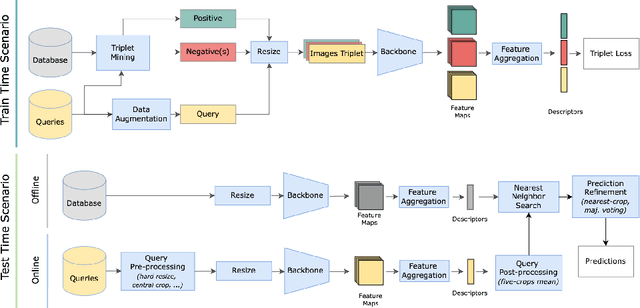
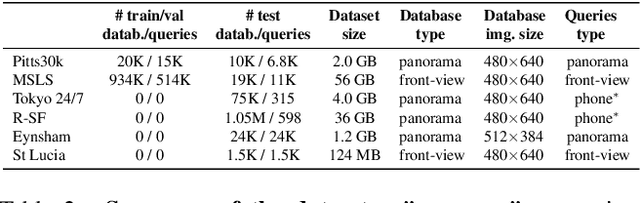

In this paper, we propose a new open-source benchmarking framework for Visual Geo-localization (VG) that allows to build, train, and test a wide range of commonly used architectures, with the flexibility to change individual components of a geo-localization pipeline. The purpose of this framework is twofold: i) gaining insights into how different components and design choices in a VG pipeline impact the final results, both in terms of performance (recall@N metric) and system requirements (such as execution time and memory consumption); ii) establish a systematic evaluation protocol for comparing different methods. Using the proposed framework, we perform a large suite of experiments which provide criteria for choosing backbone, aggregation and negative mining depending on the use-case and requirements. We also assess the impact of engineering techniques like pre/post-processing, data augmentation and image resizing, showing that better performance can be obtained through somewhat simple procedures: for example, downscaling the images' resolution to 80% can lead to similar results with a 36% savings in extraction time and dataset storage requirement. Code and trained models are available at https://deep-vg-bench.herokuapp.com/.