 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative World Modelling for Humanoids: 1X World Model Challenge Technical Report
Oct 08, 2025



World models are a powerful paradigm in AI and robotics, enabling agents to reason about the future by predicting visual observations or compact latent states. The 1X World Model Challenge introduces an open-source benchmark of real-world humanoid interaction, with two complementary tracks: sampling, focused on forecasting future image frames, and compression, focused on predicting future discrete latent codes. For the sampling track, we adapt the video generation foundation model Wan-2.2 TI2V-5B to video-state-conditioned future frame prediction. We condition the video generation on robot states using AdaLN-Zero, and further post-train the model using LoRA. For the compression track, we train a Spatio-Temporal Transformer model from scratch. Our models achieve 23.0 dB PSNR in the sampling task and a Top-500 CE of 6.6386 in the compression task, securing 1st place in both challenges.
Generalist World Model Pre-Training for Efficient Reinforcement Learning
Feb 26, 2025Sample-efficient robot learning is a longstanding goal in robotics. Inspired by the success of scaling in vision and language, the robotics community is now investigating large-scale offline datasets for robot learning. However, existing methods often require expert and/or reward-labeled task-specific data, which can be costly and limit their application in practice. In this paper, we consider a more realistic setting where the offline data consists of reward-free and non-expert multi-embodiment offline data. We show that generalist world model pre-training (WPT), together with retrieval-based experience rehearsal and execution guidance, enables efficient reinforcement learning (RL) and fast task adaptation with such non-curated data. In experiments over 72 visuomotor tasks, spanning 6 different embodiments, covering hard exploration, complex dynamics, and various visual properties, WPT achieves 35.65% and 35% higher aggregated score compared to widely used learning-from-scratch baselines, respectively.
Expansion of Visual Hints for Improved Generalization in Stereo Matching
Nov 01, 2022



We introduce visual hints expansion for guiding stereo matching to improve generalization. Our work is motivated by the robustness of Visual Inertial Odometry (VIO) in computer vision and robotics, where a sparse and unevenly distributed set of feature points characterizes a scene. To improve stereo matching, we propose to elevate 2D hints to 3D points. These sparse and unevenly distributed 3D visual hints are expanded using a 3D random geometric graph, which enhances the learning and inference process. We evaluate our proposal on multiple widely adopted benchmarks and show improved performance without access to additional sensors other than the image sequence. To highlight practical applicability and symbiosis with visual odometry, we demonstrate how our methods run on embedded hardware.
Novel View Synthesis via Depth-guided Skip Connections
Jan 05, 2021
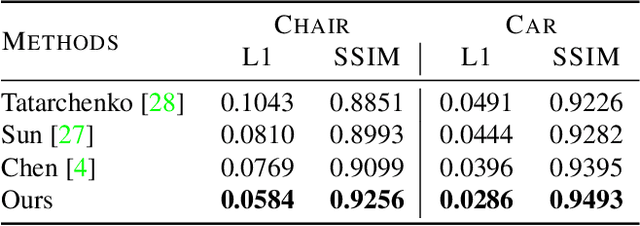
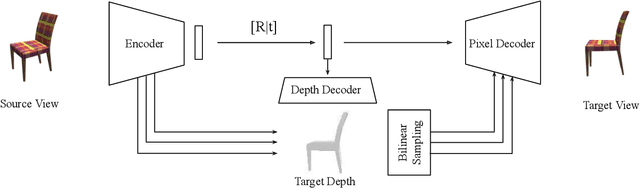
We introduce a principled approach for synthesizing new views of a scene given a single source image. Previous methods for novel view synthesis can be divided into image-based rendering methods (e.g. flow prediction) or pixel generation methods. Flow predictions enable the target view to re-use pixels directly, but can easily lead to distorted results. Directly regressing pixels can produce structurally consistent results but generally suffer from the lack of low-level details. In this paper, we utilize an encoder-decoder architecture to regress pixels of a target view. In order to maintain details, we couple the decoder aligned feature maps with skip connections, where the alignment is guided by predicted depth map of the target view. Our experimental results show that our method does not suffer from distortions and successfully preserves texture details with aligned skip connections.
Movement-induced Priors for Deep Stereo
Oct 18, 2020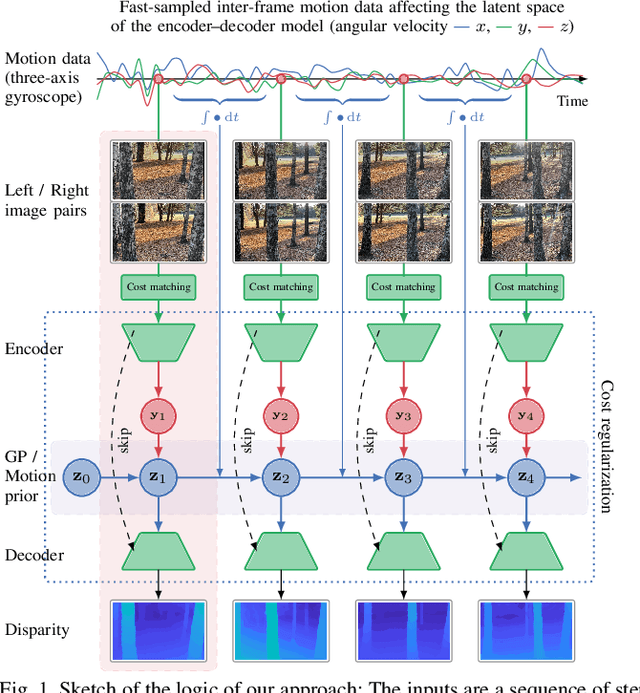
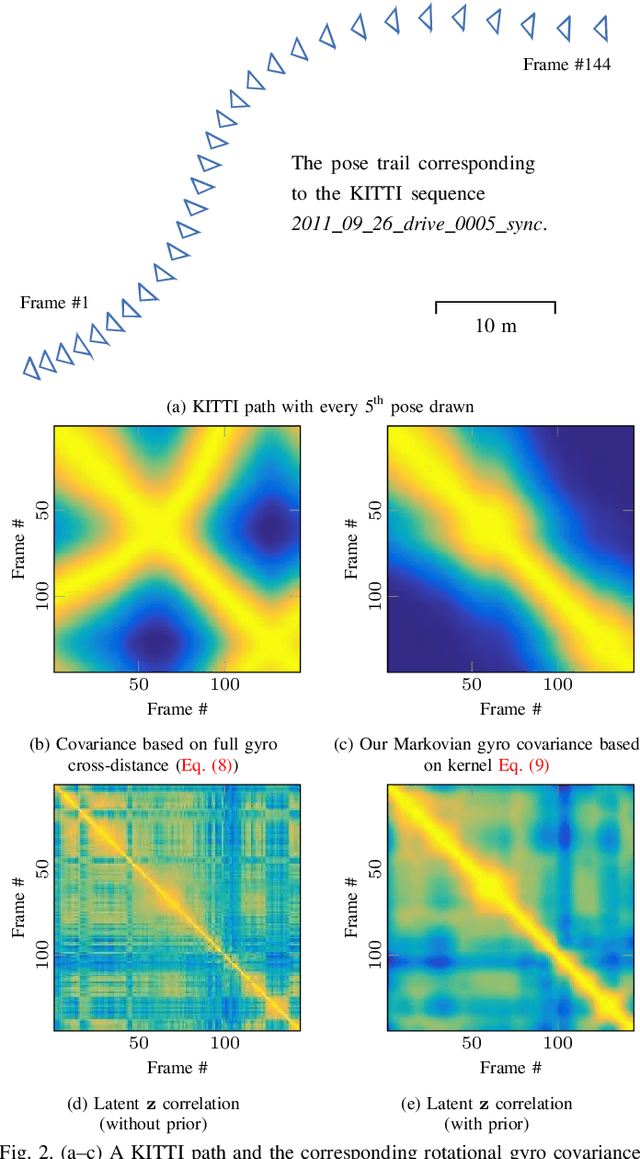
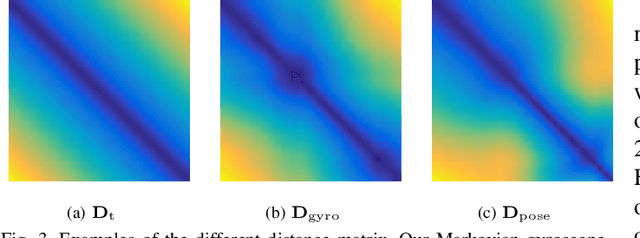

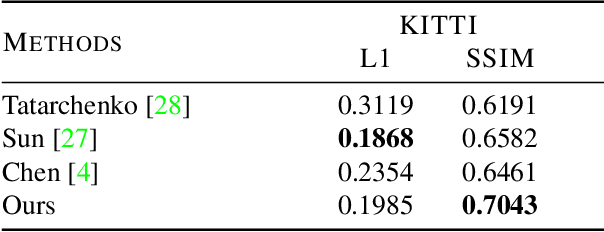
We propose a method for fusing stereo disparity estimation with movement-induced prior information. Instead of independent inference frame-by-frame, we formulate the problem as a non-parametric learning task in terms of a temporal Gaussian process prior with a movement-driven kernel for inter-frame reasoning. We present a hierarchy of three Gaussian process kernels depending on the availability of motion information, where our main focus is on a new gyroscope-driven kernel for handheld devices with low-quality MEMS sensors, thus also relaxing the requirement of having full 6D camera poses available. We show how our method can be combined with two state-of-the-art deep stereo methods. The method either work in a plug-and-play fashion with pre-trained deep stereo networks, or further improved by jointly training the kernels together with encoder-decoder architectures, leading to consistent improvement.
Deep Automodulators
Dec 21, 2019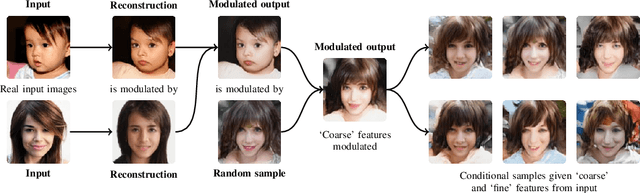
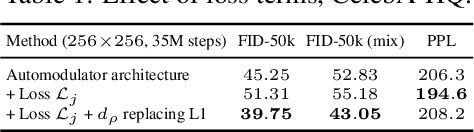
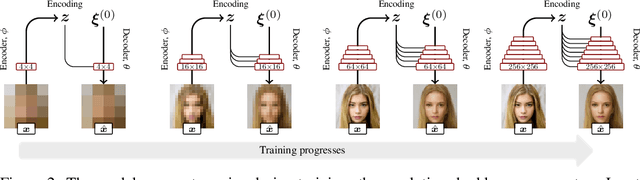

We introduce a novel autoencoder model that deviates from traditional autoencoders by using the full latent vector to independently modulate each layer in the decoder. We demonstrate how such an 'automodulator' allows for a principled approach to enforce latent space disentanglement, mixing of latent codes, and a straightforward way to utilise prior information that can be construed as a scale-specific invariance. Unlike the GAN models without encoders, autoencoder models can directly operate on new real input samples. This makes our model directly suitable for applications involving real-world inputs. As the architectural backbone, we extend recent generative autoencoder models that retain input identity and image sharpness at high resolutions better than VAEs. We show that our model achieves state-of-the-art latent space disentanglement and achieves high quality and diversity of output samples, as well as faithfulness of reconstructions.
Gaussian Process Priors for View-Aware Inference
Dec 06, 2019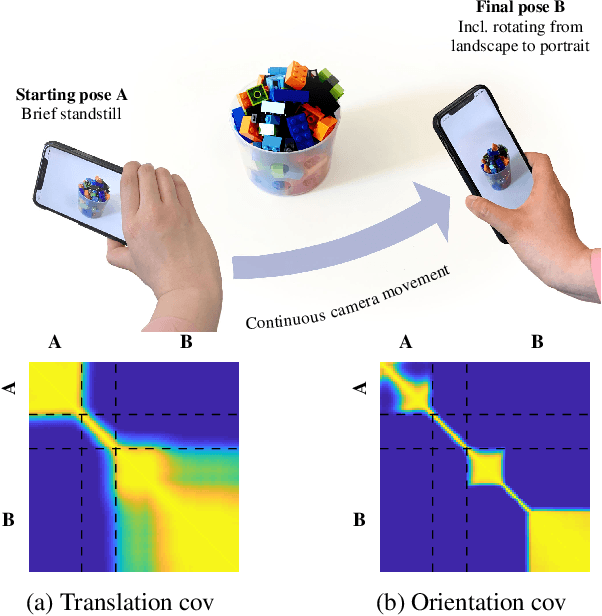
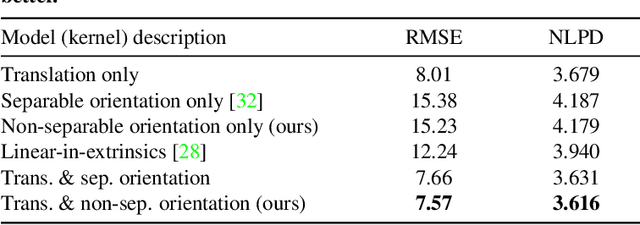
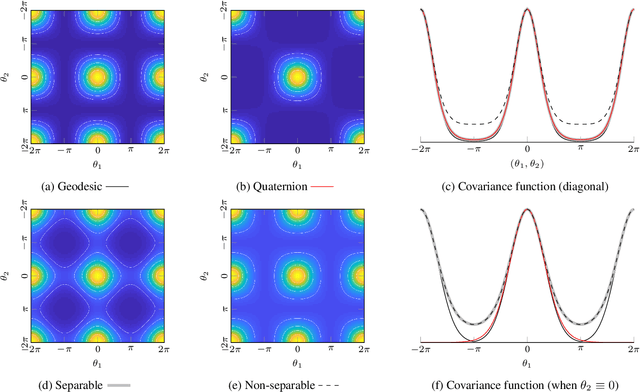

We derive a principled framework for encoding prior knowledge of information coupling between views or camera poses (translation and orientation) of a single scene. While deep neural networks have become the prominent solution to many tasks in computer vision, some important problems not so well suited for deep models have received less attention. These include uncertainty quantification, auxiliary data fusion, and real-time processing, which are instrumental for delivering practical methods with robust inference. While these are central goals in probabilistic machine learning, there is a tangible gap between the theory and practice of applying probabilistic methods to many modern vision problems. For this, we derive a novel parametric kernel (covariance function) in the pose space, $\mathrm{SE}(3)$, that encodes information about input pose relationships into larger models. We show how this soft-prior knowledge can be applied to improve performance on several real vision tasks, such as feature tracking, human face encoding, and view synthesis.
Iterative Path Reconstruction for Large-Scale Inertial Navigation on Smartphones
Jun 02, 2019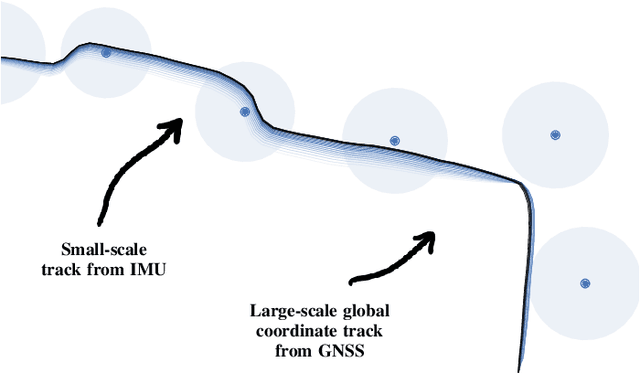
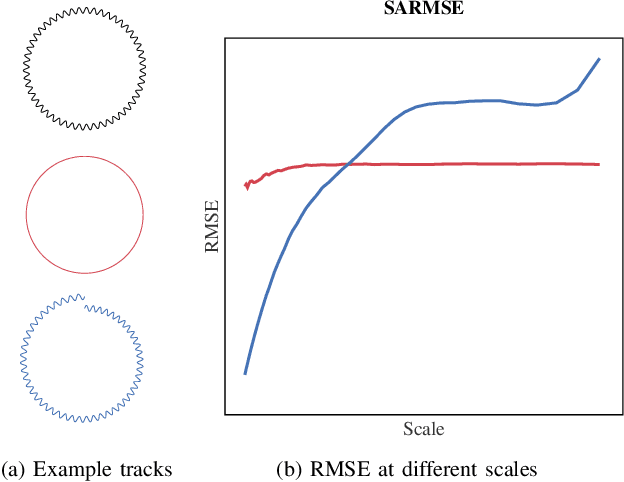
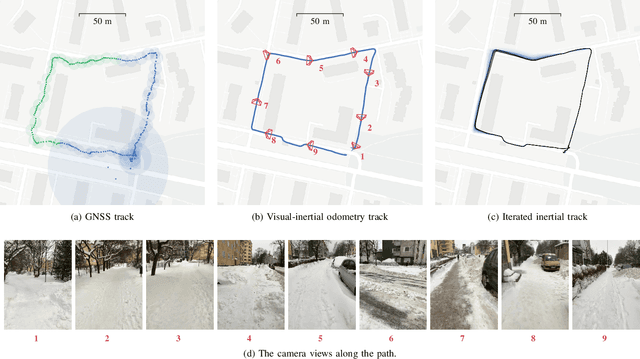
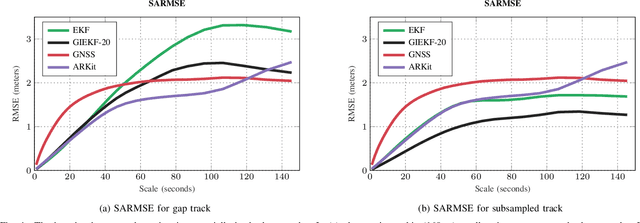
Modern smartphones have all the sensing capabilities required for accurate and robust navigation and tracking. In specific environments some data streams may be absent, less reliable, or flat out wrong. In particular, the GNSS signal can become flawed or silent inside buildings or in streets with tall buildings. In this application paper, we aim to advance the current state-of-the-art in motion estimation using inertial measurements in combination with partial GNSS data on standard smartphones. We show how iterative estimation methods help refine the positioning path estimates in retrospective use cases that can cover both fixed-interval and fixed-lag scenarios. We compare estimation results provided by global iterated Kalman filtering methods to those of a visual-inertial tracking scheme (Apple ARKit). The practical applicability is demonstrated on real-world use cases on empirical data acquired from both smartphones and tablet devices.
Multi-View Stereo by Temporal Nonparametric Fusion
Apr 12, 2019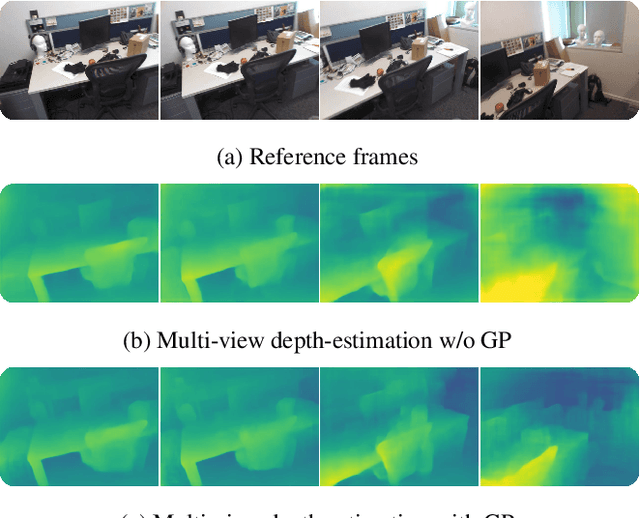
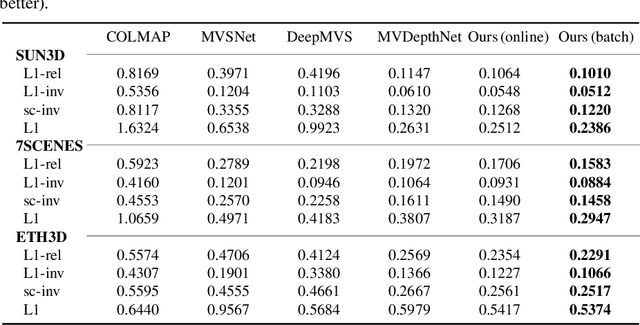


We propose a novel idea for depth estimation from unstructured multi-view image-pose pairs, where the model has capability to leverage information from previous latent-space encodings of the scene. This model uses pairs of images and poses, which are passed through an encoder-decoder model for disparity estimation. The novelty lies in soft-constraining the bottleneck layer by a nonparametric Gaussian process prior. We propose a pose-kernel structure that encourages similar poses to have resembling latent spaces. The flexibility of the Gaussian process (GP) prior provides adapting memory for fusing information from previous views. We train the encoder-decoder and the GP hyperparameters jointly end-to-end. In addition to a batch method, we derive a lightweight estimation scheme that circumvents standard pitfalls in scaling Gaussian process inference, and demonstrate how our scheme can run in real-time on smart devices.
Unstructured Multi-View Depth Estimation Using Mask-Based Multiplane Representation
Apr 10, 2019
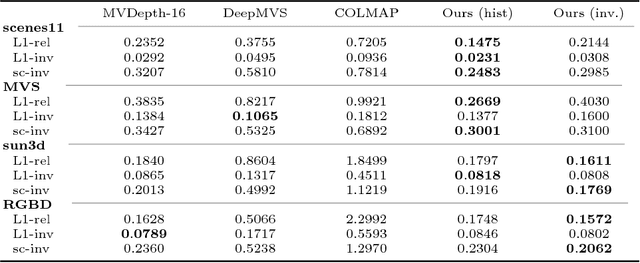
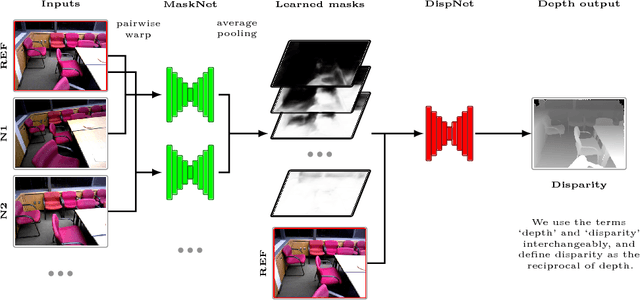
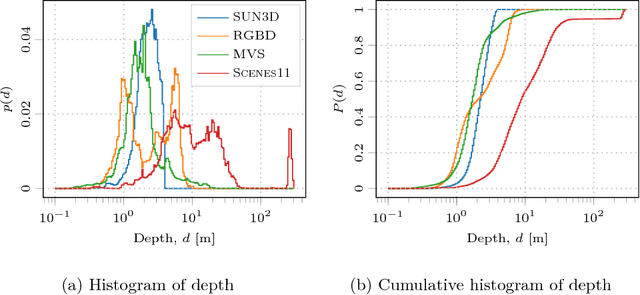
This paper presents a novel method, MaskMVS, to solve depth estimation for unstructured multi-view image-pose pairs. In the plane-sweep procedure, the depth planes are sampled by histogram matching that ensures covering the depth range of interest. Unlike other plane-sweep methods, we do not rely on a cost metric to explicitly build the cost volume, but instead infer a multiplane mask representation which regularizes the learning. Compared to many previous approaches, we show that our method is lightweight and generalizes well without requiring excessive training. We outperform the current state-of-the-art and show results on the sun3d, scenes11, MVS, and RGBD test data sets.