 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentational Multiplicity Should Be Exposed, Not Eliminated
Jun 17, 2022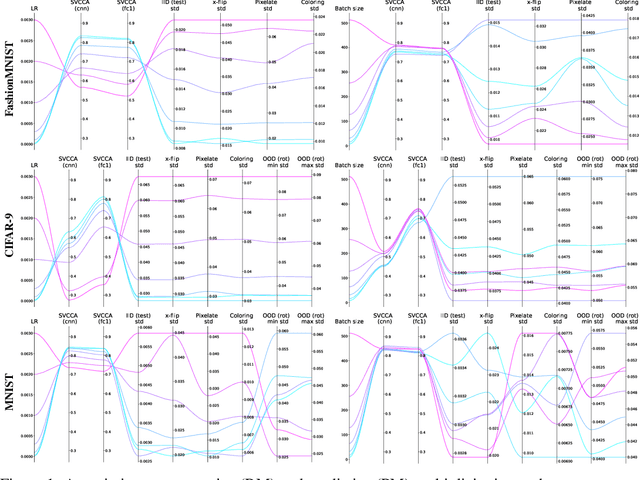
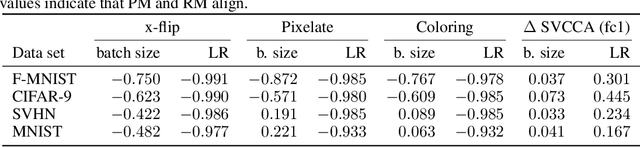
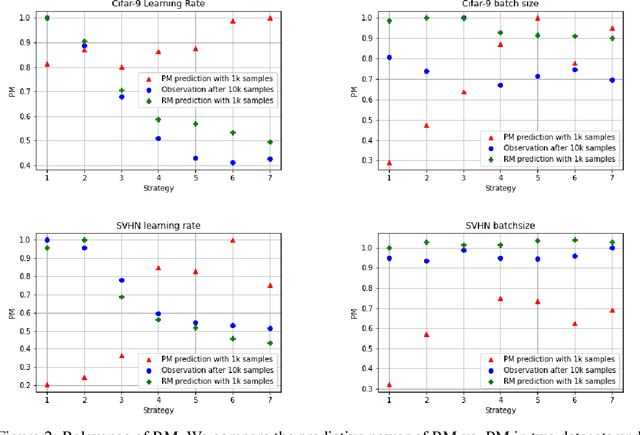
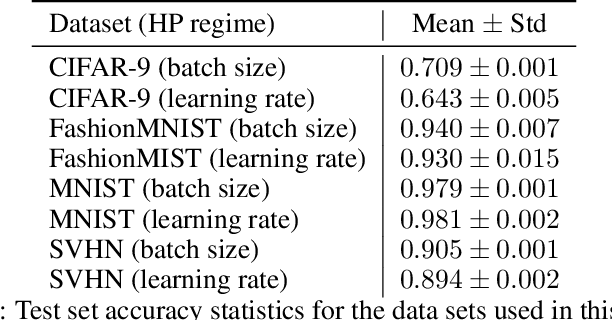
It is prevalent and well-observed, but poorly understood, that two machine learning models with similar performance during training can have very different real-world performance characteristics. This implies elusive differences in the internals of the models, manifesting as representational multiplicity (RM). We introduce a conceptual and experimental setup for analyzing RM and show that certain training methods systematically result in greater RM than others, measured by activation similarity via singular vector canonical correlation analysis (SVCCA). We further correlate it with predictive multiplicity measured by the variance in i.i.d. and out-of-distribution test set predictions, in four common image data sets. We call for systematic measurement and maximal exposure, not elimination, of RM in models. Qualitative tools such as our confabulator analysis can facilitate understanding and communication of RM effects to stakeholders.
Deep Automodulators
Dec 21, 2019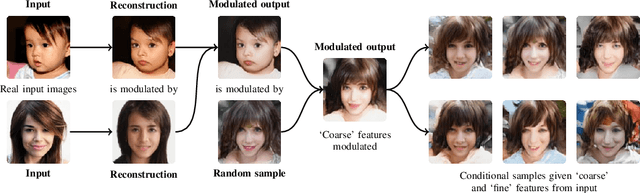
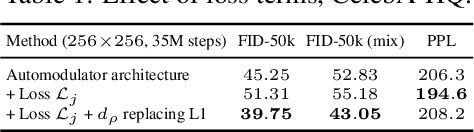

We introduce a novel autoencoder model that deviates from traditional autoencoders by using the full latent vector to independently modulate each layer in the decoder. We demonstrate how such an 'automodulator' allows for a principled approach to enforce latent space disentanglement, mixing of latent codes, and a straightforward way to utilise prior information that can be construed as a scale-specific invariance. Unlike the GAN models without encoders, autoencoder models can directly operate on new real input samples. This makes our model directly suitable for applications involving real-world inputs. As the architectural backbone, we extend recent generative autoencoder models that retain input identity and image sharpness at high resolutions better than VAEs. We show that our model achieves state-of-the-art latent space disentanglement and achieves high quality and diversity of output samples, as well as faithfulness of reconstructions.
Gaussian Process Priors for View-Aware Inference
Dec 06, 2019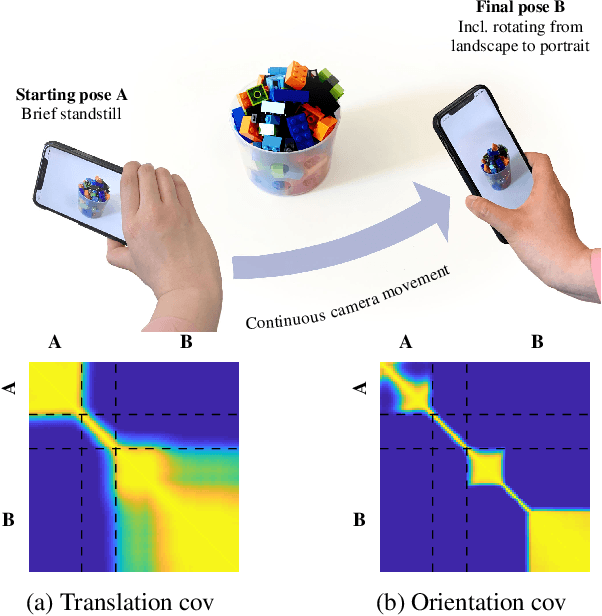
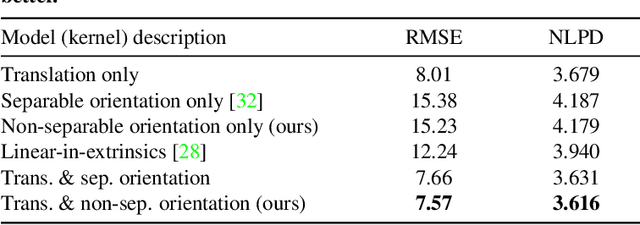
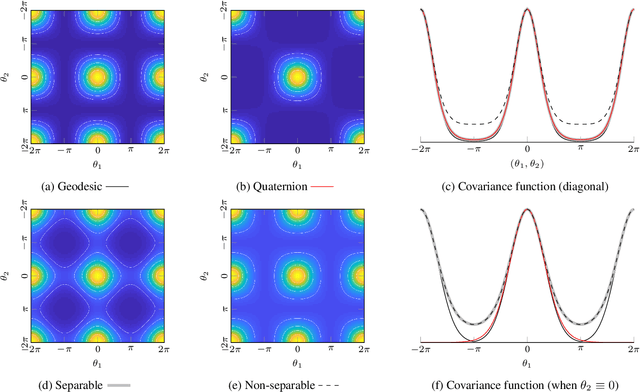

We derive a principled framework for encoding prior knowledge of information coupling between views or camera poses (translation and orientation) of a single scene. While deep neural networks have become the prominent solution to many tasks in computer vision, some important problems not so well suited for deep models have received less attention. These include uncertainty quantification, auxiliary data fusion, and real-time processing, which are instrumental for delivering practical methods with robust inference. While these are central goals in probabilistic machine learning, there is a tangible gap between the theory and practice of applying probabilistic methods to many modern vision problems. For this, we derive a novel parametric kernel (covariance function) in the pose space, $\mathrm{SE}(3)$, that encodes information about input pose relationships into larger models. We show how this soft-prior knowledge can be applied to improve performance on several real vision tasks, such as feature tracking, human face encoding, and view synthesis.
Towards Photographic Image Manipulation with Balanced Growing of Generative Autoencoders
Apr 12, 2019


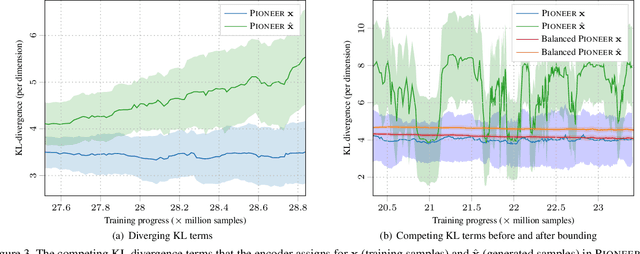
We build on recent advances in progressively growing generative autoencoder models. These models can encode and reconstruct existing images, and generate novel ones, at resolutions comparable to Generative Adversarial Networks (GANs), while consisting only of a single encoder and decoder network. The ability to reconstruct and arbitrarily modify existing samples such as images separates autoencoder models from GANs, but the output quality of image autoencoders has remained inferior. The recently proposed PIONEER autoencoder can reconstruct faces in the $256{\times}256$ CelebAHQ dataset, but like IntroVAE, another recent method, it often loses the identity of the person in the process. We propose an improved and simplified version of PIONEER and show significantly improved quality and preservation of the face identity in CelebAHQ, both visually and quantitatively. We also show evidence of state-of-the-art disentanglement of the latent space of the model, both quantitatively and via realistic image feature manipulations. On the LSUN Bedrooms dataset, our model also improves the results of the original PIONEER. Overall, our results indicate that the PIONEER networks provide a way to photorealistic face manipulation.
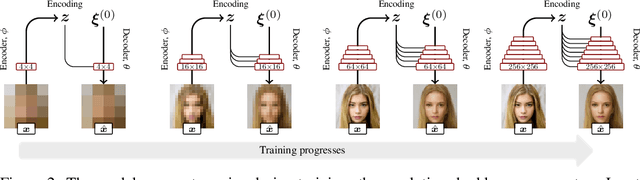
Pioneer Networks: Progressively Growing Generative Autoencoder
Oct 09, 2018

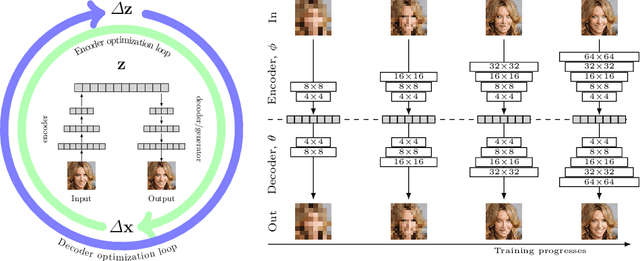

We introduce a novel generative autoencoder network model that learns to encode and reconstruct images with high quality and resolution, and supports smooth random sampling from the latent space of the encoder. Generative adversarial networks (GANs) are known for their ability to simulate random high-quality images, but they cannot reconstruct existing images. Previous works have attempted to extend GANs to support such inference but, so far, have not delivered satisfactory high-quality results. Instead, we propose the Progressively Growing Generative Autoencoder (PIONEER) network which achieves high-quality reconstruction with $128{\times}128$ images without requiring a GAN discriminator. We merge recent techniques for progressively building up the parts of the network with the recently introduced adversarial encoder-generator network. The ability to reconstruct input images is crucial in many real-world applications, and allows for precise intelligent manipulation of existing images. We show promising results in image synthesis and inference, with state-of-the-art results in CelebA inference tasks.
Recursive Chaining of Reversible Image-to-image Translators For Face Aging
Aug 06, 2018


This paper addresses the modeling and simulation of progressive changes over time, such as human face aging. By treating the age phases as a sequence of image domains, we construct a chain of transformers that map images from one age domain to the next. Leveraging recent adversarial image translation methods, our approach requires no training samples of the same individual at different ages. Here, the model must be flexible enough to translate a child face to a young adult, and all the way through the adulthood to old age. We find that some transformers in the chain can be recursively applied on their own output to cover multiple phases, compressing the chain. The structure of the chain also unearths information about the underlying physical process. We demonstrate the performance of our method with precise and intuitive metrics, and visually match with the face aging state-of-the-art.