 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentational Multiplicity Should Be Exposed, Not Eliminated
Paper and Code
Jun 17, 2022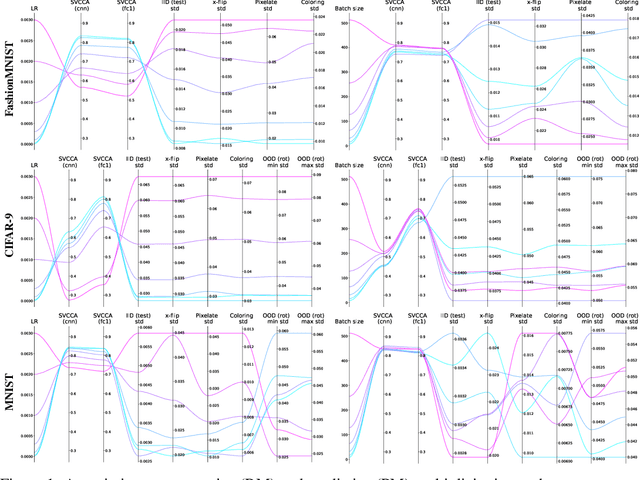
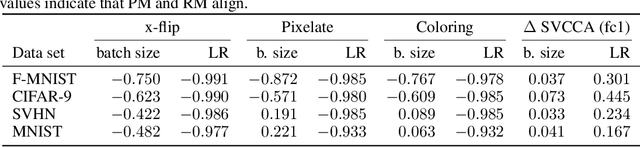
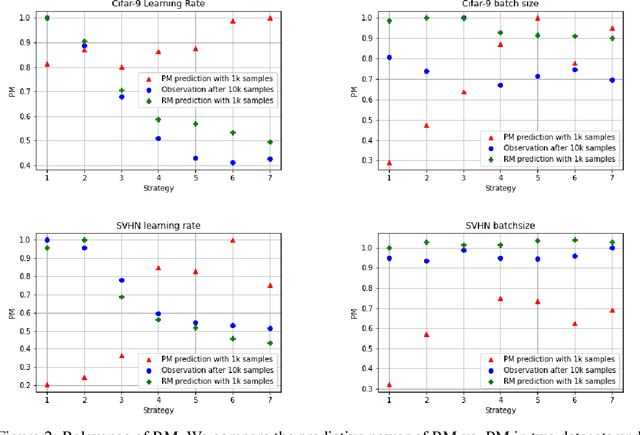
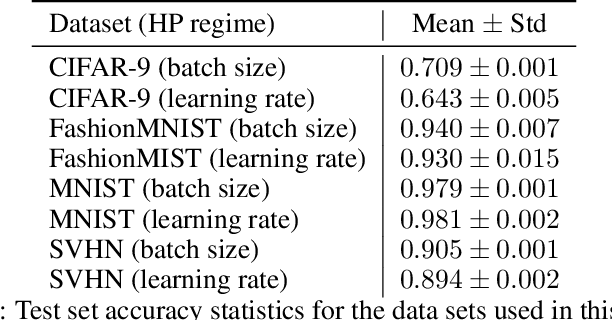
It is prevalent and well-observed, but poorly understood, that two machine learning models with similar performance during training can have very different real-world performance characteristics. This implies elusive differences in the internals of the models, manifesting as representational multiplicity (RM). We introduce a conceptual and experimental setup for analyzing RM and show that certain training methods systematically result in greater RM than others, measured by activation similarity via singular vector canonical correlation analysis (SVCCA). We further correlate it with predictive multiplicity measured by the variance in i.i.d. and out-of-distribution test set predictions, in four common image data sets. We call for systematic measurement and maximal exposure, not elimination, of RM in models. Qualitative tools such as our confabulator analysis can facilitate understanding and communication of RM effects to stakeholders.