 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Photographic Image Manipulation with Balanced Growing of Generative Autoencoders
Paper and Code



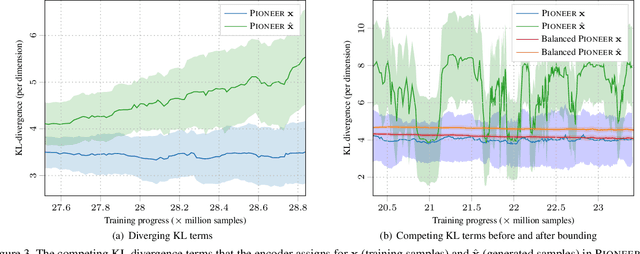
We build on recent advances in progressively growing generative autoencoder models. These models can encode and reconstruct existing images, and generate novel ones, at resolutions comparable to Generative Adversarial Networks (GANs), while consisting only of a single encoder and decoder network. The ability to reconstruct and arbitrarily modify existing samples such as images separates autoencoder models from GANs, but the output quality of image autoencoders has remained inferior. The recently proposed PIONEER autoencoder can reconstruct faces in the $256{\times}256$ CelebAHQ dataset, but like IntroVAE, another recent method, it often loses the identity of the person in the process. We propose an improved and simplified version of PIONEER and show significantly improved quality and preservation of the face identity in CelebAHQ, both visually and quantitatively. We also show evidence of state-of-the-art disentanglement of the latent space of the model, both quantitatively and via realistic image feature manipulations. On the LSUN Bedrooms dataset, our model also improves the results of the original PIONEER. Overall, our results indicate that the PIONEER networks provide a way to photorealistic face manipulation.