 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Process Priors for View-Aware Inference
Paper and Code
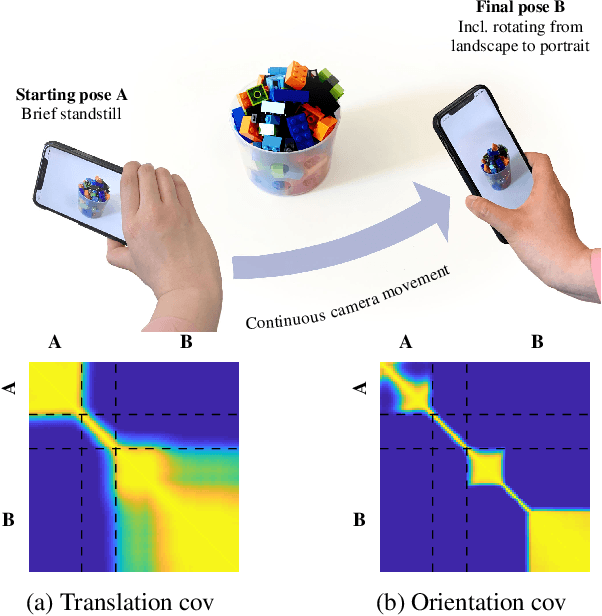
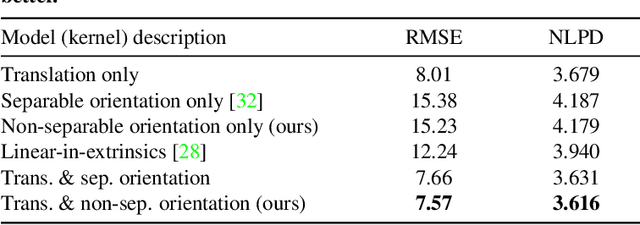
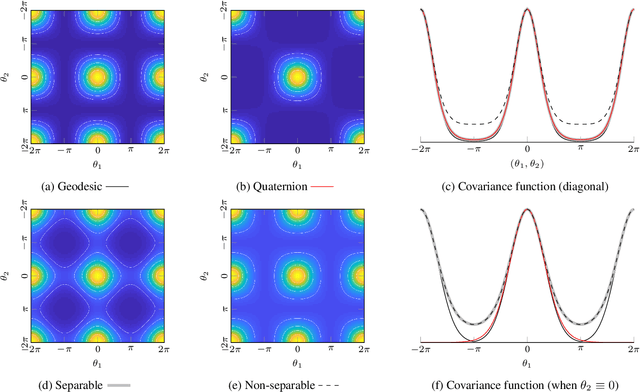

We derive a principled framework for encoding prior knowledge of information coupling between views or camera poses (translation and orientation) of a single scene. While deep neural networks have become the prominent solution to many tasks in computer vision, some important problems not so well suited for deep models have received less attention. These include uncertainty quantification, auxiliary data fusion, and real-time processing, which are instrumental for delivering practical methods with robust inference. While these are central goals in probabilistic machine learning, there is a tangible gap between the theory and practice of applying probabilistic methods to many modern vision problems. For this, we derive a novel parametric kernel (covariance function) in the pose space, $\mathrm{SE}(3)$, that encodes information about input pose relationships into larger models. We show how this soft-prior knowledge can be applied to improve performance on several real vision tasks, such as feature tracking, human face encoding, and view synthesis.