 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction-Guided Attention for Video Action Anticipation
Mar 02, 2026Anticipating future actions in videos is challenging, as the observed frames provide only evidence of past activities, requiring the inference of latent intentions to predict upcoming actions. Existing transformer-based approaches, which rely on dot-product attention over pixel representations, often lack the high-level semantics necessary to model video sequences for effective action anticipation. As a result, these methods tend to overfit to explicit visual cues present in the past frames, limiting their ability to capture underlying intentions and degrading generalization to unseen samples. To address this, we propose Action-Guided Attention (AGA), an attention mechanism that explicitly leverages predicted action sequences as queries and keys to guide sequence modeling. Our approach fosters the attention module to emphasize relevant moments from the past based on the upcoming activity and combine this information with the current frame embedding via a dedicated gating function. The design of AGA enables post-training analysis of the knowledge discovered from the training set. Experiments on the widely adopted EPIC-Kitchens-100 benchmark demonstrate that AGA generalizes well from validation to unseen test sets. Post-training analysis can further examine the action dependencies captured by the model and the counterfactual evidence it has internalized, offering transparent and interpretable insights into its anticipative predictions.
DIETA: A Decoder-only transformer-based model for Italian-English machine TrAnslation
Jan 25, 2026In this paper, we present DIETA, a small, decoder-only Transformer model with 0.5 billion parameters, specifically designed and trained for Italian-English machine translation. We collect and curate a large parallel corpus consisting of approximately 207 million Italian-English sentence pairs across diverse domains, including parliamentary proceedings, legal texts, web-crawled content, subtitles, news, literature and 352 million back-translated data using pretrained models. Additionally, we create and release a new small-scale evaluation set, consisting of 450 sentences, based on 2025 WikiNews articles, enabling assessment of translation quality on contemporary text. Comprehensive evaluations show that DIETA achieves competitive performance on multiple Italian-English benchmarks, consistently ranking in the second quartile of a 32-system leaderboard and outperforming most other sub-3B models on four out of five test suites. The training script, trained models, curated corpus, and newly introduced evaluation set are made publicly available, facilitating further research and development in specialized Italian-English machine translation. https://github.com/pkasela/DIETA-Machine-Translation
Video Unlearning via Low-Rank Refusal Vector
Jun 09, 2025
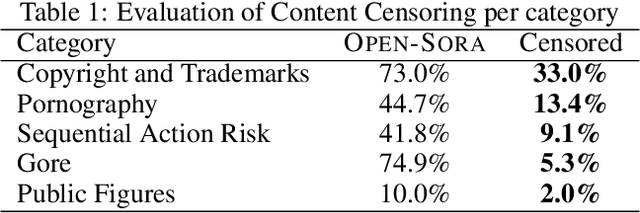
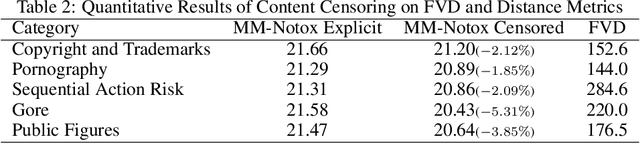

Video generative models democratize the creation of visual content through intuitive instruction following, but they also inherit the biases and harmful concepts embedded within their web-scale training data. This inheritance creates a significant risk, as users can readily generate undesirable and even illegal content. This work introduces the first unlearning technique tailored explicitly for video diffusion models to address this critical issue. Our method requires 5 multi-modal prompt pairs only. Each pair contains a "safe" and an "unsafe" example that differ only by the target concept. Averaging their per-layer latent differences produces a "refusal vector", which, once subtracted from the model parameters, neutralizes the unsafe concept. We introduce a novel low-rank factorization approach on the covariance difference of embeddings that yields robust refusal vectors. This isolates the target concept while minimizing collateral unlearning of other semantics, thus preserving the visual quality of the generated video. Our method preserves the model's generation quality while operating without retraining or access to the original training data. By embedding the refusal direction directly into the model's weights, the suppression mechanism becomes inherently more robust against adversarial bypass attempts compared to surface-level input-output filters. In a thorough qualitative and quantitative evaluation, we show that we can neutralize a variety of harmful contents, including explicit nudity, graphic violence, copyrights, and trademarks. Project page: https://www.pinlab.org/video-unlearning.
Towards Understanding and Quantifying Uncertainty for Text-to-Image Generation
Dec 04, 2024Uncertainty quantification in text-to-image (T2I) generative models is crucial for understanding model behavior and improving output reliability. In this paper, we are the first to quantify and evaluate the uncertainty of T2I models with respect to the prompt. Alongside adapting existing approaches designed to measure uncertainty in the image space, we also introduce Prompt-based UNCertainty Estimation for T2I models (PUNC), a novel method leveraging Large Vision-Language Models (LVLMs) to better address uncertainties arising from the semantics of the prompt and generated images. PUNC utilizes a LVLM to caption a generated image, and then compares the caption with the original prompt in the more semantically meaningful text space. PUNC also enables the disentanglement of both aleatoric and epistemic uncertainties via precision and recall, which image-space approaches are unable to do. Extensive experiments demonstrate that PUNC outperforms state-of-the-art uncertainty estimation techniques across various settings. Uncertainty quantification in text-to-image generation models can be used on various applications including bias detection, copyright protection, and OOD detection. We also introduce a comprehensive dataset of text prompts and generation pairs to foster further research in uncertainty quantification for generative models. Our findings illustrate that PUNC not only achieves competitive performance but also enables novel applications in evaluating and improving the trustworthiness of text-to-image models.
Make Me a BNN: A Simple Strategy for Estimating Bayesian Uncertainty from Pre-trained Models
Dec 23, 2023



Deep Neural Networks (DNNs) are powerful tools for various computer vision tasks, yet they often struggle with reliable uncertainty quantification - a critical requirement for real-world applications. Bayesian Neural Networks (BNN) are equipped for uncertainty estimation but cannot scale to large DNNs that are highly unstable to train. To address this challenge, we introduce the Adaptable Bayesian Neural Network (ABNN), a simple and scalable strategy to seamlessly transform DNNs into BNNs in a post-hoc manner with minimal computational and training overheads. ABNN preserves the main predictive properties of DNNs while enhancing their uncertainty quantification abilities through simple BNN adaptation layers (attached to normalization layers) and a few fine-tuning steps on pre-trained models. We conduct extensive experiments across multiple datasets for image classification and semantic segmentation tasks, and our results demonstrate that ABNN achieves state-of-the-art performance without the computational budget typically associated with ensemble methods.
The Robust Semantic Segmentation UNCV2023 Challenge Results
Sep 27, 2023



This paper outlines the winning solutions employed in addressing the MUAD uncertainty quantification challenge held at ICCV 2023. The challenge was centered around semantic segmentation in urban environments, with a particular focus on natural adversarial scenarios. The report presents the results of 19 submitted entries, with numerous techniques drawing inspiration from cutting-edge uncertainty quantification methodologies presented at prominent conferences in the fields of computer vision and machine learning and journals over the past few years. Within this document, the challenge is introduced, shedding light on its purpose and objectives, which primarily revolved around enhancing the robustness of semantic segmentation in urban scenes under varying natural adversarial conditions. The report then delves into the top-performing solutions. Moreover, the document aims to provide a comprehensive overview of the diverse solutions deployed by all participants. By doing so, it seeks to offer readers a deeper insight into the array of strategies that can be leveraged to effectively handle the inherent uncertainties associated with autonomous driving and semantic segmentation, especially within urban environments.
RADiff: Controllable Diffusion Models for Radio Astronomical Maps Generation
Jul 05, 2023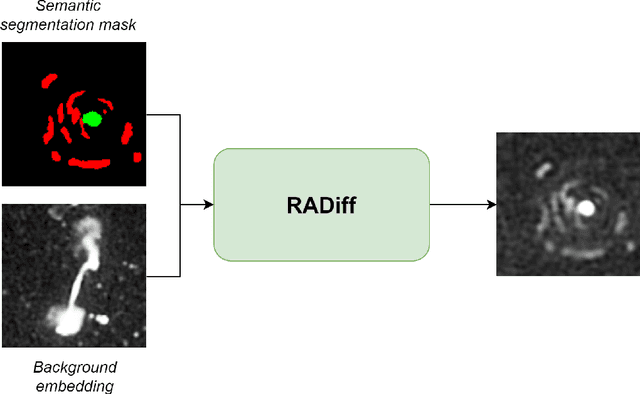
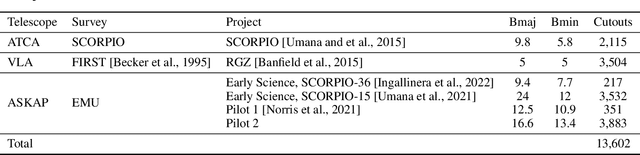
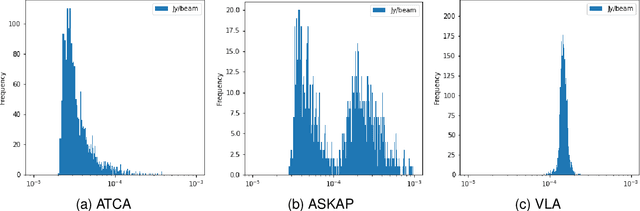
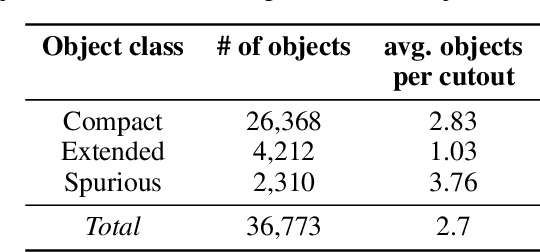
Along with the nearing completion of the Square Kilometre Array (SKA), comes an increasing demand for accurate and reliable automated solutions to extract valuable information from the vast amount of data it will allow acquiring. Automated source finding is a particularly important task in this context, as it enables the detection and classification of astronomical objects. Deep-learning-based object detection and semantic segmentation models have proven to be suitable for this purpose. However, training such deep networks requires a high volume of labeled data, which is not trivial to obtain in the context of radio astronomy. Since data needs to be manually labeled by experts, this process is not scalable to large dataset sizes, limiting the possibilities of leveraging deep networks to address several tasks. In this work, we propose RADiff, a generative approach based on conditional diffusion models trained over an annotated radio dataset to generate synthetic images, containing radio sources of different morphologies, to augment existing datasets and reduce the problems caused by class imbalances. We also show that it is possible to generate fully-synthetic image-annotation pairs to automatically augment any annotated dataset. We evaluate the effectiveness of this approach by training a semantic segmentation model on a real dataset augmented in two ways: 1) using synthetic images obtained from real masks, and 2) generating images from synthetic semantic masks. We show an improvement in performance when applying augmentation, gaining up to 18% in performance when using real masks and 4% when augmenting with synthetic masks. Finally, we employ this model to generate large-scale radio maps with the objective of simulating Data Challenges.
Learning to Mask and Permute Visual Tokens for Vision Transformer Pre-Training
Jun 12, 2023
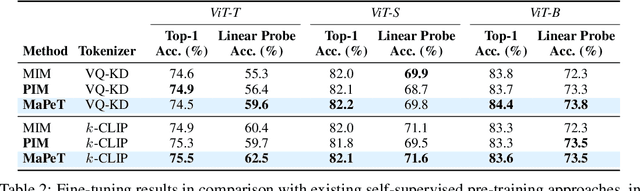
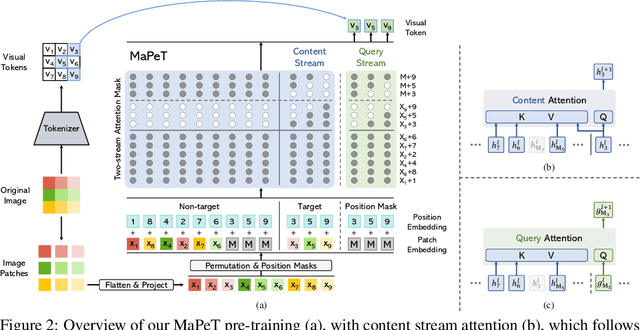
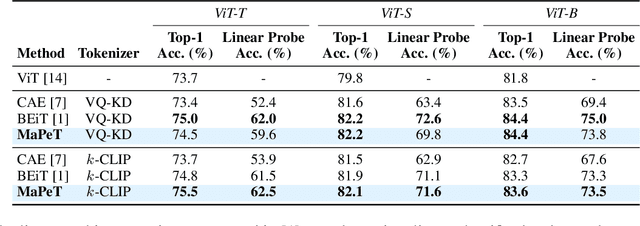
The use of self-supervised pre-training has emerged as a promising approach to enhance the performance of visual tasks such as image classification. In this context, recent approaches have employed the Masked Image Modeling paradigm, which pre-trains a backbone by reconstructing visual tokens associated with randomly masked image patches. This masking approach, however, introduces noise into the input data during pre-training, leading to discrepancies that can impair performance during the fine-tuning phase. Furthermore, input masking neglects the dependencies between corrupted patches, increasing the inconsistencies observed in downstream fine-tuning tasks. To overcome these issues, we propose a new self-supervised pre-training approach, named Masked and Permuted Vision Transformer (MaPeT), that employs autoregressive and permuted predictions to capture intra-patch dependencies. In addition, MaPeT employs auxiliary positional information to reduce the disparity between the pre-training and fine-tuning phases. In our experiments, we employ a fair setting to ensure reliable and meaningful comparisons and conduct investigations on multiple visual tokenizers, including our proposed $k$-CLIP which directly employs discretized CLIP features. Our results demonstrate that MaPeT achieves competitive performance on ImageNet, compared to baselines and competitors under the same model setting. Source code and trained models are publicly available at: https://github.com/aimagelab/MaPeT.
Reproducibility is Nothing without Correctness: The Importance of Testing Code in NLP
Mar 31, 2023



Despite its pivotal role in research experiments, code correctness is often presumed only on the basis of the perceived quality of the results. This comes with the risk of erroneous outcomes and potentially misleading findings. To address this issue, we posit that the current focus on result reproducibility should go hand in hand with the emphasis on coding best practices. We bolster our call to the NLP community by presenting a case study, in which we identify (and correct) three bugs in widely used open-source implementations of the state-of-the-art Conformer architecture. Through comparative experiments on automatic speech recognition and translation in various language settings, we demonstrate that the existence of bugs does not prevent the achievement of good and reproducible results and can lead to incorrect conclusions that potentially misguide future research. In response to this, this study is a call to action toward the adoption of coding best practices aimed at fostering correctness and improving the quality of the developed software.
Fixing Overconfidence in Dynamic Neural Networks
Feb 24, 2023


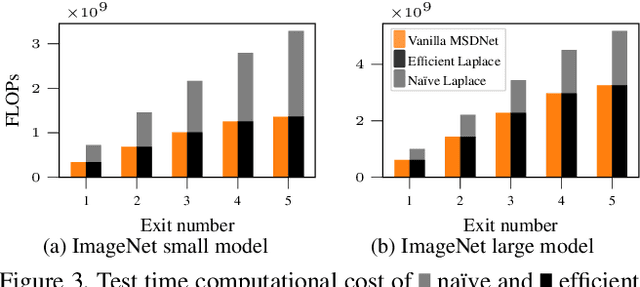
Dynamic neural networks are a recent technique that promises a remedy for the increasing size of modern deep learning models by dynamically adapting their computational cost to the difficulty of the input samples. In this way, the model can adjust to a limited computational budget. However, the poor quality of uncertainty estimates in deep learning models makes it difficult to distinguish between hard and easy samples. To address this challenge, we present a computationally efficient approach for post-hoc uncertainty quantification in dynamic neural networks. We show that adequately quantifying and accounting for both aleatoric and epistemic uncertainty through a probabilistic treatment of the last layers improves the predictive performance and aids decision-making when determining the computational budget. In the experiments, we show improvements on CIFAR-100 and ImageNet in terms of accuracy, capturing uncertainty, and calibration error.