 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Mask and Permute Visual Tokens for Vision Transformer Pre-Training
Paper and Code

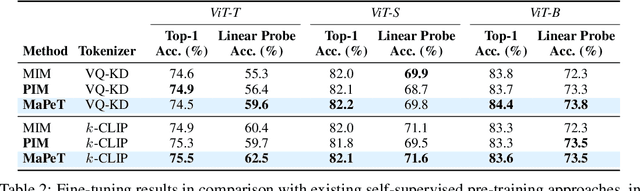
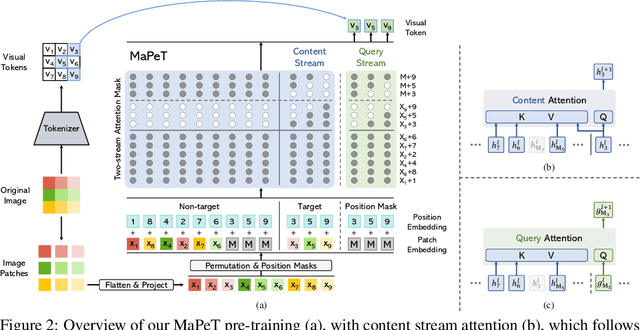
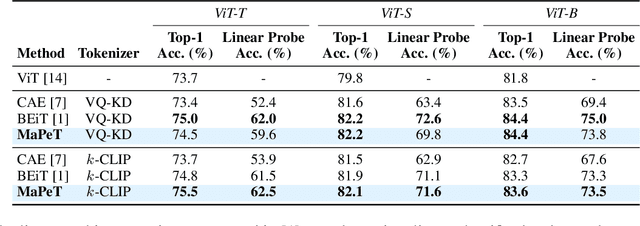
The use of self-supervised pre-training has emerged as a promising approach to enhance the performance of visual tasks such as image classification. In this context, recent approaches have employed the Masked Image Modeling paradigm, which pre-trains a backbone by reconstructing visual tokens associated with randomly masked image patches. This masking approach, however, introduces noise into the input data during pre-training, leading to discrepancies that can impair performance during the fine-tuning phase. Furthermore, input masking neglects the dependencies between corrupted patches, increasing the inconsistencies observed in downstream fine-tuning tasks. To overcome these issues, we propose a new self-supervised pre-training approach, named Masked and Permuted Vision Transformer (MaPeT), that employs autoregressive and permuted predictions to capture intra-patch dependencies. In addition, MaPeT employs auxiliary positional information to reduce the disparity between the pre-training and fine-tuning phases. In our experiments, we employ a fair setting to ensure reliable and meaningful comparisons and conduct investigations on multiple visual tokenizers, including our proposed $k$-CLIP which directly employs discretized CLIP features. Our results demonstrate that MaPeT achieves competitive performance on ImageNet, compared to baselines and competitors under the same model setting. Source code and trained models are publicly available at: https://github.com/aimagelab/MaPeT.