 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceive, Query & Reason: Enhancing Video QA with Question-Guided Temporal Queries
Dec 26, 2024



Video Question Answering (Video QA) is a challenging video understanding task that requires models to comprehend entire videos, identify the most relevant information based on contextual cues from a given question, and reason accurately to provide answers. Recent advancements in Multimodal Large Language Models (MLLMs) have transformed video QA by leveraging their exceptional commonsense reasoning capabilities. This progress is largely driven by the effective alignment between visual data and the language space of MLLMs. However, for video QA, an additional space-time alignment poses a considerable challenge for extracting question-relevant information across frames. In this work, we investigate diverse temporal modeling techniques to integrate with MLLMs, aiming to achieve question-guided temporal modeling that leverages pre-trained visual and textual alignment in MLLMs. We propose T-Former, a novel temporal modeling method that creates a question-guided temporal bridge between frame-wise visual perception and the reasoning capabilities of LLMs. Our evaluation across multiple video QA benchmarks demonstrates that T-Former competes favorably with existing temporal modeling approaches and aligns with recent advancements in video QA.
Training-Free Open-Vocabulary Segmentation with Offline Diffusion-Augmented Prototype Generation
Apr 09, 2024Open-vocabulary semantic segmentation aims at segmenting arbitrary categories expressed in textual form. Previous works have trained over large amounts of image-caption pairs to enforce pixel-level multimodal alignments. However, captions provide global information about the semantics of a given image but lack direct localization of individual concepts. Further, training on large-scale datasets inevitably brings significant computational costs. In this paper, we propose FreeDA, a training-free diffusion-augmented method for open-vocabulary semantic segmentation, which leverages the ability of diffusion models to visually localize generated concepts and local-global similarities to match class-agnostic regions with semantic classes. Our approach involves an offline stage in which textual-visual reference embeddings are collected, starting from a large set of captions and leveraging visual and semantic contexts. At test time, these are queried to support the visual matching process, which is carried out by jointly considering class-agnostic regions and global semantic similarities. Extensive analyses demonstrate that FreeDA achieves state-of-the-art performance on five datasets, surpassing previous methods by more than 7.0 average points in terms of mIoU and without requiring any training.
Learning to Mask and Permute Visual Tokens for Vision Transformer Pre-Training
Jun 12, 2023
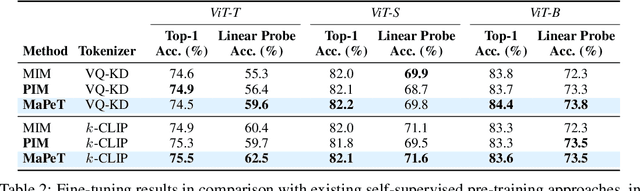
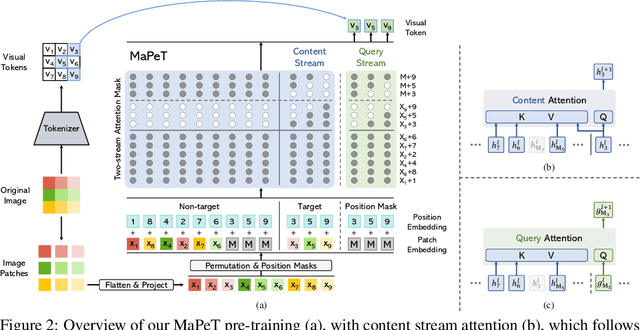
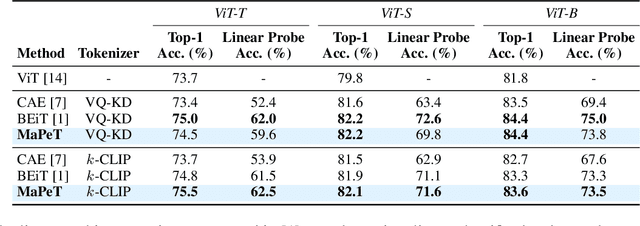
The use of self-supervised pre-training has emerged as a promising approach to enhance the performance of visual tasks such as image classification. In this context, recent approaches have employed the Masked Image Modeling paradigm, which pre-trains a backbone by reconstructing visual tokens associated with randomly masked image patches. This masking approach, however, introduces noise into the input data during pre-training, leading to discrepancies that can impair performance during the fine-tuning phase. Furthermore, input masking neglects the dependencies between corrupted patches, increasing the inconsistencies observed in downstream fine-tuning tasks. To overcome these issues, we propose a new self-supervised pre-training approach, named Masked and Permuted Vision Transformer (MaPeT), that employs autoregressive and permuted predictions to capture intra-patch dependencies. In addition, MaPeT employs auxiliary positional information to reduce the disparity between the pre-training and fine-tuning phases. In our experiments, we employ a fair setting to ensure reliable and meaningful comparisons and conduct investigations on multiple visual tokenizers, including our proposed $k$-CLIP which directly employs discretized CLIP features. Our results demonstrate that MaPeT achieves competitive performance on ImageNet, compared to baselines and competitors under the same model setting. Source code and trained models are publicly available at: https://github.com/aimagelab/MaPeT.
Parents and Children: Distinguishing Multimodal DeepFakes from Natural Images
Apr 02, 2023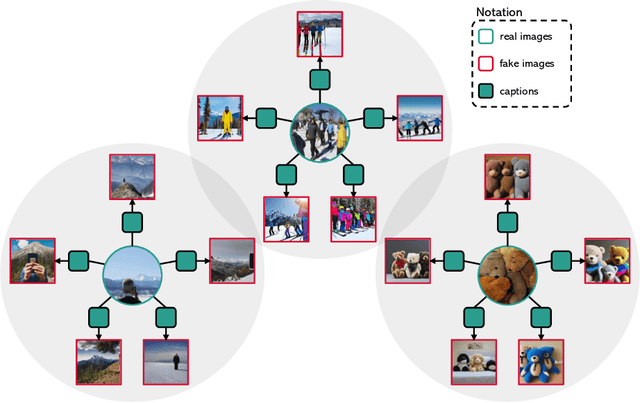
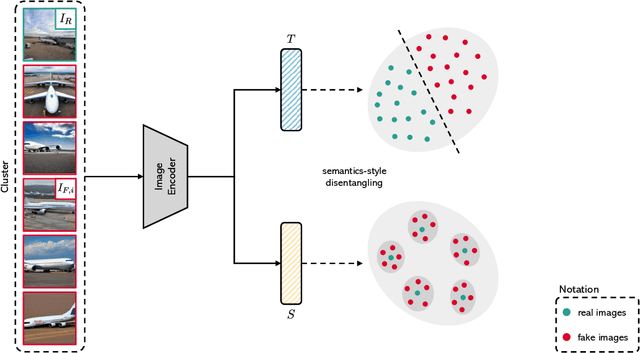
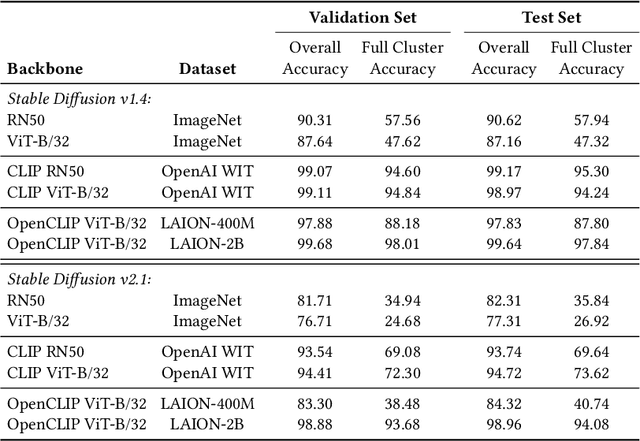
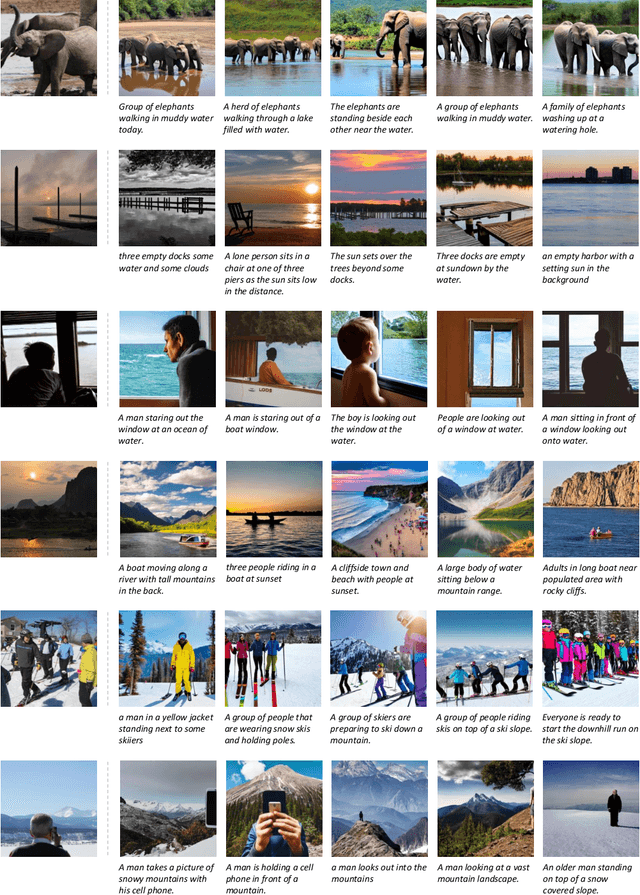
Recent advancements in diffusion models have enabled the generation of realistic deepfakes by writing textual prompts in natural language. While these models have numerous benefits across various sectors, they have also raised concerns about the potential misuse of fake images and cast new pressures on fake image detection. In this work, we pioneer a systematic study of the authenticity of fake images generated by state-of-the-art diffusion models. Firstly, we conduct a comprehensive study on the performance of contrastive and classification-based visual features. Our analysis demonstrates that fake images share common low-level cues, which render them easily recognizable. Further, we devise a multimodal setting wherein fake images are synthesized by different textual captions, which are used as seeds for a generator. Under this setting, we quantify the performance of fake detection strategies and introduce a contrastive-based disentangling strategy which let us analyze the role of the semantics of textual descriptions and low-level perceptual cues. Finally, we release a new dataset, called COCOFake, containing about 600k images generated from original COCO images.