 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMy Answer Is NOT 'Fair': Mitigating Social Bias in Vision-Language Models via Fair and Biased Residuals
May 26, 2025



Social bias is a critical issue in large vision-language models (VLMs), where fairness- and ethics-related problems harm certain groups of people in society. It is unknown to what extent VLMs yield social bias in generative responses. In this study, we focus on evaluating and mitigating social bias on both the model's response and probability distribution. To do so, we first evaluate four state-of-the-art VLMs on PAIRS and SocialCounterfactuals datasets with the multiple-choice selection task. Surprisingly, we find that models suffer from generating gender-biased or race-biased responses. We also observe that models are prone to stating their responses are fair, but indeed having mis-calibrated confidence levels towards particular social groups. While investigating why VLMs are unfair in this study, we observe that VLMs' hidden layers exhibit substantial fluctuations in fairness levels. Meanwhile, residuals in each layer show mixed effects on fairness, with some contributing positively while some lead to increased bias. Based on these findings, we propose a post-hoc method for the inference stage to mitigate social bias, which is training-free and model-agnostic. We achieve this by ablating bias-associated residuals while amplifying fairness-associated residuals on model hidden layers during inference. We demonstrate that our post-hoc method outperforms the competing training strategies, helping VLMs have fairer responses and more reliable confidence levels.
Memory Helps, but Confabulation Misleads: Understanding Streaming Events in Videos with MLLMs
Feb 21, 2025Multimodal large language models (MLLMs) have demonstrated strong performance in understanding videos holistically, yet their ability to process streaming videos-videos are treated as a sequence of visual events-remains underexplored. Intuitively, leveraging past events as memory can enrich contextual and temporal understanding of the current event. In this paper, we show that leveraging memories as contexts helps MLLMs better understand video events. However, because such memories rely on predictions of preceding events, they may contain misinformation, leading to confabulation and degraded performance. To address this, we propose a confabulation-aware memory modification method that mitigates confabulated memory for memory-enhanced event understanding.
Perceive, Query & Reason: Enhancing Video QA with Question-Guided Temporal Queries
Dec 26, 2024



Video Question Answering (Video QA) is a challenging video understanding task that requires models to comprehend entire videos, identify the most relevant information based on contextual cues from a given question, and reason accurately to provide answers. Recent advancements in Multimodal Large Language Models (MLLMs) have transformed video QA by leveraging their exceptional commonsense reasoning capabilities. This progress is largely driven by the effective alignment between visual data and the language space of MLLMs. However, for video QA, an additional space-time alignment poses a considerable challenge for extracting question-relevant information across frames. In this work, we investigate diverse temporal modeling techniques to integrate with MLLMs, aiming to achieve question-guided temporal modeling that leverages pre-trained visual and textual alignment in MLLMs. We propose T-Former, a novel temporal modeling method that creates a question-guided temporal bridge between frame-wise visual perception and the reasoning capabilities of LLMs. Our evaluation across multiple video QA benchmarks demonstrates that T-Former competes favorably with existing temporal modeling approaches and aligns with recent advancements in video QA.
FedBiP: Heterogeneous One-Shot Federated Learning with Personalized Latent Diffusion Models
Oct 07, 2024



One-Shot Federated Learning (OSFL), a special decentralized machine learning paradigm, has recently gained significant attention. OSFL requires only a single round of client data or model upload, which reduces communication costs and mitigates privacy threats compared to traditional FL. Despite these promising prospects, existing methods face challenges due to client data heterogeneity and limited data quantity when applied to real-world OSFL systems. Recently, Latent Diffusion Models (LDM) have shown remarkable advancements in synthesizing high-quality images through pretraining on large-scale datasets, thereby presenting a potential solution to overcome these issues. However, directly applying pretrained LDM to heterogeneous OSFL results in significant distribution shifts in synthetic data, leading to performance degradation in classification models trained on such data. This issue is particularly pronounced in rare domains, such as medical imaging, which are underrepresented in LDM's pretraining data. To address this challenge, we propose Federated Bi-Level Personalization (FedBiP), which personalizes the pretrained LDM at both instance-level and concept-level. Hereby, FedBiP synthesizes images following the client's local data distribution without compromising the privacy regulations. FedBiP is also the first approach to simultaneously address feature space heterogeneity and client data scarcity in OSFL. Our method is validated through extensive experiments on three OSFL benchmarks with feature space heterogeneity, as well as on challenging medical and satellite image datasets with label heterogeneity. The results demonstrate the effectiveness of FedBiP, which substantially outperforms other OSFL methods.
VideoINSTA: Zero-shot Long Video Understanding via Informative Spatial-Temporal Reasoning with LLMs
Sep 30, 2024



In the video-language domain, recent works in leveraging zero-shot Large Language Model-based reasoning for video understanding have become competitive challengers to previous end-to-end models. However, long video understanding presents unique challenges due to the complexity of reasoning over extended timespans, even for zero-shot LLM-based approaches. The challenge of information redundancy in long videos prompts the question of what specific information is essential for large language models (LLMs) and how to leverage them for complex spatial-temporal reasoning in long-form video analysis. We propose a framework VideoINSTA, i.e. INformative Spatial-TemporAl Reasoning for zero-shot long-form video understanding. VideoINSTA contributes (1) a zero-shot framework for long video understanding using LLMs; (2) an event-based temporal reasoning and content-based spatial reasoning approach for LLMs to reason over spatial-temporal information in videos; (3) a self-reflective information reasoning scheme balancing temporal factors based on information sufficiency and prediction confidence. Our model significantly improves the state-of-the-art on three long video question-answering benchmarks: EgoSchema, NextQA, and IntentQA, and the open question answering dataset ActivityNetQA. The code is released here: https://github.com/mayhugotong/VideoINSTA.
Multimodal Pragmatic Jailbreak on Text-to-image Models
Sep 27, 2024

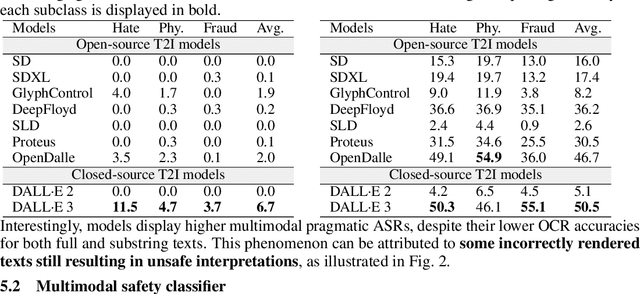

Diffusion models have recently achieved remarkable advancements in terms of image quality and fidelity to textual prompts. Concurrently, the safety of such generative models has become an area of growing concern. This work introduces a novel type of jailbreak, which triggers T2I models to generate the image with visual text, where the image and the text, although considered to be safe in isolation, combine to form unsafe content. To systematically explore this phenomenon, we propose a dataset to evaluate the current diffusion-based text-to-image (T2I) models under such jailbreak. We benchmark nine representative T2I models, including two close-source commercial models. Experimental results reveal a concerning tendency to produce unsafe content: all tested models suffer from such type of jailbreak, with rates of unsafe generation ranging from 8\% to 74\%. In real-world scenarios, various filters such as keyword blocklists, customized prompt filters, and NSFW image filters, are commonly employed to mitigate these risks. We evaluate the effectiveness of such filters against our jailbreak and found that, while current classifiers may be effective for single modality detection, they fail to work against our jailbreak. Our work provides a foundation for further development towards more secure and reliable T2I models.
Localizing Events in Videos with Multimodal Queries
Jun 14, 2024



Video understanding is a pivotal task in the digital era, yet the dynamic and multievent nature of videos makes them labor-intensive and computationally demanding to process. Thus, localizing a specific event given a semantic query has gained importance in both user-oriented applications like video search and academic research into video foundation models. A significant limitation in current research is that semantic queries are typically in natural language that depicts the semantics of the target event. This setting overlooks the potential for multimodal semantic queries composed of images and texts. To address this gap, we introduce a new benchmark, ICQ, for localizing events in videos with multimodal queries, along with a new evaluation dataset ICQ-Highlight. Our new benchmark aims to evaluate how well models can localize an event given a multimodal semantic query that consists of a reference image, which depicts the event, and a refinement text to adjust the images' semantics. To systematically benchmark model performance, we include 4 styles of reference images and 5 types of refinement texts, allowing us to explore model performance across different domains. We propose 3 adaptation methods that tailor existing models to our new setting and evaluate 10 SOTA models, ranging from specialized to large-scale foundation models. We believe this benchmark is an initial step toward investigating multimodal queries in video event localization.
SPOT! Revisiting Video-Language Models for Event Understanding
Dec 01, 2023
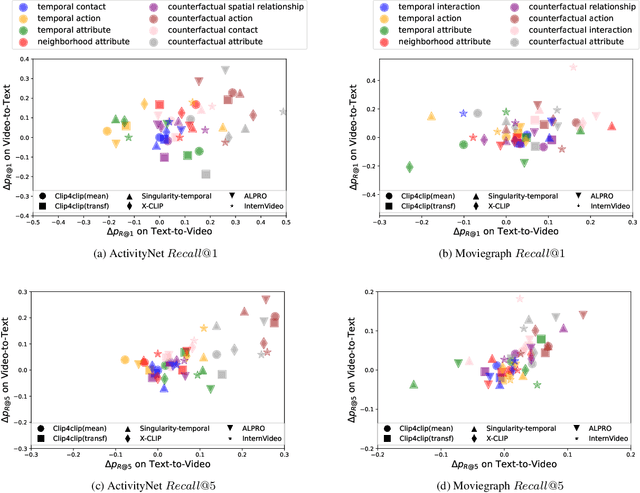


Understanding videos is an important research topic for multimodal learning. Leveraging large-scale datasets of web-crawled video-text pairs as weak supervision has become a pre-training paradigm for learning joint representations and showcased remarkable potential in video understanding tasks. However, videos can be multi-event and multi-grained, while these video-text pairs usually contain only broad-level video captions. This raises a question: with such weak supervision, can video representation in video-language models gain the ability to distinguish even factual discrepancies in textual description and understand fine-grained events? To address this, we introduce SPOT Prober, to benchmark existing video-language models's capacities of distinguishing event-level discrepancies as an indicator of models' event understanding ability. Our approach involves extracting events as tuples (<Subject, Predicate, Object, Attribute, Timestamps>) from videos and generating false event tuples by manipulating tuple components systematically. We reevaluate the existing video-language models with these positive and negative captions and find they fail to distinguish most of the manipulated events. Based on our findings, we propose to plug in these manipulated event captions as hard negative samples and find them effective in enhancing models for event understanding.
Multi-event Video-Text Retrieval
Aug 22, 2023



Video-Text Retrieval (VTR) is a crucial multi-modal task in an era of massive video-text data on the Internet. A plethora of work characterized by using a two-stream Vision-Language model architecture that learns a joint representation of video-text pairs has become a prominent approach for the VTR task. However, these models operate under the assumption of bijective video-text correspondences and neglect a more practical scenario where video content usually encompasses multiple events, while texts like user queries or webpage metadata tend to be specific and correspond to single events. This establishes a gap between the previous training objective and real-world applications, leading to the potential performance degradation of earlier models during inference. In this study, we introduce the Multi-event Video-Text Retrieval (MeVTR) task, addressing scenarios in which each video contains multiple different events, as a niche scenario of the conventional Video-Text Retrieval Task. We present a simple model, Me-Retriever, which incorporates key event video representation and a new MeVTR loss for the MeVTR task. Comprehensive experiments show that this straightforward framework outperforms other models in the Video-to-Text and Text-to-Video tasks, effectively establishing a robust baseline for the MeVTR task. We believe this work serves as a strong foundation for future studies. Code is available at https://github.com/gengyuanmax/MeVTR.
A Systematic Survey of Prompt Engineering on Vision-Language Foundation Models
Jul 24, 2023Prompt engineering is a technique that involves augmenting a large pre-trained model with task-specific hints, known as prompts, to adapt the model to new tasks. Prompts can be created manually as natural language instructions or generated automatically as either natural language instructions or vector representations. Prompt engineering enables the ability to perform predictions based solely on prompts without updating model parameters, and the easier application of large pre-trained models in real-world tasks. In past years, Prompt engineering has been well-studied in natural language processing. Recently, it has also been intensively studied in vision-language modeling. However, there is currently a lack of a systematic overview of prompt engineering on pre-trained vision-language models. This paper aims to provide a comprehensive survey of cutting-edge research in prompt engineering on three types of vision-language models: multimodal-to-text generation models (e.g. Flamingo), image-text matching models (e.g. CLIP), and text-to-image generation models (e.g. Stable Diffusion). For each type of model, a brief model summary, prompting methods, prompting-based applications, and the corresponding responsibility and integrity issues are summarized and discussed. Furthermore, the commonalities and differences between prompting on vision-language models, language models, and vision models are also discussed. The challenges, future directions, and research opportunities are summarized to foster future research on this topic.