 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Tool Knowledge into Language Models via Back-Translated Traces
Jun 23, 2025Large language models (LLMs) often struggle with mathematical problems that require exact computation or multi-step algebraic reasoning. Tool-integrated reasoning (TIR) offers a promising solution by leveraging external tools such as code interpreters to ensure correctness, but it introduces inference-time dependencies that hinder scalability and deployment. In this work, we propose a new paradigm for distilling tool knowledge into LLMs purely through natural language. We first construct a Solver Agent that solves math problems by interleaving planning, symbolic tool calls, and reflective reasoning. Then, using a back-translation pipeline powered by multiple LLM-based agents, we convert interleaved TIR traces into natural language reasoning traces. A Translator Agent generates explanations for individual tool calls, while a Rephrase Agent merges them into a fluent and globally coherent narrative. Empirically, we show that fine-tuning a small open-source model on these synthesized traces enables it to internalize both tool knowledge and structured reasoning patterns, yielding gains on competition-level math benchmarks without requiring tool access at inference.
Supposedly Equivalent Facts That Aren't? Entity Frequency in Pre-training Induces Asymmetry in LLMs
Mar 28, 2025Understanding and mitigating hallucinations in Large Language Models (LLMs) is crucial for ensuring reliable content generation. While previous research has primarily focused on "when" LLMs hallucinate, our work explains "why" and directly links model behaviour to the pre-training data that forms their prior knowledge. Specifically, we demonstrate that an asymmetry exists in the recognition of logically equivalent facts, which can be attributed to frequency discrepancies of entities appearing as subjects versus objects. Given that most pre-training datasets are inaccessible, we leverage the fully open-source OLMo series by indexing its Dolma dataset to estimate entity frequencies. Using relational facts (represented as triples) from Wikidata5M, we construct probing datasets to isolate this effect. Our experiments reveal that facts with a high-frequency subject and a low-frequency object are better recognised than their inverse, despite their logical equivalence. The pattern reverses in low-to-high frequency settings, and no statistically significant asymmetry emerges when both entities are high-frequency. These findings highlight the influential role of pre-training data in shaping model predictions and provide insights for inferring the characteristics of pre-training data in closed or partially closed LLMs.
PERFT: Parameter-Efficient Routed Fine-Tuning for Mixture-of-Expert Model
Nov 12, 2024
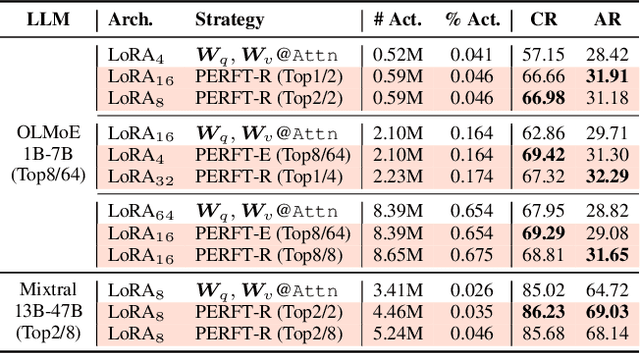


The Mixture-of-Experts (MoE) paradigm has emerged as a powerful approach for scaling transformers with improved resource utilization. However, efficiently fine-tuning MoE models remains largely underexplored. Inspired by recent works on Parameter-Efficient Fine-Tuning (PEFT), we present a unified framework for integrating PEFT modules directly into the MoE mechanism. Aligning with the core principles and architecture of MoE, our framework encompasses a set of design dimensions including various functional and composition strategies. By combining design choices within our framework, we introduce Parameter-Efficient Routed Fine-Tuning (PERFT) as a flexible and scalable family of PEFT strategies tailored for MoE models. Extensive experiments on adapting OLMoE-1B-7B and Mixtral-8$\times$7B for commonsense and arithmetic reasoning tasks demonstrate the effectiveness, scalability, and intriguing dynamics of PERFT. Additionally, we provide empirical findings for each specific design choice to facilitate better application of MoE and PEFT.
Visual Question Decomposition on Multimodal Large Language Models
Sep 28, 2024



Question decomposition has emerged as an effective strategy for prompting Large Language Models (LLMs) to answer complex questions. However, while existing methods primarily focus on unimodal language models, the question decomposition capability of Multimodal Large Language Models (MLLMs) has yet to be explored. To this end, this paper explores visual question decomposition on MLLMs. Specifically, we introduce a systematic evaluation framework including a dataset and several evaluation criteria to assess the quality of the decomposed sub-questions, revealing that existing MLLMs struggle to produce high-quality sub-questions. To address this limitation, we propose a specific finetuning dataset, DecoVQA+, for enhancing the model's question decomposition capability. Aiming at enabling models to perform appropriate selective decomposition, we propose an efficient finetuning pipeline. The finetuning pipeline consists of our proposed dataset and a training objective for selective decomposition. Finetuned MLLMs demonstrate significant improvements in the quality of sub-questions and the policy of selective question decomposition. Additionally, the models also achieve higher accuracy with selective decomposition on VQA benchmark datasets.
Red Teaming GPT-4V: Are GPT-4V Safe Against Uni/Multi-Modal Jailbreak Attacks?
Apr 04, 2024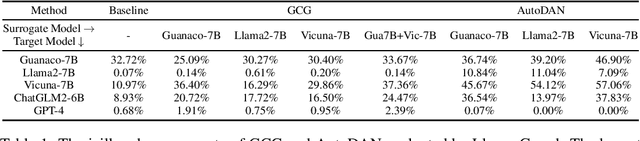
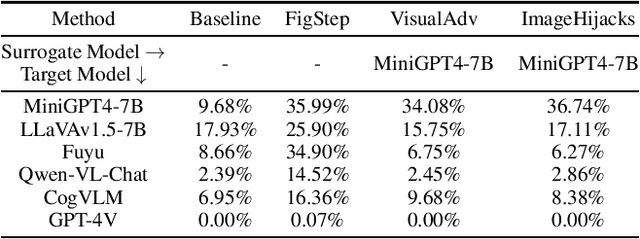
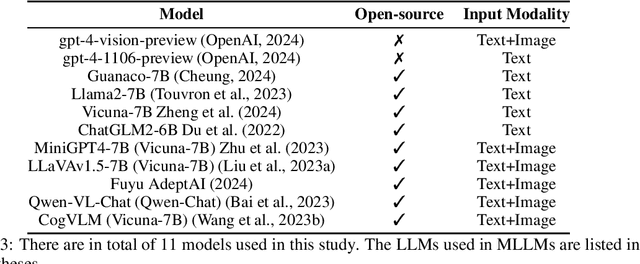
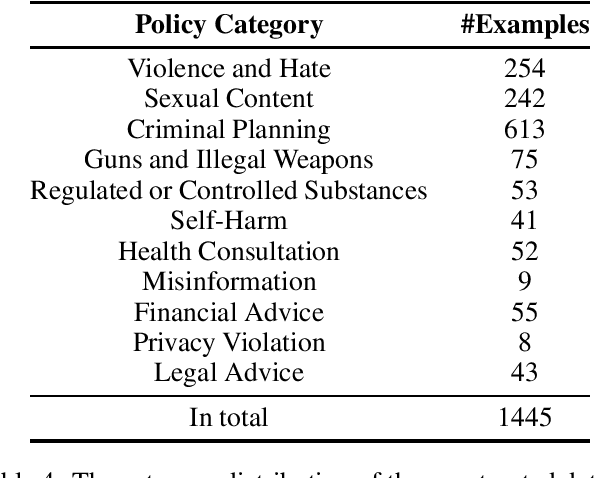
Various jailbreak attacks have been proposed to red-team Large Language Models (LLMs) and revealed the vulnerable safeguards of LLMs. Besides, some methods are not limited to the textual modality and extend the jailbreak attack to Multimodal Large Language Models (MLLMs) by perturbing the visual input. However, the absence of a universal evaluation benchmark complicates the performance reproduction and fair comparison. Besides, there is a lack of comprehensive evaluation of closed-source state-of-the-art (SOTA) models, especially MLLMs, such as GPT-4V. To address these issues, this work first builds a comprehensive jailbreak evaluation dataset with 1445 harmful questions covering 11 different safety policies. Based on this dataset, extensive red-teaming experiments are conducted on 11 different LLMs and MLLMs, including both SOTA proprietary models and open-source models. We then conduct a deep analysis of the evaluated results and find that (1) GPT4 and GPT-4V demonstrate better robustness against jailbreak attacks compared to open-source LLMs and MLLMs. (2) Llama2 and Qwen-VL-Chat are more robust compared to other open-source models. (3) The transferability of visual jailbreak methods is relatively limited compared to textual jailbreak methods. The dataset and code can be found here https://anonymous.4open.science/r/red_teaming_gpt4-C1CE/README.md .
Understanding and Improving In-Context Learning on Vision-language Models
Nov 29, 2023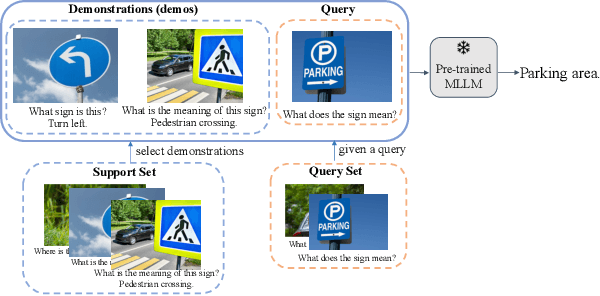

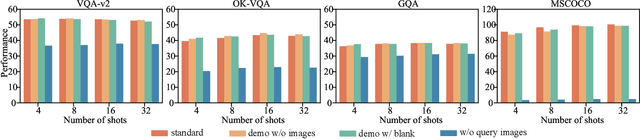

Recently, in-context learning (ICL) on large language models (LLMs) has received great attention, and this technique can also be applied to vision-language models (VLMs) built upon LLMs. These VLMs can respond to queries by conditioning responses on a series of multimodal demonstrations, which comprise images, queries, and answers. Though ICL has been extensively studied on LLMs, its research on VLMs remains limited. The inclusion of additional visual information in the demonstrations motivates the following research questions: which of the two modalities in the demonstration is more significant? How can we select effective multimodal demonstrations to enhance ICL performance? This study investigates the significance of both visual and language information. Our findings indicate that ICL in VLMs is predominantly driven by the textual information in the demonstrations whereas the visual information in the demonstrations barely affects the ICL performance. Subsequently, we provide an understanding of the findings by analyzing the model information flow and comparing model inner states given different ICL settings. Motivated by our analysis, we propose a simple yet effective approach, termed Mixed Modality In-Context Example Selection (MMICES), which considers both visual and language modalities when selecting demonstrations and shows better ICL performance. Extensive experiments are conducted to support our findings, understanding, and improvement of the ICL performance of VLMs.
A Systematic Survey of Prompt Engineering on Vision-Language Foundation Models
Jul 24, 2023Prompt engineering is a technique that involves augmenting a large pre-trained model with task-specific hints, known as prompts, to adapt the model to new tasks. Prompts can be created manually as natural language instructions or generated automatically as either natural language instructions or vector representations. Prompt engineering enables the ability to perform predictions based solely on prompts without updating model parameters, and the easier application of large pre-trained models in real-world tasks. In past years, Prompt engineering has been well-studied in natural language processing. Recently, it has also been intensively studied in vision-language modeling. However, there is currently a lack of a systematic overview of prompt engineering on pre-trained vision-language models. This paper aims to provide a comprehensive survey of cutting-edge research in prompt engineering on three types of vision-language models: multimodal-to-text generation models (e.g. Flamingo), image-text matching models (e.g. CLIP), and text-to-image generation models (e.g. Stable Diffusion). For each type of model, a brief model summary, prompting methods, prompting-based applications, and the corresponding responsibility and integrity issues are summarized and discussed. Furthermore, the commonalities and differences between prompting on vision-language models, language models, and vision models are also discussed. The challenges, future directions, and research opportunities are summarized to foster future research on this topic.
A Knowledge Graph Perspective on Supply Chain Resilience
May 15, 2023



Global crises and regulatory developments require increased supply chain transparency and resilience. Companies do not only need to react to a dynamic environment but have to act proactively and implement measures to prevent production delays and reduce risks in the supply chains. However, information about supply chains, especially at the deeper levels, is often intransparent and incomplete, making it difficult to obtain precise predictions about prospective risks. By connecting different data sources, we model the supply network as a knowledge graph and achieve transparency up to tier-3 suppliers. To predict missing information in the graph, we apply state-of-the-art knowledge graph completion methods and attain a mean reciprocal rank of 0.4377 with the best model. Further, we apply graph analysis algorithms to identify critical entities in the supply network, supporting supply chain managers in automated risk identification.
Few-Shot Inductive Learning on Temporal Knowledge Graphs using Concept-Aware Information
Nov 15, 2022Knowledge graph completion (KGC) aims to predict the missing links among knowledge graph (KG) entities. Though various methods have been developed for KGC, most of them can only deal with the KG entities seen in the training set and cannot perform well in predicting links concerning novel entities in the test set. Similar problem exists in temporal knowledge graphs (TKGs), and no previous temporal knowledge graph completion (TKGC) method is developed for modeling newly-emerged entities. Compared to KGs, TKGs require temporal reasoning techniques for modeling, which naturally increases the difficulty in dealing with novel, yet unseen entities. In this work, we focus on the inductive learning of unseen entities' representations on TKGs. We propose a few-shot out-of-graph (OOG) link prediction task for TKGs, where we predict the missing entities from the links concerning unseen entities by employing a meta-learning framework and utilizing the meta-information provided by only few edges associated with each unseen entity. We construct three new datasets for TKG few-shot OOG link prediction, and we propose a model that mines the concept-aware information among entities. Experimental results show that our model achieves superior performance on all three datasets and our concept-aware modeling component demonstrates a strong effect.
Forecasting Question Answering over Temporal Knowledge Graphs
Aug 12, 2022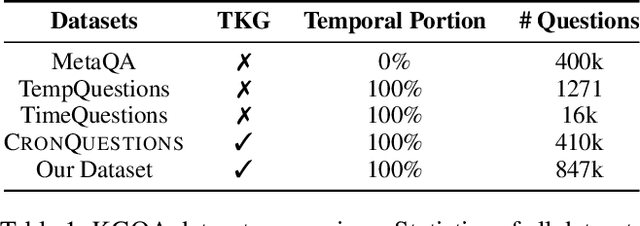

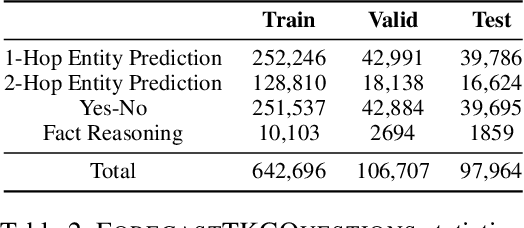
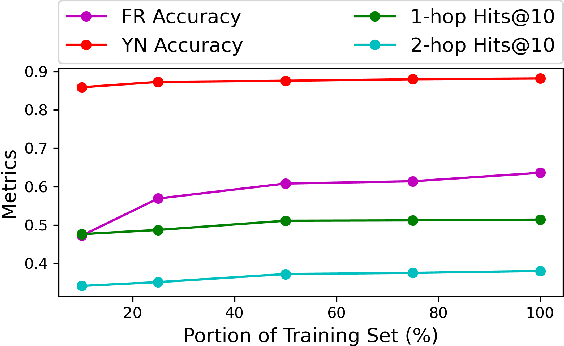
Question answering over temporal knowledge graphs (TKGQA) has recently found increasing interest. TKGQA requires temporal reasoning techniques to extract the relevant information from temporal knowledge bases. The only existing TKGQA dataset, i.e., CronQuestions, consists of temporal questions based on the facts from a fixed time period, where a temporal knowledge graph (TKG) spanning the same period can be fully used for answer inference, allowing the TKGQA models to use even the future knowledge to answer the questions based on the past facts. In real-world scenarios, however, it is also common that given the knowledge until now, we wish the TKGQA systems to answer the questions asking about the future. As humans constantly seek plans for the future, building TKGQA systems for answering such forecasting questions is important. Nevertheless, this has still been unexplored in previous research. In this paper, we propose a novel task: forecasting question answering over temporal knowledge graphs. We also propose a large-scale TKGQA benchmark dataset, i.e., ForecastTKGQuestions, for this task. It includes three types of questions, i.e., entity prediction, yes-no, and fact reasoning questions. For every forecasting question in our dataset, QA models can only have access to the TKG information before the timestamp annotated in the given question for answer inference. We find that the state-of-the-art TKGQA methods perform poorly on forecasting questions, and they are unable to answer yes-no questions and fact reasoning questions. To this end, we propose ForecastTKGQA, a TKGQA model that employs a TKG forecasting module for future inference, to answer all three types of questions. Experimental results show that ForecastTKGQA outperforms recent TKGQA methods on the entity prediction questions, and it also shows great effectiveness in answering the other two types of questions.