 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Improving In-Context Learning on Vision-language Models
Nov 29, 2023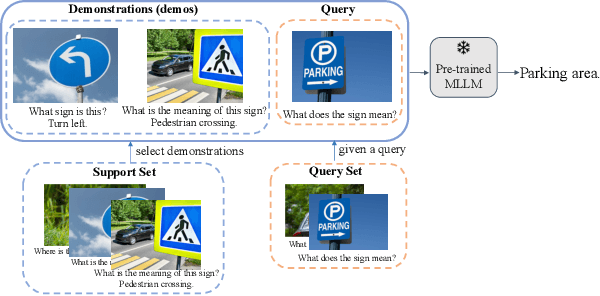

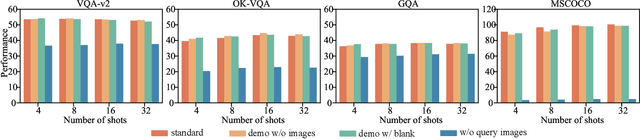

Recently, in-context learning (ICL) on large language models (LLMs) has received great attention, and this technique can also be applied to vision-language models (VLMs) built upon LLMs. These VLMs can respond to queries by conditioning responses on a series of multimodal demonstrations, which comprise images, queries, and answers. Though ICL has been extensively studied on LLMs, its research on VLMs remains limited. The inclusion of additional visual information in the demonstrations motivates the following research questions: which of the two modalities in the demonstration is more significant? How can we select effective multimodal demonstrations to enhance ICL performance? This study investigates the significance of both visual and language information. Our findings indicate that ICL in VLMs is predominantly driven by the textual information in the demonstrations whereas the visual information in the demonstrations barely affects the ICL performance. Subsequently, we provide an understanding of the findings by analyzing the model information flow and comparing model inner states given different ICL settings. Motivated by our analysis, we propose a simple yet effective approach, termed Mixed Modality In-Context Example Selection (MMICES), which considers both visual and language modalities when selecting demonstrations and shows better ICL performance. Extensive experiments are conducted to support our findings, understanding, and improvement of the ICL performance of VLMs.
Named Entity Recognition in Industrial Tables using Tabular Language Models
Sep 29, 2022

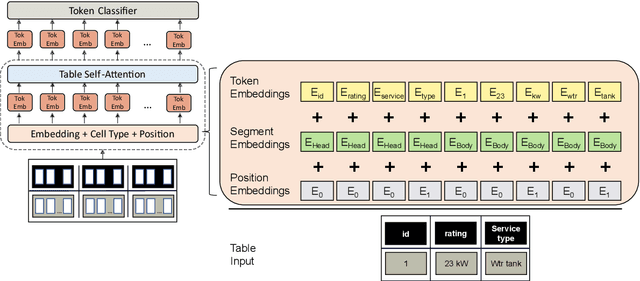
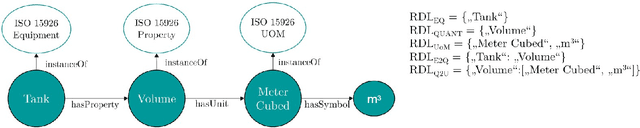
Specialized transformer-based models for encoding tabular data have gained interest in academia. Although tabular data is omnipresent in industry, applications of table transformers are still missing. In this paper, we study how these models can be applied to an industrial Named Entity Recognition (NER) problem where the entities are mentioned in tabular-structured spreadsheets. The highly technical nature of spreadsheets as well as the lack of labeled data present major challenges for fine-tuning transformer-based models. Therefore, we develop a dedicated table data augmentation strategy based on available domain-specific knowledge graphs. We show that this boosts performance in our low-resource scenario considerably. Further, we investigate the benefits of tabular structure as inductive bias compared to tables as linearized sequences. Our experiments confirm that a table transformer outperforms other baselines and that its tabular inductive bias is vital for convergence of transformer-based models.
Linguistically Informed Masking for Representation Learning in the Patent Domain
Jun 10, 2021
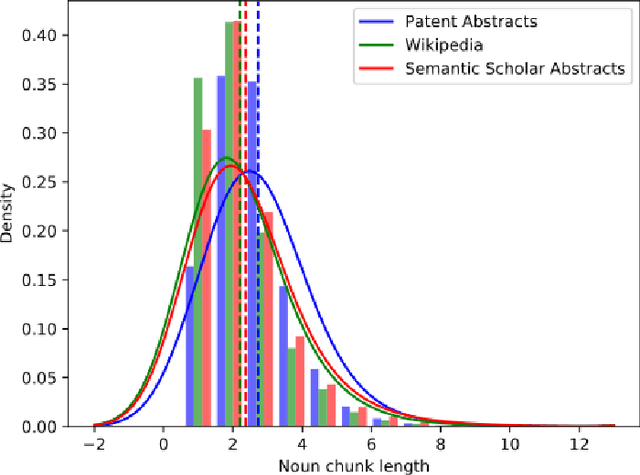

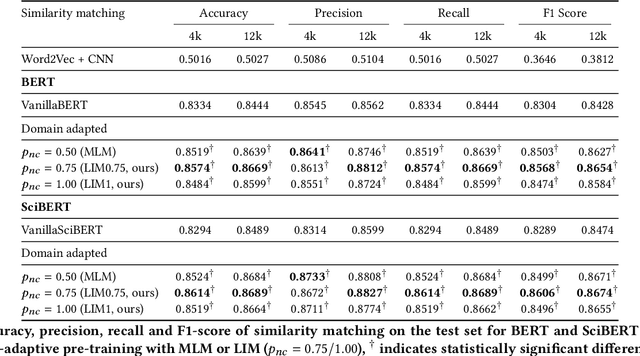
Domain-specific contextualized language models have demonstrated substantial effectiveness gains for domain-specific downstream tasks, like similarity matching, entity recognition or information retrieval. However successfully applying such models in highly specific language domains requires domain adaptation of the pre-trained models. In this paper we propose the empirically motivated Linguistically Informed Masking (LIM) method to focus domain-adaptative pre-training on the linguistic patterns of patents, which use a highly technical sublanguage. We quantify the relevant differences between patent, scientific and general-purpose language and demonstrate for two different language models (BERT and SciBERT) that domain adaptation with LIM leads to systematically improved representations by evaluating the performance of the domain-adapted representations of patent language on two independent downstream tasks, the IPC classification and similarity matching. We demonstrate the impact of balancing the learning from different information sources during domain adaptation for the patent domain. We make the source code as well as the domain-adaptive pre-trained patent language models publicly available at https://github.com/sophiaalthammer/patent-lim.
News Article Teaser Tweets and How to Generate Them
Jul 30, 2018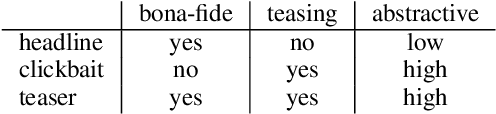

We define the task of teaser generation and provide an evaluation benchmark and baseline systems for it. A teaser is a short reading suggestion for an article that is illustrative and includes curiosity-arousing elements to entice potential readers to read the news item. Teasers are one of the main vehicles for transmitting news to social media users. We compile a novel dataset of teasers by systematically accumulating tweets and selecting ones that conform to the teaser definition. We compare a number of neural abstractive architectures on the task of teaser generation and the overall best performing system is See et al.(2017)'s seq2seq with pointer network.