 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Rank-without-GPT: Building GPT-Independent Listwise Rerankers on Open-Source Large Language Models
Dec 05, 2023



Listwise rerankers based on large language models (LLM) are the zero-shot state-of-the-art. However, current works in this direction all depend on the GPT models, making it a single point of failure in scientific reproducibility. Moreover, it raises the concern that the current research findings only hold for GPT models but not LLM in general. In this work, we lift this pre-condition and build for the first time effective listwise rerankers without any form of dependency on GPT. Our passage retrieval experiments show that our best list se reranker surpasses the listwise rerankers based on GPT-3.5 by 13% and achieves 97% effectiveness of the ones built on GPT-4. Our results also show that the existing training datasets, which were expressly constructed for pointwise ranking, are insufficient for building such listwise rerankers. Instead, high-quality listwise ranking data is required and crucial, calling for further work on building human-annotated listwise data resources.
Annotating Data for Fine-Tuning a Neural Ranker? Current Active Learning Strategies are not Better than Random Selection
Sep 12, 2023Search methods based on Pretrained Language Models (PLM) have demonstrated great effectiveness gains compared to statistical and early neural ranking models. However, fine-tuning PLM-based rankers requires a great amount of annotated training data. Annotating data involves a large manual effort and thus is expensive, especially in domain specific tasks. In this paper we investigate fine-tuning PLM-based rankers under limited training data and budget. We investigate two scenarios: fine-tuning a ranker from scratch, and domain adaptation starting with a ranker already fine-tuned on general data, and continuing fine-tuning on a target dataset. We observe a great variability in effectiveness when fine-tuning on different randomly selected subsets of training data. This suggests that it is possible to achieve effectiveness gains by actively selecting a subset of the training data that has the most positive effect on the rankers. This way, it would be possible to fine-tune effective PLM rankers at a reduced annotation budget. To investigate this, we adapt existing Active Learning (AL) strategies to the task of fine-tuning PLM rankers and investigate their effectiveness, also considering annotation and computational costs. Our extensive analysis shows that AL strategies do not significantly outperform random selection of training subsets in terms of effectiveness. We further find that gains provided by AL strategies come at the expense of more assessments (thus higher annotation costs) and AL strategies underperform random selection when comparing effectiveness given a fixed annotation cost. Our results highlight that ``optimal'' subsets of training data that provide high effectiveness at low annotation cost do exist, but current mainstream AL strategies applied to PLM rankers are not capable of identifying them.
Ranger: A Toolkit for Effect-Size Based Multi-Task Evaluation
May 24, 2023


In this paper, we introduce Ranger - a toolkit to facilitate the easy use of effect-size-based meta-analysis for multi-task evaluation in NLP and IR. We observed that our communities often face the challenge of aggregating results over incomparable metrics and scenarios, which makes conclusions and take-away messages less reliable. With Ranger, we aim to address this issue by providing a task-agnostic toolkit that combines the effect of a treatment on multiple tasks into one statistical evaluation, allowing for comparison of metrics and computation of an overall summary effect. Our toolkit produces publication-ready forest plots that enable clear communication of evaluation results over multiple tasks. Our goal with the ready-to-use Ranger toolkit is to promote robust, effect-size-based evaluation and improve evaluation standards in the community. We provide two case studies for common IR and NLP settings to highlight Ranger's benefits.
FiD-Light: Efficient and Effective Retrieval-Augmented Text Generation
Sep 28, 2022



Retrieval-augmented generation models offer many benefits over standalone language models: besides a textual answer to a given query they provide provenance items retrieved from an updateable knowledge base. However, they are also more complex systems and need to handle long inputs. In this work, we introduce FiD-Light to strongly increase the efficiency of the state-of-the-art retrieval-augmented FiD model, while maintaining the same level of effectiveness. Our FiD-Light model constrains the information flow from the encoder (which encodes passages separately) to the decoder (using concatenated encoded representations). Furthermore, we adapt FiD-Light with re-ranking capabilities through textual source pointers, to improve the top-ranked provenance precision. Our experiments on a diverse set of seven knowledge intensive tasks (KILT) show FiD-Light consistently improves the Pareto frontier between query latency and effectiveness. FiD-Light with source pointing sets substantial new state-of-the-art results on six KILT tasks for combined text generation and provenance retrieval evaluation, while maintaining reasonable efficiency.
TripJudge: A Relevance Judgement Test Collection for TripClick Health Retrieval
Aug 14, 2022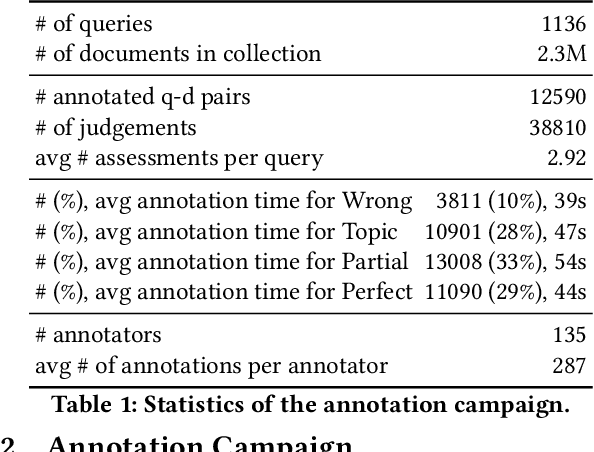
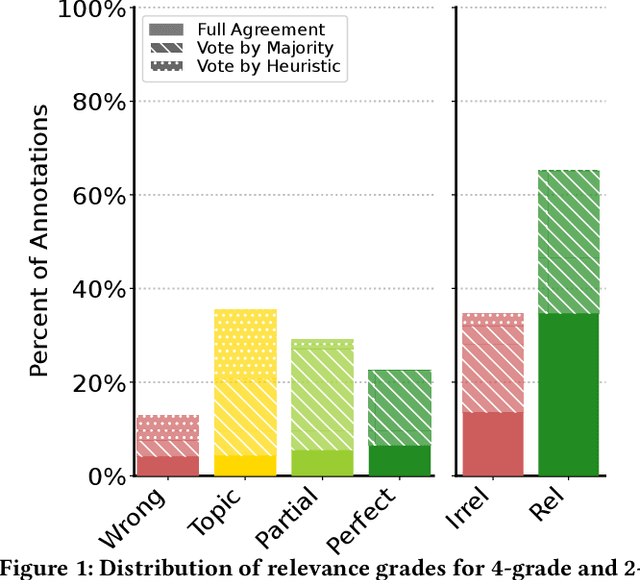
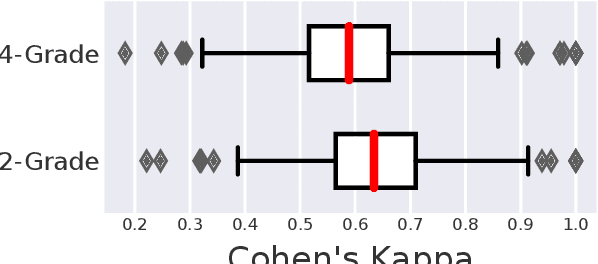
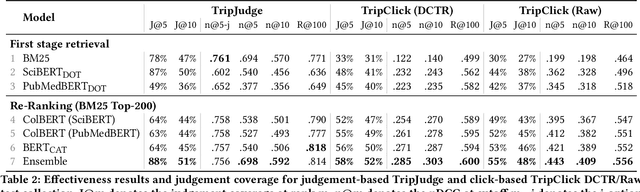
Robust test collections are crucial for Information Retrieval research. Recently there is a growing interest in evaluating retrieval systems for domain-specific retrieval tasks, however these tasks often lack a reliable test collection with human-annotated relevance assessments following the Cranfield paradigm. In the medical domain, the TripClick collection was recently proposed, which contains click log data from the Trip search engine and includes two click-based test sets. However the clicks are biased to the retrieval model used, which remains unknown, and a previous study shows that the test sets have a low judgement coverage for the Top-10 results of lexical and neural retrieval models. In this paper we present the novel, relevance judgement test collection TripJudge for TripClick health retrieval. We collect relevance judgements in an annotation campaign and ensure the quality and reusability of TripJudge by a variety of ranking methods for pool creation, by multiple judgements per query-document pair and by an at least moderate inter-annotator agreement. We compare system evaluation with TripJudge and TripClick and find that that click and judgement-based evaluation can lead to substantially different system rankings.
Multi-Task Retrieval-Augmented Text Generation with Relevance Sampling
Jul 07, 2022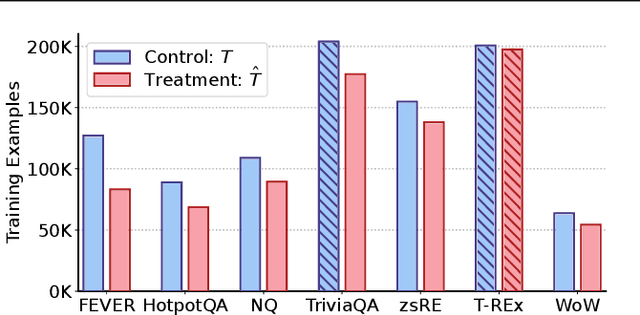

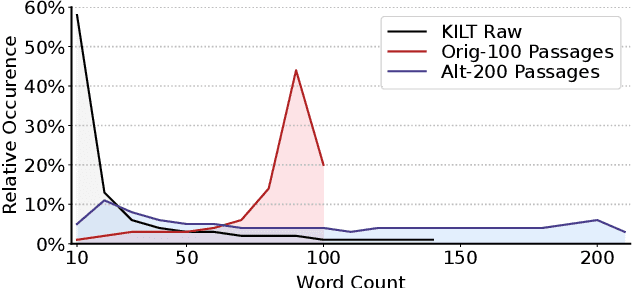

This paper studies multi-task training of retrieval-augmented generation models for knowledge-intensive tasks. We propose to clean the training set by utilizing a distinct property of knowledge-intensive generation: The connection of query-answer pairs to items in the knowledge base. We filter training examples via a threshold of confidence on the relevance labels, whether a pair is answerable by the knowledge base or not. We train a single Fusion-in-Decoder (FiD) generator on seven combined tasks of the KILT benchmark. The experimental results suggest that our simple yet effective approach substantially improves competitive baselines on two strongly imbalanced tasks; and shows either smaller improvements or no significant regression on the remaining tasks. Furthermore, we demonstrate our multi-task training with relevance label sampling scales well with increased model capacity and achieves state-of-the-art results in five out of seven KILT tasks.
Are We There Yet? A Decision Framework for Replacing Term Based Retrieval with Dense Retrieval Systems
Jun 26, 2022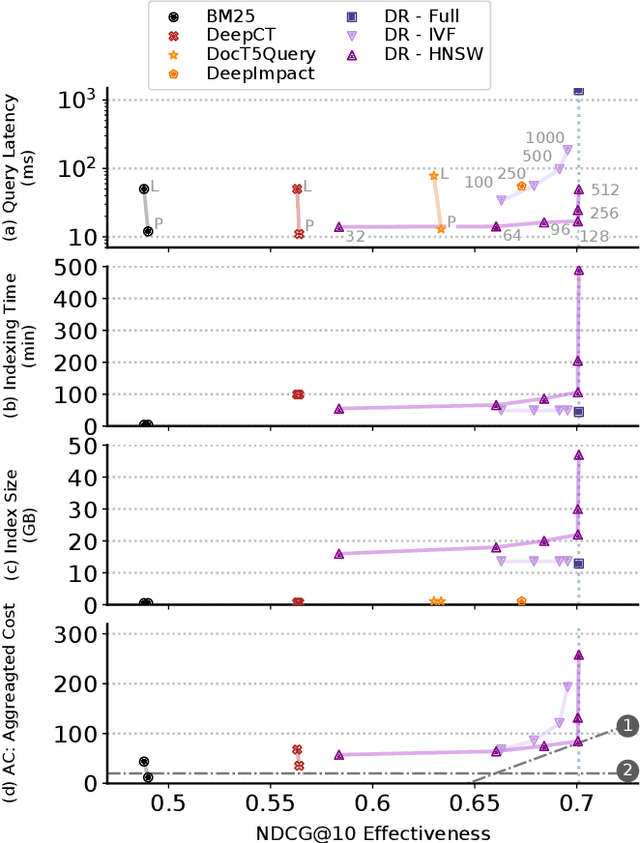
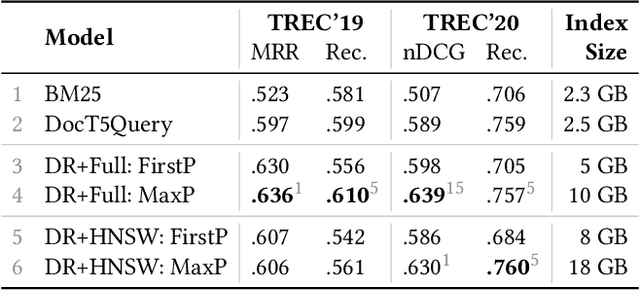

Recently, several dense retrieval (DR) models have demonstrated competitive performance to term-based retrieval that are ubiquitous in search systems. In contrast to term-based matching, DR projects queries and documents into a dense vector space and retrieves results via (approximate) nearest neighbor search. Deploying a new system, such as DR, inevitably involves tradeoffs in aspects of its performance. Established retrieval systems running at scale are usually well understood in terms of effectiveness and costs, such as query latency, indexing throughput, or storage requirements. In this work, we propose a framework with a set of criteria that go beyond simple effectiveness measures to thoroughly compare two retrieval systems with the explicit goal of assessing the readiness of one system to replace the other. This includes careful tradeoff considerations between effectiveness and various cost factors. Furthermore, we describe guardrail criteria, since even a system that is better on average may have systematic failures on a minority of queries. The guardrails check for failures on certain query characteristics and novel failure types that are only possible in dense retrieval systems. We demonstrate our decision framework on a Web ranking scenario. In that scenario, state-of-the-art DR models have surprisingly strong results, not only on average performance but passing an extensive set of guardrail tests, showing robustness on different query characteristics, lexical matching, generalization, and number of regressions. It is impossible to predict whether DR will become ubiquitous in the future, but one way this is possible is through repeated applications of decision processes such as the one presented here.
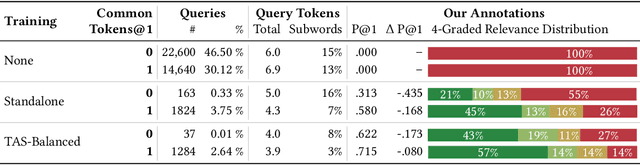
Introducing Neural Bag of Whole-Words with ColBERTer: Contextualized Late Interactions using Enhanced Reduction
Mar 24, 2022
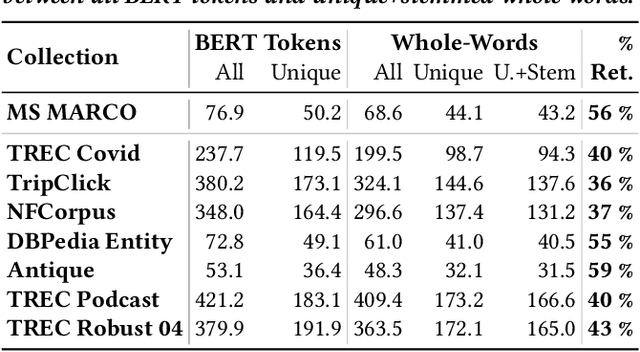
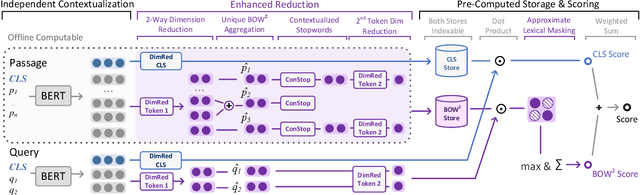
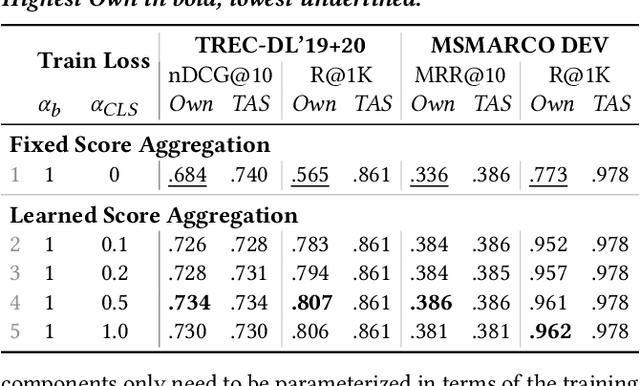
Recent progress in neural information retrieval has demonstrated large gains in effectiveness, while often sacrificing the efficiency and interpretability of the neural model compared to classical approaches. This paper proposes ColBERTer, a neural retrieval model using contextualized late interaction (ColBERT) with enhanced reduction. Along the effectiveness Pareto frontier, ColBERTer's reductions dramatically lower ColBERT's storage requirements while simultaneously improving the interpretability of its token-matching scores. To this end, ColBERTer fuses single-vector retrieval, multi-vector refinement, and optional lexical matching components into one model. For its multi-vector component, ColBERTer reduces the number of stored vectors per document by learning unique whole-word representations for the terms in each document and learning to identify and remove word representations that are not essential to effective scoring. We employ an explicit multi-task, multi-stage training to facilitate using very small vector dimensions. Results on the MS MARCO and TREC-DL collection show that ColBERTer can reduce the storage footprint by up to 2.5x, while maintaining effectiveness. With just one dimension per token in its smallest setting, ColBERTer achieves index storage parity with the plaintext size, with very strong effectiveness results. Finally, we demonstrate ColBERTer's robustness on seven high-quality out-of-domain collections, yielding statistically significant gains over traditional retrieval baselines.
PARM: A Paragraph Aggregation Retrieval Model for Dense Document-to-Document Retrieval
Jan 05, 2022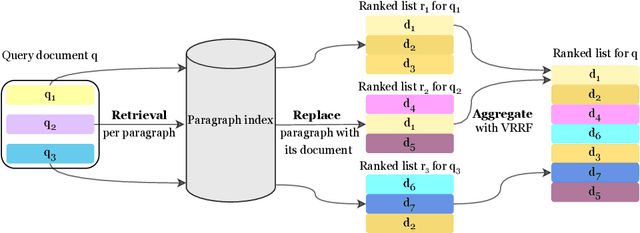
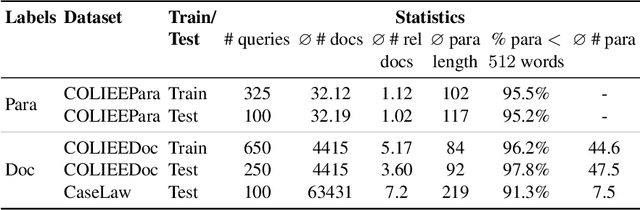
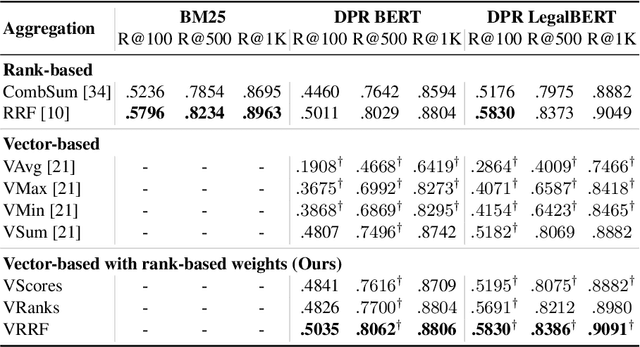
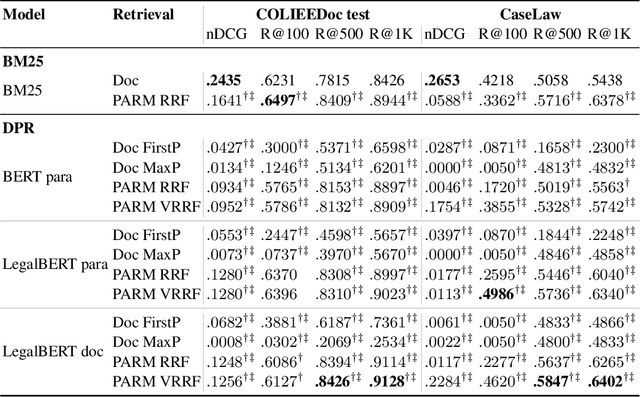
Dense passage retrieval (DPR) models show great effectiveness gains in first stage retrieval for the web domain. However in the web domain we are in a setting with large amounts of training data and a query-to-passage or a query-to-document retrieval task. We investigate in this paper dense document-to-document retrieval with limited labelled target data for training, in particular legal case retrieval. In order to use DPR models for document-to-document retrieval, we propose a Paragraph Aggregation Retrieval Model (PARM) which liberates DPR models from their limited input length. PARM retrieves documents on the paragraph-level: for each query paragraph, relevant documents are retrieved based on their paragraphs. Then the relevant results per query paragraph are aggregated into one ranked list for the whole query document. For the aggregation we propose vector-based aggregation with reciprocal rank fusion (VRRF) weighting, which combines the advantages of rank-based aggregation and topical aggregation based on the dense embeddings. Experimental results show that VRRF outperforms rank-based aggregation strategies for dense document-to-document retrieval with PARM. We compare PARM to document-level retrieval and demonstrate higher retrieval effectiveness of PARM for lexical and dense first-stage retrieval on two different legal case retrieval collections. We investigate how to train the dense retrieval model for PARM on limited target data with labels on the paragraph or the document-level. In addition, we analyze the differences of the retrieved results of lexical and dense retrieval with PARM.