 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanisms of Misgeneralization in Physical Sequence Modeling
May 19, 2026Generative sequence models are often trained to plan motion in physical domains, from robotics to mechanical simulations. When constructing a dataset to train such a model, engineers may curate demonstrations to specify how trajectories should be distributed over a physical quantity like travel distance or mechanical energy. For example, a roboticist building a maze navigation agent might choose demonstrations whose travel distances cover a fixed range uniformly, hoping to constrain the agent's expected power usage. We find that standard deep learning can violate this intent: each generated trajectory can seem plausible on its own, but the aggregate distribution over the physical quantity is wrong. We call this failure physical misgeneralization, and develop an account of its mechanism. Using controlled synthetic tasks, we show that physical misgeneralization arises when local errors typical of the model class propagate through the physical measurement to shift the recovered distribution. We estimate these errors with a data deviation kernel, and we use it to predict which physical quantities gain or lose mass in both our synthetic and more applied maze navigation and double-pendulum motion tasks. Finally, our mechanistic interpretation helps identify which mitigation strategies are structurally promising, and we use it to propose a kernel-informed intervention.
DatedGPT: Preventing Lookahead Bias in Large Language Models with Time-Aware Pretraining
Mar 12, 2026In financial backtesting, large language models pretrained on internet-scale data risk introducing lookahead bias that undermines their forecasting validity, as they may have already seen the true outcome during training. To address this, we present DatedGPT, a family of twelve 1.3B-parameter language models, each trained from scratch on approximately 100 billion tokens of temporally partitioned data with strict annual cutoffs spanning 2013 to 2024. We further enhance each model with instruction fine-tuning on both general-domain and finance-specific datasets curated to respect the same temporal boundaries. Perplexity-based probing confirms that each model's knowledge is effectively bounded by its data cutoff year, while evaluation on standard benchmarks shows competitive performance with existing models of similar scale. We provide an interactive web demo that allows users to query and compare responses from models across different cutoff years.
The Role of Mixed-Language Documents for Multilingual Large Language Model Pretraining
Jan 01, 2026Multilingual large language models achieve impressive cross-lingual performance despite largely monolingual pretraining. While bilingual data in pretraining corpora is widely believed to enable these abilities, details of its contributions remain unclear. We investigate this question by pretraining models from scratch under controlled conditions, comparing the standard web corpus with a monolingual-only version that removes all multilingual documents. Despite constituting only 2% of the corpus, removing bilingual data causes translation performance to drop 56% in BLEU, while behaviour on cross-lingual QA and general reasoning tasks remains stable, with training curves largely overlapping the baseline. To understand this asymmetry, we categorize bilingual data into parallel (14%), code-switching (72%), and miscellaneous documents (14%) based on the semantic relevance of content in different languages. We then conduct granular ablations by reintroducing parallel or code-switching data into the monolingual-only corpus. Our experiments reveal that parallel data almost fully restores translation performance (91% of the unfiltered baseline), whereas code-switching contributes minimally. Other cross-lingual tasks remain largely unaffected by either type. These findings reveal that translation critically depends on systematic token-level alignments from parallel data, whereas cross-lingual understanding and reasoning appear to be achievable even without bilingual data.
Drawing Conclusions from Draws: Rethinking Preference Semantics in Arena-Style LLM Evaluation
Oct 02, 2025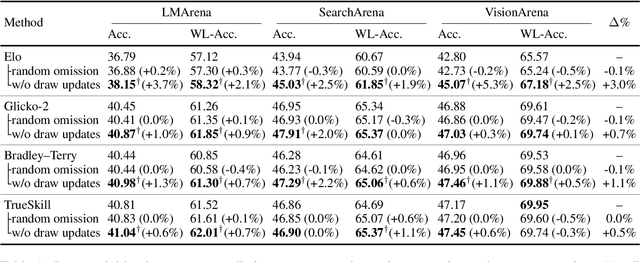
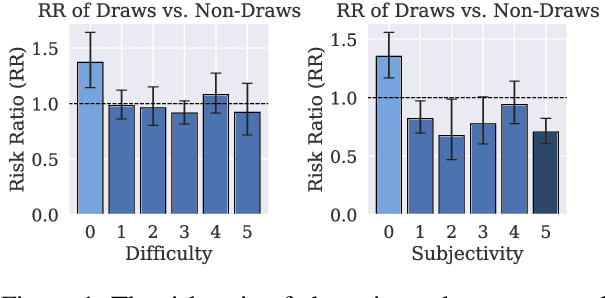
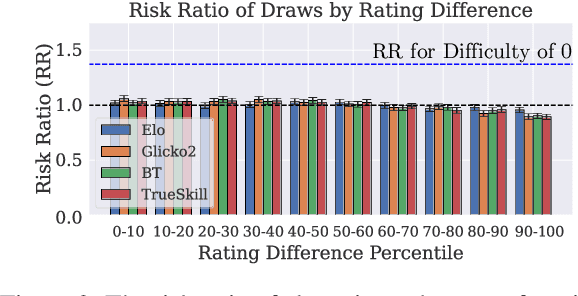
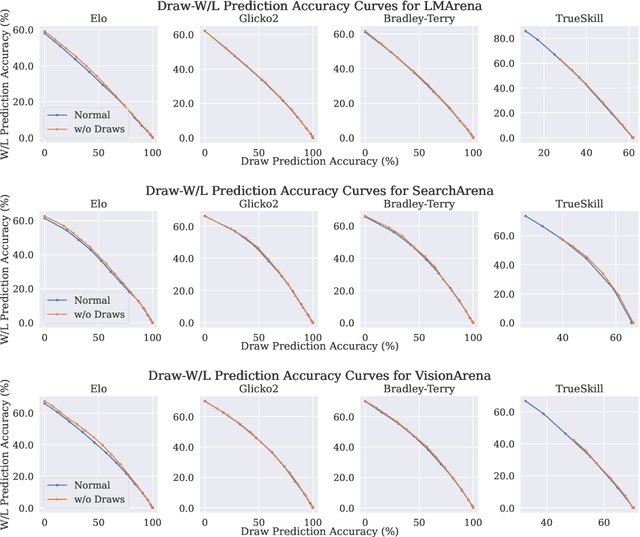
In arena-style evaluation of large language models (LLMs), two LLMs respond to a user query, and the user chooses the winning response or deems the "battle" a draw, resulting in an adjustment to the ratings of both models. The prevailing approach for modeling these rating dynamics is to view battles as two-player game matches, as in chess, and apply the Elo rating system and its derivatives. In this paper, we critically examine this paradigm. Specifically, we question whether a draw genuinely means that the two models are equal and hence whether their ratings should be equalized. Instead, we conjecture that draws are more indicative of query difficulty: if the query is too easy, then both models are more likely to succeed equally. On three real-world arena datasets, we show that ignoring rating updates for draws yields a 1-3% relative increase in battle outcome prediction accuracy (which includes draws) for all four rating systems studied. Further analyses suggest that draws occur more for queries rated as very easy and those as highly objective, with risk ratios of 1.37 and 1.35, respectively. We recommend future rating systems to reconsider existing draw semantics and to account for query properties in rating updates.
Multilingual Language Model Pretraining using Machine-translated Data
Feb 18, 2025High-resource languages such as English, enables the pretraining of high-quality large language models (LLMs). The same can not be said for most other languages as LLMs still underperform for non-English languages, likely due to a gap in the quality and diversity of the available multilingual pretraining corpora. In this work, we find that machine-translated texts from a single high-quality source language can contribute significantly to the pretraining quality of multilingual LLMs. We translate FineWeb-Edu, a high-quality English web dataset, into nine languages, resulting in a 1.7-trillion-token dataset, which we call TransWebEdu and pretrain a 1.3B-parameter model, TransWebLLM, from scratch on this dataset. Across nine non-English reasoning tasks, we show that TransWebLLM matches or outperforms state-of-the-art multilingual models trained using closed data, such as Llama3.2, Qwen2.5, and Gemma, despite using an order of magnitude less data. We demonstrate that adding less than 5% of TransWebEdu as domain-specific pretraining data sets a new state-of-the-art in Arabic, Italian, Indonesian, Swahili, and Welsh understanding and commonsense reasoning tasks. To promote reproducibility, we release our corpus, models, and training pipeline under Open Source Initiative-approved licenses.
Multilingual Pretraining Using a Large Corpus Machine-Translated from a Single Source Language
Oct 31, 2024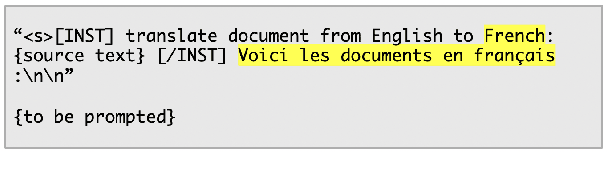
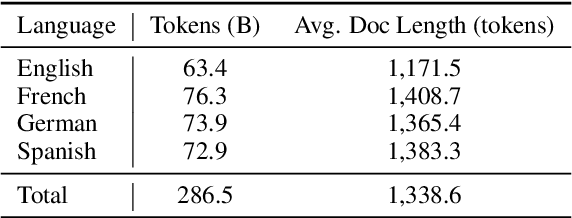
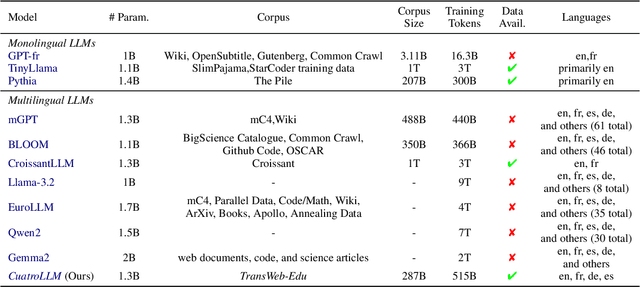
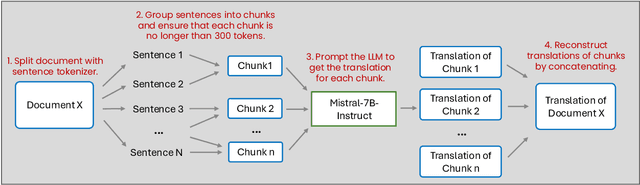
English, as a very high-resource language, enables the pretraining of high-quality large language models (LLMs). The same cannot be said for most other languages, as leading LLMs still underperform for non-English languages, likely due to a gap in the quality and diversity of the available multilingual pretraining corpora. In this work, we find that machine-translated text from a single high-quality source language can contribute significantly to the pretraining of multilingual LLMs. We translate FineWeb-Edu, a high-quality English web dataset, into French, German, and Spanish, resulting in a final 300B-token dataset, which we call TransWeb-Edu, and pretrain a 1.3B-parameter model, CuatroLLM, from scratch on this dataset. Across five non-English reasoning tasks, we show that CuatroLLM matches or outperforms state-of-the-art multilingual models trained using closed data, such as Llama3.2 and Gemma2, despite using an order of magnitude less data, such as about 6% of the tokens used for Llama3.2's training. We further demonstrate that with additional domain-specific pretraining, amounting to less than 1% of TransWeb-Edu, CuatroLLM surpasses the state of the art in multilingual reasoning. To promote reproducibility, we release our corpus, models, and training pipeline under open licenses at hf.co/britllm/CuatroLLM.
FoodieQA: A Multimodal Dataset for Fine-Grained Understanding of Chinese Food Culture
Jun 16, 2024



Food is a rich and varied dimension of cultural heritage, crucial to both individuals and social groups. To bridge the gap in the literature on the often-overlooked regional diversity in this domain, we introduce FoodieQA, a manually curated, fine-grained image-text dataset capturing the intricate features of food cultures across various regions in China. We evaluate vision-language Models (VLMs) and large language models (LLMs) on newly collected, unseen food images and corresponding questions. FoodieQA comprises three multiple-choice question-answering tasks where models need to answer questions based on multiple images, a single image, and text-only descriptions, respectively. While LLMs excel at text-based question answering, surpassing human accuracy, the open-sourced VLMs still fall short by 41\% on multi-image and 21\% on single-image VQA tasks, although closed-weights models perform closer to human levels (within 10\%). Our findings highlight that understanding food and its cultural implications remains a challenging and under-explored direction.
Words Worth a Thousand Pictures: Measuring and Understanding Perceptual Variability in Text-to-Image Generation
Jun 12, 2024



Diffusion models are the state of the art in text-to-image generation, but their perceptual variability remains understudied. In this paper, we examine how prompts affect image variability in black-box diffusion-based models. We propose W1KP, a human-calibrated measure of variability in a set of images, bootstrapped from existing image-pair perceptual distances. Current datasets do not cover recent diffusion models, thus we curate three test sets for evaluation. Our best perceptual distance outperforms nine baselines by up to 18 points in accuracy, and our calibration matches graded human judgements 78% of the time. Using W1KP, we study prompt reusability and show that Imagen prompts can be reused for 10-50 random seeds before new images become too similar to already generated images, while Stable Diffusion XL and DALL-E 3 can be reused 50-200 times. Lastly, we analyze 56 linguistic features of real prompts, finding that the prompt's length, CLIP embedding norm, concreteness, and word senses influence variability most. As far as we are aware, we are the first to analyze diffusion variability from a visuolinguistic perspective. Our project page is at http://w1kp.com
Understanding Retrieval Robustness for Retrieval-Augmented Image Captioning
Jun 04, 2024



Recent advancements in retrieval-augmented models for image captioning highlight the significance of retrieving related captions for efficient, lightweight models with strong domain-transfer capabilities. While these models demonstrate the success of retrieval augmentation, retrieval models are still far from perfect in practice. Retrieved information can sometimes mislead the model generation, negatively impacting performance. In this paper, we analyze the robustness of the SmallCap retrieval-augmented captioning model. Our analysis shows that SmallCap is sensitive to tokens that appear in the majority of the retrieved captions, and integrated gradients attribution shows that those tokens are likely copied into the final caption. Given these findings, we propose to train the model by sampling retrieved captions from more diverse sets. This reduces the probability that the model learns to copy majority tokens and improves both in-domain and cross-domain performance effectively.
"Ask Me Anything": How Comcast Uses LLMs to Assist Agents in Real Time
May 01, 2024



Customer service is how companies interface with their customers. It can contribute heavily towards the overall customer satisfaction. However, high-quality service can become expensive, creating an incentive to make it as cost efficient as possible and prompting most companies to utilize AI-powered assistants, or "chat bots". On the other hand, human-to-human interaction is still desired by customers, especially when it comes to complex scenarios such as disputes and sensitive topics like bill payment. This raises the bar for customer service agents. They need to accurately understand the customer's question or concern, identify a solution that is acceptable yet feasible (and within the company's policy), all while handling multiple conversations at once. In this work, we introduce "Ask Me Anything" (AMA) as an add-on feature to an agent-facing customer service interface. AMA allows agents to ask questions to a large language model (LLM) on demand, as they are handling customer conversations -- the LLM provides accurate responses in real-time, reducing the amount of context switching the agent needs. In our internal experiments, we find that agents using AMA versus a traditional search experience spend approximately 10% fewer seconds per conversation containing a search, translating to millions of dollars of savings annually. Agents that used the AMA feature provided positive feedback nearly 80% of the time, demonstrating its usefulness as an AI-assisted feature for customer care.