 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat do your logits know? (The answer may surprise you!)
Apr 10, 2026Recent work has shown that probing model internals can reveal a wealth of information not apparent from the model generations. This poses the risk of unintentional or malicious information leakage, where model users are able to learn information that the model owner assumed was inaccessible. Using vision-language models as a testbed, we present the first systematic comparison of information retained at different "representational levels'' as it is compressed from the rich information encoded in the residual stream through two natural bottlenecks: low-dimensional projections of the residual stream obtained using tuned lens, and the final top-k logits most likely to impact model's answer. We show that even easily accessible bottlenecks defined by the model's top logit values can leak task-irrelevant information present in an image-based query, in some cases revealing as much information as direct projections of the full residual stream.
CONCAP: Seeing Beyond English with Concepts Retrieval-Augmented Captioning
Jul 27, 2025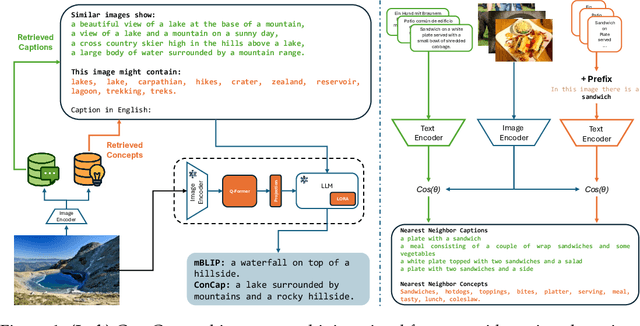
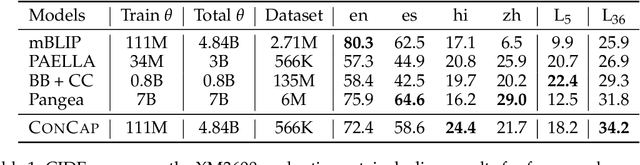
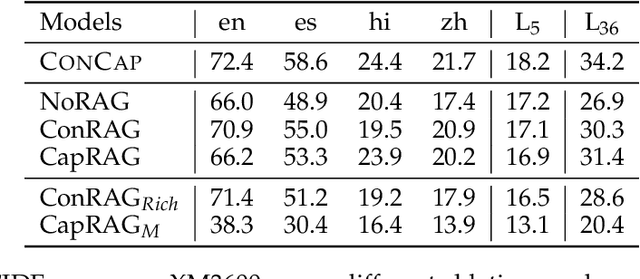
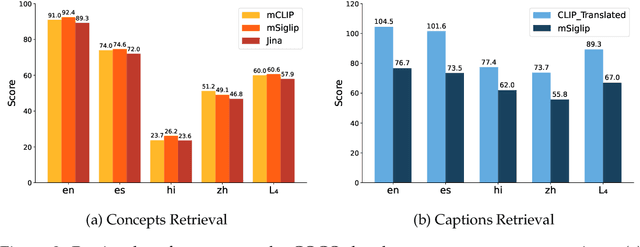
Multilingual vision-language models have made significant strides in image captioning, yet they still lag behind their English counterparts due to limited multilingual training data and costly large-scale model parameterization. Retrieval-augmented generation (RAG) offers a promising alternative by conditioning caption generation on retrieved examples in the target language, reducing the need for extensive multilingual training. However, multilingual RAG captioning models often depend on retrieved captions translated from English, which can introduce mismatches and linguistic biases relative to the source language. We introduce CONCAP, a multilingual image captioning model that integrates retrieved captions with image-specific concepts, enhancing the contextualization of the input image and grounding the captioning process across different languages. Experiments on the XM3600 dataset indicate that CONCAP enables strong performance on low- and mid-resource languages, with highly reduced data requirements. Our findings highlight the effectiveness of concept-aware retrieval augmentation in bridging multilingual performance gaps.
GrammaMT: Improving Machine Translation with Grammar-Informed In-Context Learning
Oct 24, 2024We introduce GrammaMT, a grammatically-aware prompting approach for machine translation that uses Interlinear Glossed Text (IGT), a common form of linguistic description providing morphological and lexical annotations for source sentences. GrammaMT proposes three prompting strategies: gloss-shot, chain-gloss and model-gloss. All are training-free, requiring only a few examples that involve minimal effort to collect, and making them well-suited for low-resource setups. Experiments show that GrammaMT enhances translation performance on open-source instruction-tuned LLMs for various low- to high-resource languages across three benchmarks: (1) the largest IGT corpus, (2) the challenging 2023 SIGMORPHON Shared Task data over endangered languages, and (3) even in an out-of-domain setting with FLORES. Moreover, ablation studies reveal that leveraging gloss resources could substantially boost MT performance (by over 17 BLEU points) if LLMs accurately generate or access input sentence glosses.
Understanding Retrieval Robustness for Retrieval-Augmented Image Captioning
Jun 04, 2024



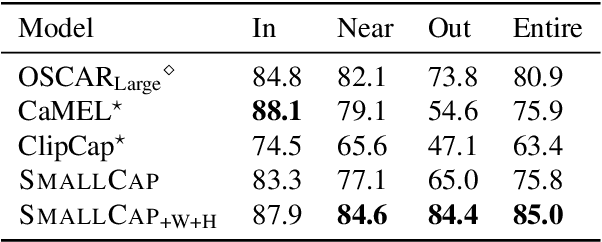
Recent advancements in retrieval-augmented models for image captioning highlight the significance of retrieving related captions for efficient, lightweight models with strong domain-transfer capabilities. While these models demonstrate the success of retrieval augmentation, retrieval models are still far from perfect in practice. Retrieved information can sometimes mislead the model generation, negatively impacting performance. In this paper, we analyze the robustness of the SmallCap retrieval-augmented captioning model. Our analysis shows that SmallCap is sensitive to tokens that appear in the majority of the retrieved captions, and integrated gradients attribution shows that those tokens are likely copied into the final caption. Given these findings, we propose to train the model by sampling retrieved captions from more diverse sets. This reduces the probability that the model learns to copy majority tokens and improves both in-domain and cross-domain performance effectively.
LMCap: Few-shot Multilingual Image Captioning by Retrieval Augmented Language Model Prompting
May 31, 2023



Multilingual image captioning has recently been tackled by training with large-scale machine translated data, which is an expensive, noisy, and time-consuming process. Without requiring any multilingual caption data, we propose LMCap, an image-blind few-shot multilingual captioning model that works by prompting a language model with retrieved captions. Specifically, instead of following the standard encoder-decoder paradigm, given an image, LMCap first retrieves the captions of similar images using a multilingual CLIP encoder. These captions are then combined into a prompt for an XGLM decoder, in order to generate captions in the desired language. In other words, the generation model does not directly process the image, instead processing retrieved captions. Experiments on the XM3600 dataset of geographically diverse images show that our model is competitive with fully-supervised multilingual captioning models, without requiring any supervised training on any captioning data.
Retrieval-augmented Image Captioning
Feb 16, 2023Inspired by retrieval-augmented language generation and pretrained Vision and Language (V&L) encoders, we present a new approach to image captioning that generates sentences given the input image and a set of captions retrieved from a datastore, as opposed to the image alone. The encoder in our model jointly processes the image and retrieved captions using a pretrained V&L BERT, while the decoder attends to the multimodal encoder representations, benefiting from the extra textual evidence from the retrieved captions. Experimental results on the COCO dataset show that image captioning can be effectively formulated from this new perspective. Our model, named EXTRA, benefits from using captions retrieved from the training dataset, and it can also benefit from using an external dataset without the need for retraining. Ablation studies show that retrieving a sufficient number of captions (e.g., k=5) can improve captioning quality. Our work contributes towards using pretrained V&L encoders for generative tasks, instead of standard classification tasks.
SmallCap: Lightweight Image Captioning Prompted with Retrieval Augmentation
Sep 30, 2022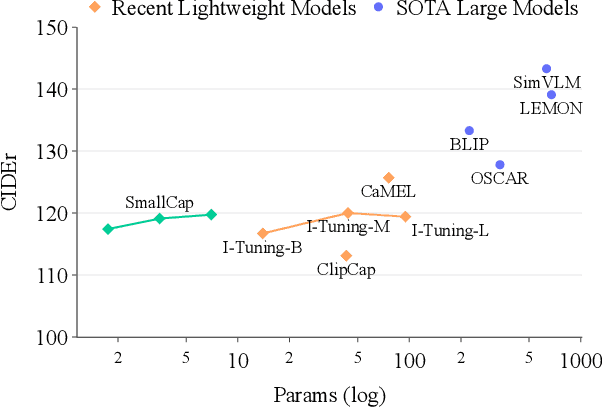
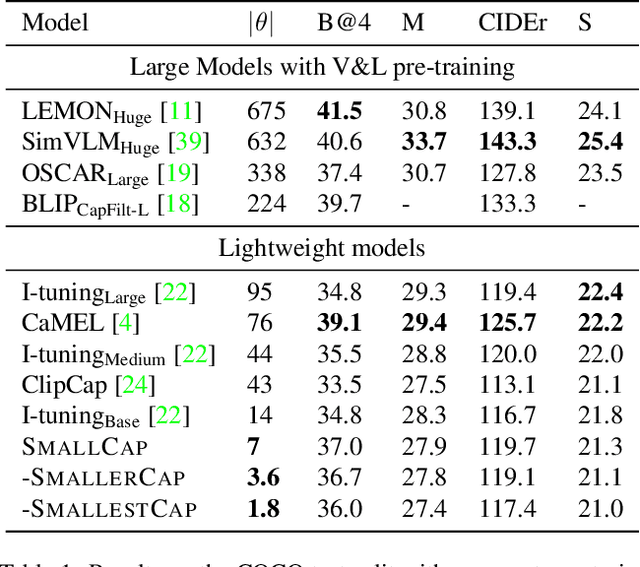
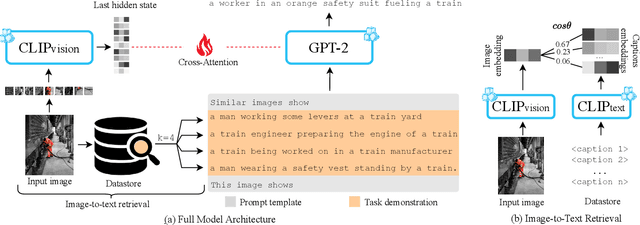
Recent advances in image captioning have focused on scaling the data and model size, substantially increasing the cost of pre-training and finetuning. As an alternative to large models, we present SmallCap, which generates a caption conditioned on an input image and related captions retrieved from a datastore. Our model is lightweight and fast to train as the only learned parameters are in newly introduced cross-attention layers between a pre-trained CLIP encoder and GPT-2 decoder. SmallCap can transfer to new domains without additional finetuning and exploit large-scale data in a training-free fashion because the contents of the datastore can be readily replaced. Our experiments show that SmallCap, trained only on COCO, has competitive performance on this benchmark, and also transfers to other domains without retraining, solely through retrieval from target-domain data. Further improvement is achieved through the training-free exploitation of diverse human-labeled and web data, which proves effective for other domains, including the nocaps image captioning benchmark, designed to test generalization to unseen visual concepts.