 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpAlign: Expectation-Guided Vision-Language Alignment for Open-Vocabulary Grounding
Jan 30, 2026Open-vocabulary grounding requires accurate vision-language alignment under weak supervision, yet existing methods either rely on global sentence embeddings that lack fine-grained expressiveness or introduce token-level alignment with explicit supervision or heavy cross-attention designs. We propose ExpAlign, a theoretically grounded vision-language alignment framework built on a principled multiple instance learning formulation. ExpAlign introduces an Expectation Alignment Head that performs attention-based soft MIL pooling over token-region similarities, enabling implicit token and instance selection without additional annotations. To further stabilize alignment learning, we develop an energy-based multi-scale consistency regularization scheme, including a Top-K multi-positive contrastive objective and a Geometry-Aware Consistency Objective derived from a Lagrangian-constrained free-energy minimization. Extensive experiments show that ExpAlign consistently improves open-vocabulary detection and zero-shot instance segmentation, particularly on long-tail categories. Most notably, it achieves 36.2 AP$_r$ on the LVIS minival split, outperforming other state-of-the-art methods at comparable model scale, while remaining lightweight and inference-efficient.
Drawing Conclusions from Draws: Rethinking Preference Semantics in Arena-Style LLM Evaluation
Oct 02, 2025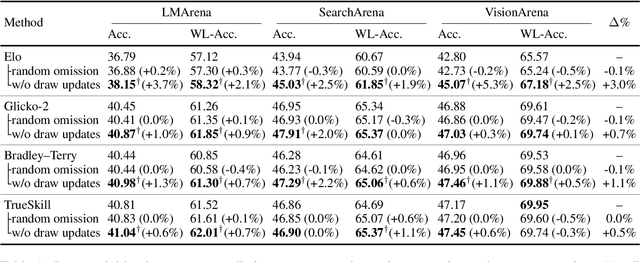
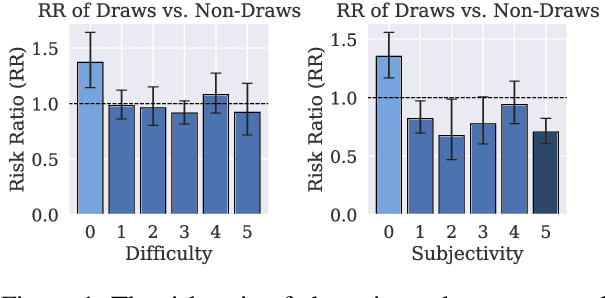
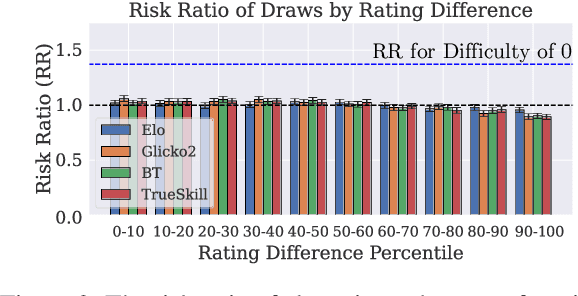
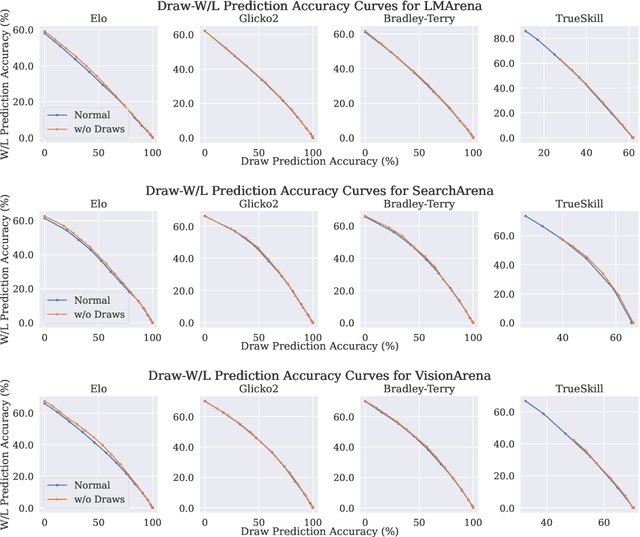
In arena-style evaluation of large language models (LLMs), two LLMs respond to a user query, and the user chooses the winning response or deems the "battle" a draw, resulting in an adjustment to the ratings of both models. The prevailing approach for modeling these rating dynamics is to view battles as two-player game matches, as in chess, and apply the Elo rating system and its derivatives. In this paper, we critically examine this paradigm. Specifically, we question whether a draw genuinely means that the two models are equal and hence whether their ratings should be equalized. Instead, we conjecture that draws are more indicative of query difficulty: if the query is too easy, then both models are more likely to succeed equally. On three real-world arena datasets, we show that ignoring rating updates for draws yields a 1-3% relative increase in battle outcome prediction accuracy (which includes draws) for all four rating systems studied. Further analyses suggest that draws occur more for queries rated as very easy and those as highly objective, with risk ratios of 1.37 and 1.35, respectively. We recommend future rating systems to reconsider existing draw semantics and to account for query properties in rating updates.
CultureCLIP: Empowering CLIP with Cultural Awareness through Synthetic Images and Contextualized Captions
Jul 08, 2025Pretrained vision-language models (VLMs) such as CLIP excel in multimodal understanding but struggle with contextually relevant fine-grained visual features, making it difficult to distinguish visually similar yet culturally distinct concepts. This limitation stems from the scarcity of high-quality culture-specific datasets, the lack of integrated contextual knowledge, and the absence of hard negatives highlighting subtle distinctions. To address these challenges, we first design a data curation pipeline that leverages open-sourced VLMs and text-to-image diffusion models to construct CulTwin, a synthetic cultural dataset. This dataset consists of paired concept-caption-image triplets, where concepts visually resemble each other but represent different cultural contexts. Then, we fine-tune CLIP on CulTwin to create CultureCLIP, which aligns cultural concepts with contextually enhanced captions and synthetic images through customized contrastive learning, enabling finer cultural differentiation while preserving generalization capabilities. Experiments on culturally relevant benchmarks show that CultureCLIP outperforms the base CLIP, achieving up to a notable 5.49% improvement in fine-grained concept recognition on certain tasks, while preserving CLIP's original generalization ability, validating the effectiveness of our data synthesis and VLM backbone training paradigm in capturing subtle cultural distinctions.
RAVENEA: A Benchmark for Multimodal Retrieval-Augmented Visual Culture Understanding
May 20, 2025As vision-language models (VLMs) become increasingly integrated into daily life, the need for accurate visual culture understanding is becoming critical. Yet, these models frequently fall short in interpreting cultural nuances effectively. Prior work has demonstrated the effectiveness of retrieval-augmented generation (RAG) in enhancing cultural understanding in text-only settings, while its application in multimodal scenarios remains underexplored. To bridge this gap, we introduce RAVENEA (Retrieval-Augmented Visual culturE uNdErstAnding), a new benchmark designed to advance visual culture understanding through retrieval, focusing on two tasks: culture-focused visual question answering (cVQA) and culture-informed image captioning (cIC). RAVENEA extends existing datasets by integrating over 10,000 Wikipedia documents curated and ranked by human annotators. With RAVENEA, we train and evaluate seven multimodal retrievers for each image query, and measure the downstream impact of retrieval-augmented inputs across fourteen state-of-the-art VLMs. Our results show that lightweight VLMs, when augmented with culture-aware retrieval, outperform their non-augmented counterparts (by at least 3.2% absolute on cVQA and 6.2% absolute on cIC). This highlights the value of retrieval-augmented methods and culturally inclusive benchmarks for multimodal understanding.
FoodieQA: A Multimodal Dataset for Fine-Grained Understanding of Chinese Food Culture
Jun 16, 2024



Food is a rich and varied dimension of cultural heritage, crucial to both individuals and social groups. To bridge the gap in the literature on the often-overlooked regional diversity in this domain, we introduce FoodieQA, a manually curated, fine-grained image-text dataset capturing the intricate features of food cultures across various regions in China. We evaluate vision-language Models (VLMs) and large language models (LLMs) on newly collected, unseen food images and corresponding questions. FoodieQA comprises three multiple-choice question-answering tasks where models need to answer questions based on multiple images, a single image, and text-only descriptions, respectively. While LLMs excel at text-based question answering, surpassing human accuracy, the open-sourced VLMs still fall short by 41\% on multi-image and 21\% on single-image VQA tasks, although closed-weights models perform closer to human levels (within 10\%). Our findings highlight that understanding food and its cultural implications remains a challenging and under-explored direction.
Words Worth a Thousand Pictures: Measuring and Understanding Perceptual Variability in Text-to-Image Generation
Jun 12, 2024



Diffusion models are the state of the art in text-to-image generation, but their perceptual variability remains understudied. In this paper, we examine how prompts affect image variability in black-box diffusion-based models. We propose W1KP, a human-calibrated measure of variability in a set of images, bootstrapped from existing image-pair perceptual distances. Current datasets do not cover recent diffusion models, thus we curate three test sets for evaluation. Our best perceptual distance outperforms nine baselines by up to 18 points in accuracy, and our calibration matches graded human judgements 78% of the time. Using W1KP, we study prompt reusability and show that Imagen prompts can be reused for 10-50 random seeds before new images become too similar to already generated images, while Stable Diffusion XL and DALL-E 3 can be reused 50-200 times. Lastly, we analyze 56 linguistic features of real prompts, finding that the prompt's length, CLIP embedding norm, concreteness, and word senses influence variability most. As far as we are aware, we are the first to analyze diffusion variability from a visuolinguistic perspective. Our project page is at http://w1kp.com
Understanding Retrieval Robustness for Retrieval-Augmented Image Captioning
Jun 04, 2024



Recent advancements in retrieval-augmented models for image captioning highlight the significance of retrieving related captions for efficient, lightweight models with strong domain-transfer capabilities. While these models demonstrate the success of retrieval augmentation, retrieval models are still far from perfect in practice. Retrieved information can sometimes mislead the model generation, negatively impacting performance. In this paper, we analyze the robustness of the SmallCap retrieval-augmented captioning model. Our analysis shows that SmallCap is sensitive to tokens that appear in the majority of the retrieved captions, and integrated gradients attribution shows that those tokens are likely copied into the final caption. Given these findings, we propose to train the model by sampling retrieved captions from more diverse sets. This reduces the probability that the model learns to copy majority tokens and improves both in-domain and cross-domain performance effectively.
Exploring Visual Culture Awareness in GPT-4V: A Comprehensive Probing
Feb 15, 2024Pretrained large Vision-Language models have drawn considerable interest in recent years due to their remarkable performance. Despite considerable efforts to assess these models from diverse perspectives, the extent of visual cultural awareness in the state-of-the-art GPT-4V model remains unexplored. To tackle this gap, we extensively probed GPT-4V using the MaRVL benchmark dataset, aiming to investigate its capabilities and limitations in visual understanding with a focus on cultural aspects. Specifically, we introduced three visual related tasks, i.e. caption classification, pairwise captioning, and culture tag selection, to systematically delve into fine-grained visual cultural evaluation. Experimental results indicate that GPT-4V excels at identifying cultural concepts but still exhibits weaker performance in low-resource languages, such as Tamil and Swahili. Notably, through human evaluation, GPT-4V proves to be more culturally relevant in image captioning tasks than the original MaRVL human annotations, suggesting a promising solution for future visual cultural benchmark construction.
Data Curation for Image Captioning with Text-to-Image Generative Models
May 05, 2023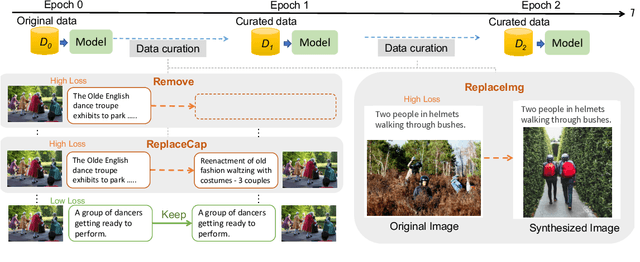
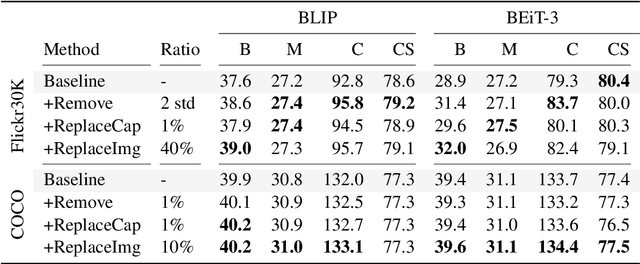

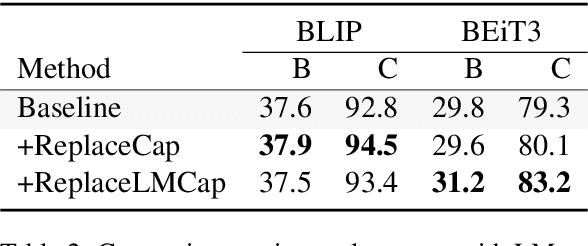
Recent advances in image captioning are mainly driven by large-scale vision-language pretraining, relying heavily on computational resources and increasingly large multimodal datasets. Instead of scaling up pretraining data, we ask whether it is possible to improve performance by improving the quality of the samples in existing datasets. We pursue this question through two approaches to data curation: one that assumes that some examples should be avoided due to mismatches between the image and caption, and one that assumes that the mismatch can be addressed by replacing the image, for which we use the state-of-the-art Stable Diffusion model. These approaches are evaluated using the BLIP model on MS COCO and Flickr30K in both finetuning and few-shot learning settings. Our simple yet effective approaches consistently outperform baselines, indicating that better image captioning models can be trained by curating existing resources. Finally, we conduct a human study to understand the errors made by the Stable Diffusion model and highlight directions for future work in text-to-image generation.